 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Keyphrase Extraction from Long Scientific Documents using Graph Embeddings
May 16, 2023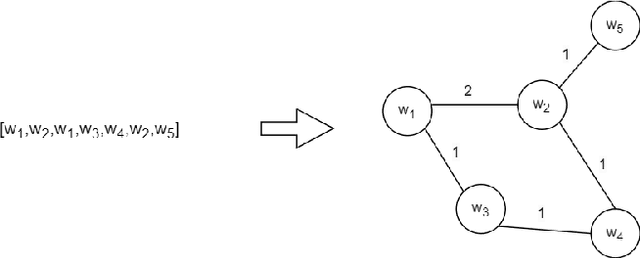

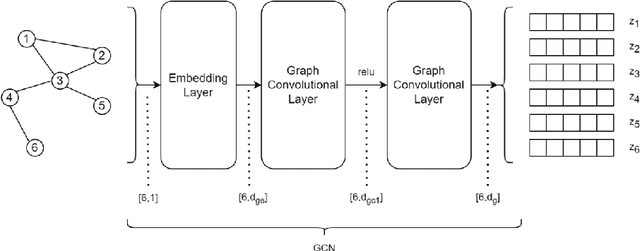

In this study, we investigate using graph neural network (GNN) representations to enhance contextualized representations of pre-trained language models (PLMs) for keyphrase extraction from lengthy documents. We show that augmenting a PLM with graph embeddings provides a more comprehensive semantic understanding of words in a document, particularly for long documents. We construct a co-occurrence graph of the text and embed it using a graph convolutional network (GCN) trained on the task of edge prediction. We propose a graph-enhanced sequence tagging architecture that augments contextualized PLM embeddings with graph representations. Evaluating on benchmark datasets, we demonstrate that enhancing PLMs with graph embeddings outperforms state-of-the-art models on long documents, showing significant improvements in F1 scores across all the datasets. Our study highlights the potential of GNN representations as a complementary approach to improve PLM performance for keyphrase extraction from long documents.
Metric Tools for Sensitivity Analysis with Applications to Neural Networks
May 03, 2023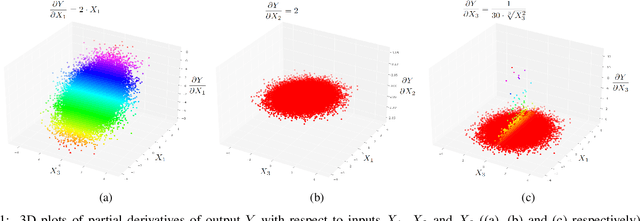
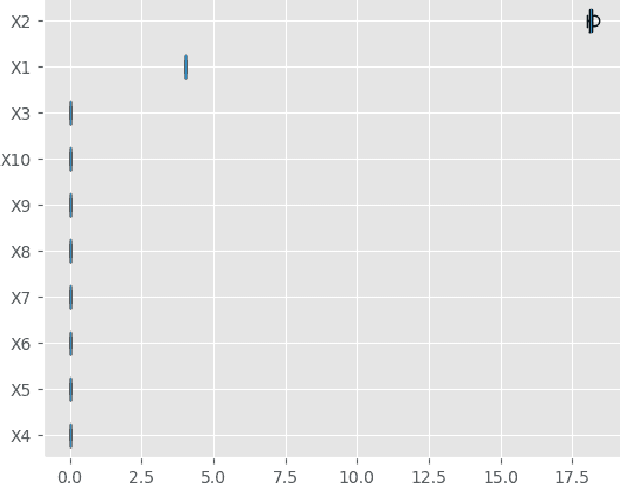
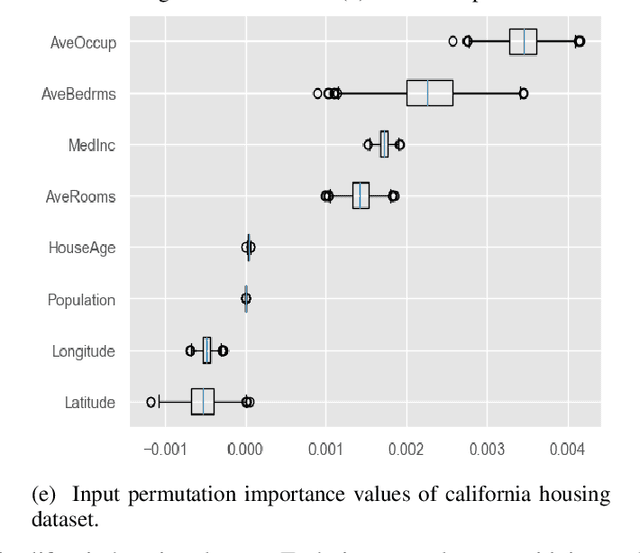
As Machine Learning models are considered for autonomous decisions with significant social impact, the need for understanding how these models work rises rapidly. Explainable Artificial Intelligence (XAI) aims to provide interpretations for predictions made by Machine Learning models, in order to make the model trustworthy and more transparent for the user. For example, selecting relevant input variables for the problem directly impacts the model's ability to learn and make accurate predictions, so obtaining information about input importance play a crucial role when training the model. One of the main XAI techniques to obtain input variable importance is the sensitivity analysis based on partial derivatives. However, existing literature of this method provide no justification of the aggregation metrics used to retrieved information from the partial derivatives. In this paper, a theoretical framework is proposed to study sensitivities of ML models using metric techniques. From this metric interpretation, a complete family of new quantitative metrics called $\alpha$-curves is extracted. These $\alpha$-curves provide information with greater depth on the importance of the input variables for a machine learning model than existing XAI methods in the literature. We demonstrate the effectiveness of the $\alpha$-curves using synthetic and real datasets, comparing the results against other XAI methods for variable importance and validating the analysis results with the ground truth or literature information.
ChatGPT vs State-of-the-Art Models: A Benchmarking Study in Keyphrase Generation Task
Apr 27, 2023



Transformer-based language models, including ChatGPT, have demonstrated exceptional performance in various natural language generation tasks. However, there has been limited research evaluating ChatGPT's keyphrase generation ability, which involves identifying informative phrases that accurately reflect a document's content. This study seeks to address this gap by comparing ChatGPT's keyphrase generation performance with state-of-the-art models, while also testing its potential as a solution for two significant challenges in the field: domain adaptation and keyphrase generation from long documents. We conducted experiments on six publicly available datasets from scientific articles and news domains, analyzing performance on both short and long documents. Our results show that ChatGPT outperforms current state-of-the-art models in all tested datasets and environments, generating high-quality keyphrases that adapt well to diverse domains and document lengths.