 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Keyphrase Extraction from Long Scientific Documents using Graph Embeddings
Paper and Code
May 16, 2023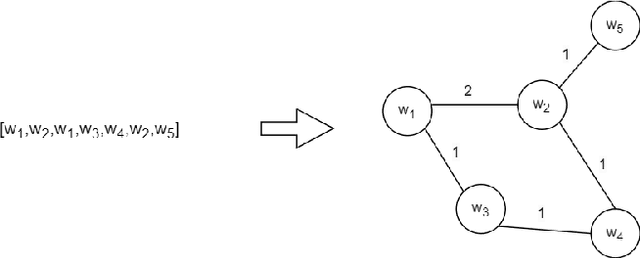

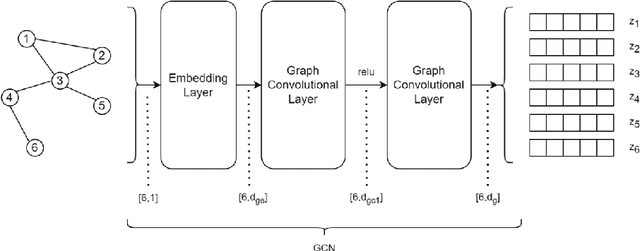

In this study, we investigate using graph neural network (GNN) representations to enhance contextualized representations of pre-trained language models (PLMs) for keyphrase extraction from lengthy documents. We show that augmenting a PLM with graph embeddings provides a more comprehensive semantic understanding of words in a document, particularly for long documents. We construct a co-occurrence graph of the text and embed it using a graph convolutional network (GCN) trained on the task of edge prediction. We propose a graph-enhanced sequence tagging architecture that augments contextualized PLM embeddings with graph representations. Evaluating on benchmark datasets, we demonstrate that enhancing PLMs with graph embeddings outperforms state-of-the-art models on long documents, showing significant improvements in F1 scores across all the datasets. Our study highlights the potential of GNN representations as a complementary approach to improve PLM performance for keyphrase extraction from long documents.