 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Expansion: Enhancing Keyphrase Extraction from Long Documents with Attention-Augmented Contextualized Embeddings
Jun 09, 2026Pre-trained language models (PLMs) have achieved strong performance in keyphrase extraction (KPE), largely due to their ability to generate rich contextualized representations. However, long-document KPE remains challenging because salient keyphrase evidence may be scattered across distant document sections that cannot be jointly captured within the limited context window of most PLMs. Although long-context large language models (LLMs) can process broader textual contexts, their computational cost limits their practicality for efficient and high-throughput KPE. To overcome this limitation, we propose an attention expansion mechanism that augments PLM token representations with information from surrounding out-of-context chunks using pre-trained word embeddings. The proposed mechanism expands the effective contextual scope of PLM-based KPE models without requiring full-document attention or expensive LLM-based inference. We evaluate our approach across five PLM backbones, including general-purpose, scientific, task-specific, and long-context encoders, using two training regimes and five benchmark corpora from scientific and news domains. Experimental results demonstrate that attention expansion consistently enhances KPE performance across all evaluation settings, outperforming state-of-the-art models and yielding notable improvements in F1 score. The improvements extend to domain-specific, task-specialized, and native long-context models, showing that the proposed mechanism provides complementary information rather than merely compensating for limited input length. These results establish attention expansion as an efficient and effective strategy for long-document KPE.
Enhancing Keyphrase Extraction from Long Scientific Documents using Graph Embeddings
May 16, 2023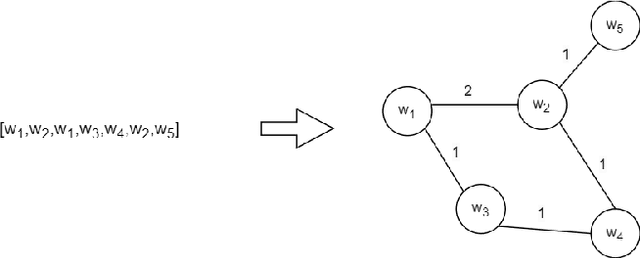

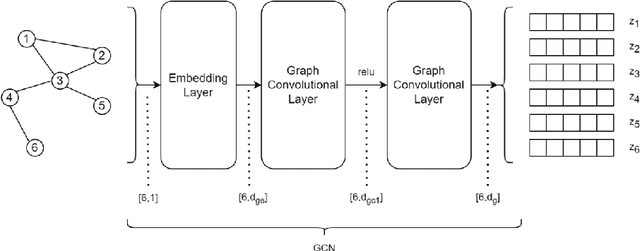

In this study, we investigate using graph neural network (GNN) representations to enhance contextualized representations of pre-trained language models (PLMs) for keyphrase extraction from lengthy documents. We show that augmenting a PLM with graph embeddings provides a more comprehensive semantic understanding of words in a document, particularly for long documents. We construct a co-occurrence graph of the text and embed it using a graph convolutional network (GCN) trained on the task of edge prediction. We propose a graph-enhanced sequence tagging architecture that augments contextualized PLM embeddings with graph representations. Evaluating on benchmark datasets, we demonstrate that enhancing PLMs with graph embeddings outperforms state-of-the-art models on long documents, showing significant improvements in F1 scores across all the datasets. Our study highlights the potential of GNN representations as a complementary approach to improve PLM performance for keyphrase extraction from long documents.
ChatGPT vs State-of-the-Art Models: A Benchmarking Study in Keyphrase Generation Task
Apr 27, 2023



Transformer-based language models, including ChatGPT, have demonstrated exceptional performance in various natural language generation tasks. However, there has been limited research evaluating ChatGPT's keyphrase generation ability, which involves identifying informative phrases that accurately reflect a document's content. This study seeks to address this gap by comparing ChatGPT's keyphrase generation performance with state-of-the-art models, while also testing its potential as a solution for two significant challenges in the field: domain adaptation and keyphrase generation from long documents. We conducted experiments on six publicly available datasets from scientific articles and news domains, analyzing performance on both short and long documents. Our results show that ChatGPT outperforms current state-of-the-art models in all tested datasets and environments, generating high-quality keyphrases that adapt well to diverse domains and document lengths.