 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Retrieval of Topics and Insights from Earnings Calls
Jul 10, 2025Tracking the strategic focus of companies through topics in their earnings calls is a key task in financial analysis. However, as industries evolve, traditional topic modeling techniques struggle to dynamically capture emerging topics and their relationships. In this work, we propose an LLM-agent driven approach to discover and retrieve emerging topics from quarterly earnings calls. We propose an LLM-agent to extract topics from documents, structure them into a hierarchical ontology, and establish relationships between new and existing topics through a topic ontology. We demonstrate the use of extracted topics to infer company-level insights and emerging trends over time. We evaluate our approach by measuring ontology coherence, topic evolution accuracy, and its ability to surface emerging financial trends.
Leveraging Contextual Information for Effective Entity Salience Detection
Sep 14, 2023
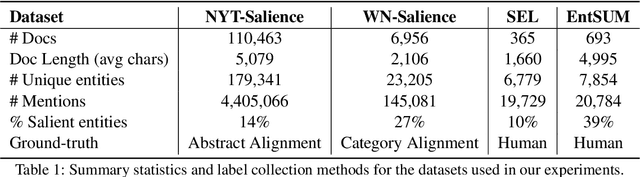
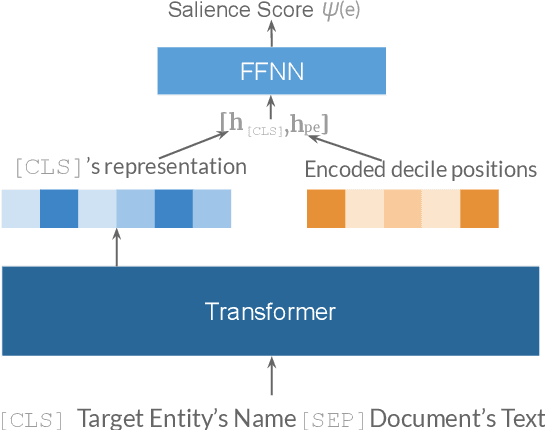
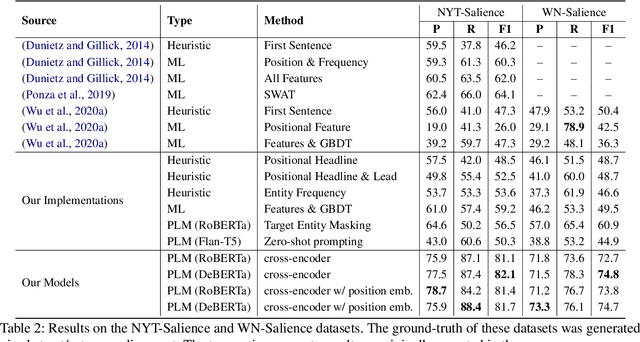
In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
Unsupervised Contrast-Consistent Ranking with Language Models
Sep 13, 2023

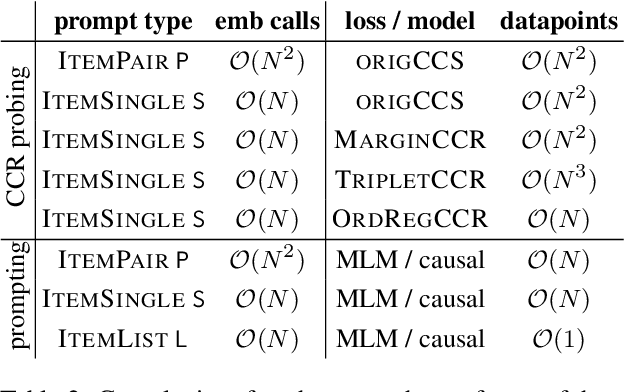
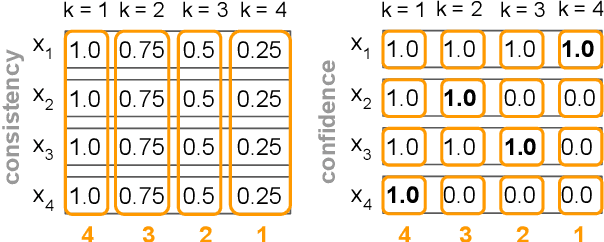
Language models contain ranking-based knowledge and are powerful solvers of in-context ranking tasks. For instance, they may have parametric knowledge about the ordering of countries by size or may be able to rank reviews by sentiment. Recent work focuses on pairwise, pointwise, and listwise prompting techniques to elicit a language model's ranking knowledge. However, we find that even with careful calibration and constrained decoding, prompting-based techniques may not always be self-consistent in the rankings they produce. This motivates us to explore an alternative approach that is inspired by an unsupervised probing method called Contrast-Consistent Search (CCS). The idea is to train a probing model guided by a logical constraint: a model's representation of a statement and its negation must be mapped to contrastive true-false poles consistently across multiple statements. We hypothesize that similar constraints apply to ranking tasks where all items are related via consistent pairwise or listwise comparisons. To this end, we extend the binary CCS method to Contrast-Consistent Ranking (CCR) by adapting existing ranking methods such as the Max-Margin Loss, Triplet Loss, and Ordinal Regression objective. Our results confirm that, for the same language model, CCR probing outperforms prompting and even performs on a par with prompting much larger language models.
Learning Rich Representation of Keyphrases from Text
Dec 16, 2021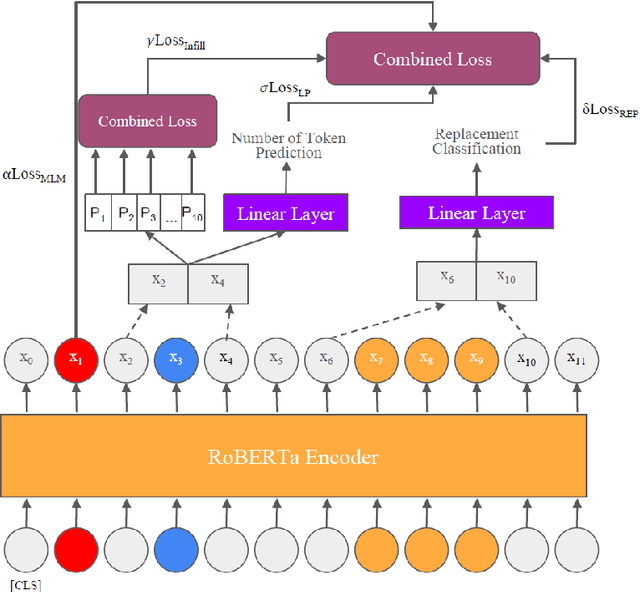

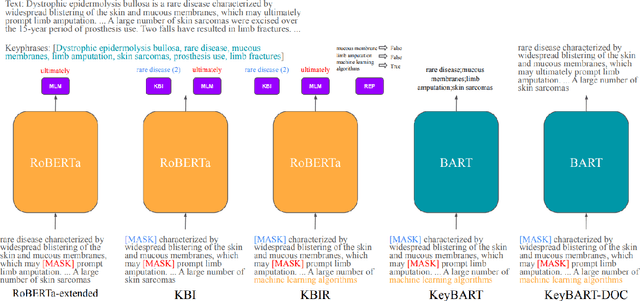
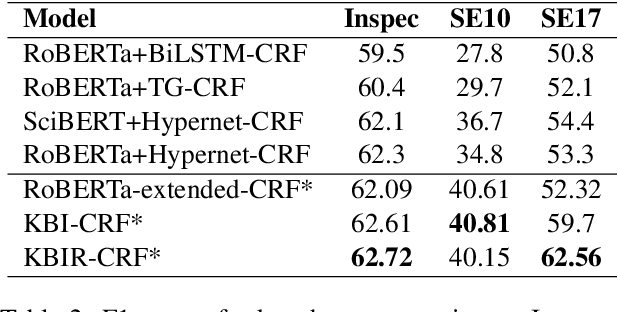
In this work, we explore how to learn task-specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (upto 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (upto 4.33 points in F1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition (NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks.
Fast and Effective Biomedical Entity Linking Using a Dual Encoder
Mar 08, 2021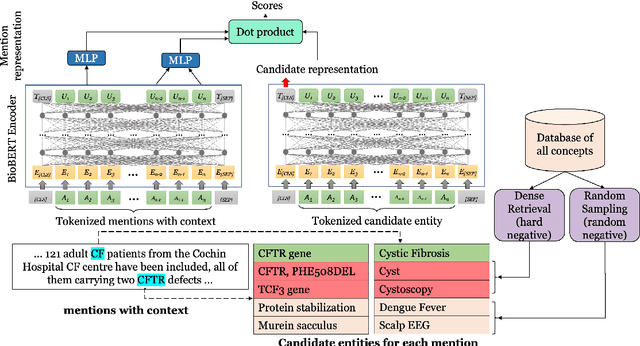

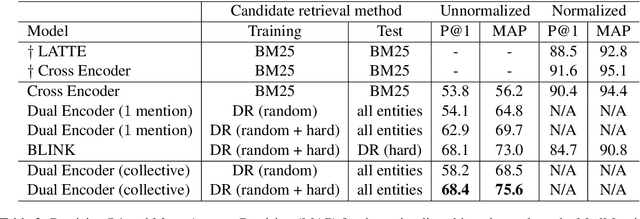
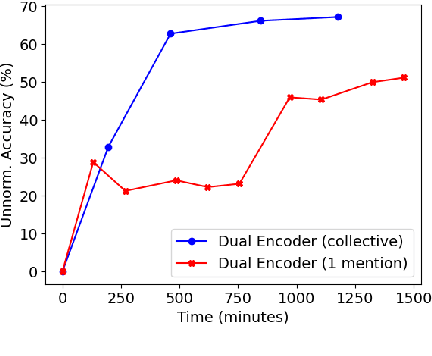
Biomedical entity linking is the task of identifying mentions of biomedical concepts in text documents and mapping them to canonical entities in a target thesaurus. Recent advancements in entity linking using BERT-based models follow a retrieve and rerank paradigm, where the candidate entities are first selected using a retriever model, and then the retrieved candidates are ranked by a reranker model. While this paradigm produces state-of-the-art results, they are slow both at training and test time as they can process only one mention at a time. To mitigate these issues, we propose a BERT-based dual encoder model that resolves multiple mentions in a document in one shot. We show that our proposed model is multiple times faster than existing BERT-based models while being competitive in accuracy for biomedical entity linking. Additionally, we modify our dual encoder model for end-to-end biomedical entity linking that performs both mention span detection and entity disambiguation and out-performs two recently proposed models.
A Joint Framework for Inductive Representation Learning and Explainable Reasoning in Knowledge Graphs
May 01, 2020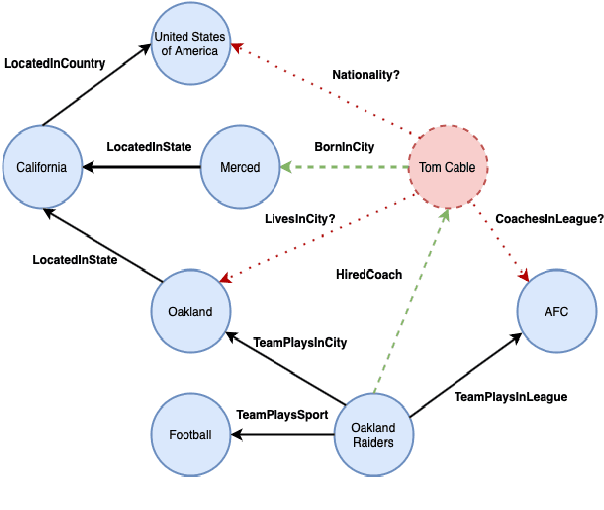
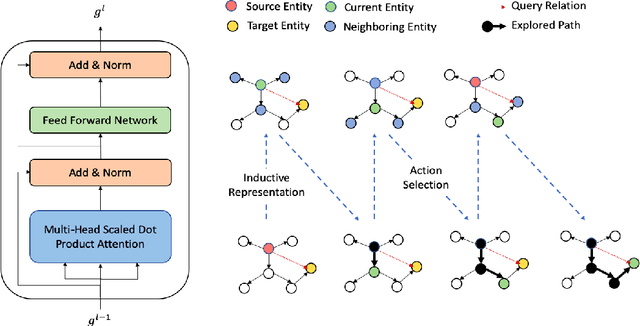

Despite their large-scale coverage, existing cross-domain knowledge graphs invariably suffer from inherent incompleteness and sparsity, necessitating link prediction that requires inferring a target entity, given a source entity and a query relation. Recent approaches can broadly be classified into two categories: embedding-based approaches and path-based approaches. In contrast to embedding-based approaches, which operate in an uninterpretable latent semantic vector space of entities and relations, path-based approaches operate in the symbolic space, making the inference process explainable. However, traditionally, these approaches are studied with static snapshots of the knowledge graphs, severely restricting their applicability for dynamic knowledge graphs with newly emerging entities. To overcome this issue, we propose an inductive representation learning framework that is able to learn representations of previously unseen entities. Our method finds reasoning paths between source and target entities, thereby making the link prediction for unseen entities interpretable and providing support evidence for the inferred link.
Be Concise and Precise: Synthesizing Open-Domain Entity Descriptions from Facts
Apr 16, 2019
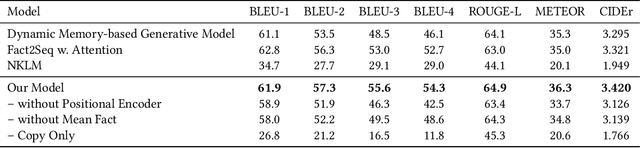
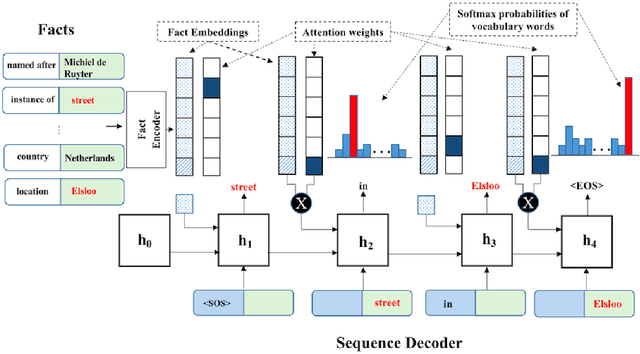

Despite being vast repositories of factual information, cross-domain knowledge graphs, such as Wikidata and the Google Knowledge Graph, only sparsely provide short synoptic descriptions for entities. Such descriptions that briefly identify the most discernible features of an entity provide readers with a near-instantaneous understanding of what kind of entity they are being presented. They can also aid in tasks such as named entity disambiguation, ontological type determination, and answering entity queries. Given the rapidly increasing numbers of entities in knowledge graphs, a fully automated synthesis of succinct textual descriptions from underlying factual information is essential. To this end, we propose a novel fact-to-sequence encoder-decoder model with a suitable copy mechanism to generate concise and precise textual descriptions of entities. In an in-depth evaluation, we demonstrate that our method significantly outperforms state-of-the-art alternatives.
Generating Fine-Grained Open Vocabulary Entity Type Descriptions
May 27, 2018


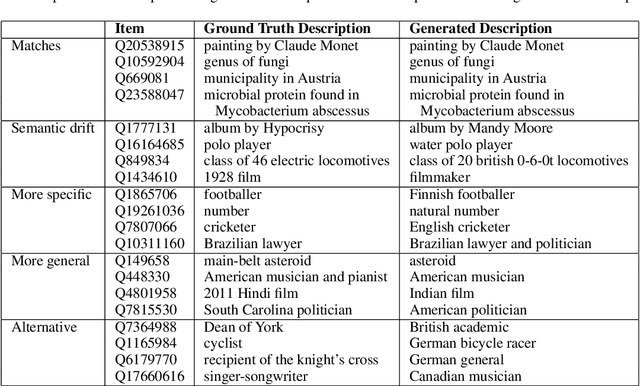
While large-scale knowledge graphs provide vast amounts of structured facts about entities, a short textual description can often be useful to succinctly characterize an entity and its type. Unfortunately, many knowledge graph entities lack such textual descriptions. In this paper, we introduce a dynamic memory-based network that generates a short open vocabulary description of an entity by jointly leveraging induced fact embeddings as well as the dynamic context of the generated sequence of words. We demonstrate the ability of our architecture to discern relevant information for more accurate generation of type description by pitting the system against several strong baselines.