 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Region Continual Learning as an Implicit Meta-Learner
Feb 02, 2026Continual learning aims to acquire tasks sequentially without catastrophic forgetting, yet standard strategies face a core tradeoff: regularization-based methods (e.g., EWC) can overconstrain updates when task optima are weakly overlapping, while replay-based methods can retain performance but drift due to imperfect replay. We study a hybrid perspective: \emph{trust region continual learning} that combines generative replay with a Fisher-metric trust region constraint. We show that, under local approximations, the resulting update admits a MAML-style interpretation with a single implicit inner step: replay supplies an old-task gradient signal (query-like), while the Fisher-weighted penalty provides an efficient offline curvature shaping (support-like). This yields an emergent meta-learning property in continual learning: the model becomes an initialization that rapidly \emph{re-converges} to prior task optima after each task transition, without explicitly optimizing a bilevel objective. Empirically, on task-incremental diffusion image generation and continual diffusion-policy control, trust region continual learning achieves the best final performance and retention, and consistently recovers early-task performance faster than EWC, replay, and continual meta-learning baselines.
FinForge: Semi-Synthetic Financial Benchmark Generation
Jan 11, 2026Evaluating Language Models (LMs) in specialized, high-stakes domains such as finance remains a significant challenge due to the scarcity of open, high-quality, and domain-specific datasets. Existing general-purpose benchmarks provide broad coverage but lack the depth and domain fidelity needed to assess LMs' capabilities for real-world financial reasoning, which requires both conceptual understanding and quantitative rigor. To address this gap, we introduce FinForge, a scalable, semi-synthetic pipeline for constructing finance-specific evaluation benchmarks through a hybrid of expert-guided data curation and controlled LM-based synthesis. FinForge combines manual and programmatic corpus construction from authoritative financial sources with structured question generation and validation using Gemini 2.5 Flash. To demonstrate the pipeline's efficacy, we produce FinForge-5k, a snapshot benchmark comprising over 5,000 human-validated question-answer pairs across 11 finance subdomains, derived from a curated corpus of 100,000 verified documents totaling 143M tokens. Evaluation of state-of-the-art open-source and closed-source models on FinForge-5k reveals significant differences in financial reasoning, with leading models achieving accuracy levels near 80%. These findings underscore the framework's utility for diagnosing current model limitations and guiding future improvements in financial domain competence. All code and data are available at https://github.com/gtfintechlab/FinForge.
Agentic Retrieval of Topics and Insights from Earnings Calls
Jul 10, 2025Tracking the strategic focus of companies through topics in their earnings calls is a key task in financial analysis. However, as industries evolve, traditional topic modeling techniques struggle to dynamically capture emerging topics and their relationships. In this work, we propose an LLM-agent driven approach to discover and retrieve emerging topics from quarterly earnings calls. We propose an LLM-agent to extract topics from documents, structure them into a hierarchical ontology, and establish relationships between new and existing topics through a topic ontology. We demonstrate the use of extracted topics to infer company-level insights and emerging trends over time. We evaluate our approach by measuring ontology coherence, topic evolution accuracy, and its ability to surface emerging financial trends.
Leveraging Contextual Information for Effective Entity Salience Detection
Sep 14, 2023
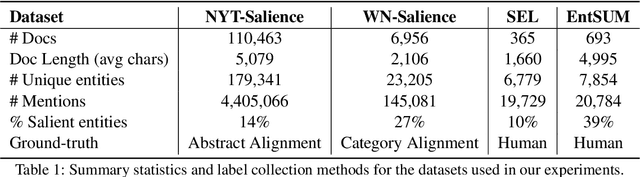
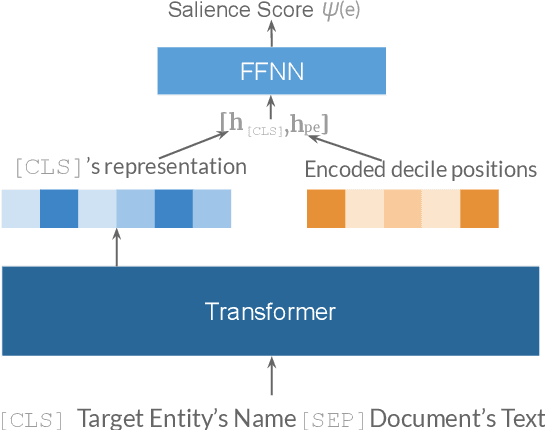
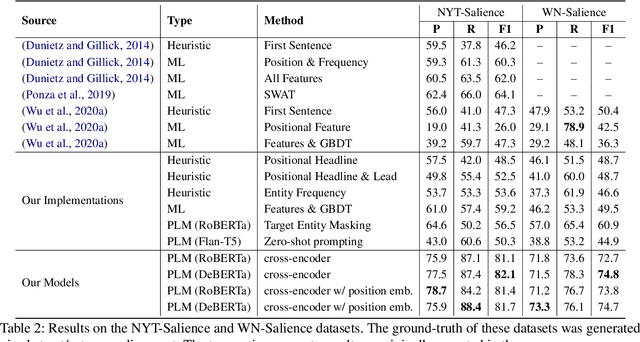
In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
Distillation of encoder-decoder transformers for sequence labelling
Feb 10, 2023



Driven by encouraging results on a wide range of tasks, the field of NLP is experiencing an accelerated race to develop bigger language models. This race for bigger models has also underscored the need to continue the pursuit of practical distillation approaches that can leverage the knowledge acquired by these big models in a compute-efficient manner. Having this goal in mind, we build on recent work to propose a hallucination-free framework for sequence tagging that is especially suited for distillation. We show empirical results of new state-of-the-art performance across multiple sequence labelling datasets and validate the usefulness of this framework for distilling a large model in a few-shot learning scenario.
Closing the convergence gap of SGD without replacement
Mar 05, 2020

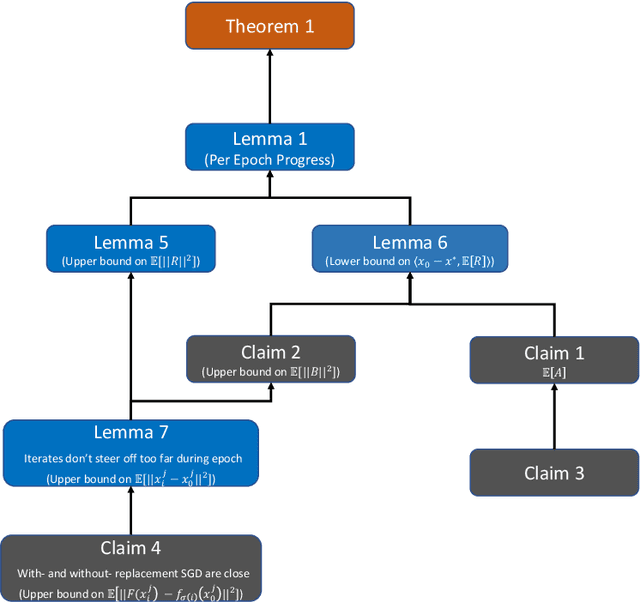
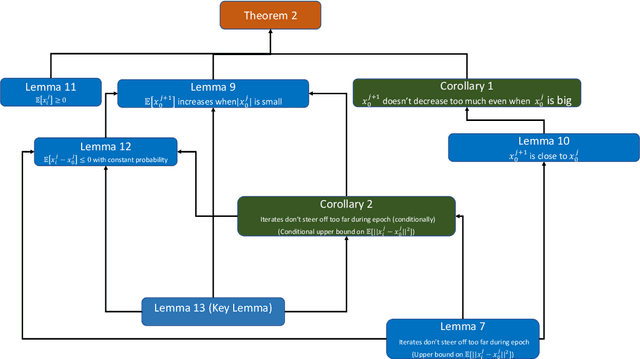
Stochastic gradient descent without replacement sampling is widely used in practice for model training. However, the vast majority of SGD analyses assumes data sampled with replacement, and when the function minimized is strongly convex, an $\mathcal{O}\left(\frac{1}{T}\right)$ rate can be established when SGD is run for $T$ iterations. A recent line of breakthrough work on SGD without replacement (SGDo) established an $\mathcal{O}\left(\frac{n}{T^2}\right)$ convergence rate when the function minimized is strongly convex and is a sum of $n$ smooth functions, and an $\mathcal{O}\left(\frac{1}{T^2}+\frac{n^3}{T^3}\right)$ rate for sums of quadratics. On the other hand, the tightest known lower bound postulates an $\Omega\left(\frac{1}{T^2}+\frac{n^2}{T^3}\right)$ rate, leaving open the possibility of better SGDo convergence rates in the general case. In this paper, we close this gap and show that SGD without replacement achieves a rate of $\mathcal{O}\left(\frac{1}{T^2}+\frac{n^2}{T^3}\right)$ when the sum of the functions is a quadratic, and offer a new lower bound of $\Omega\left(\frac{n}{T^2}\right)$ for strongly convex functions that are sums of smooth functions.
Asynchronous Single-Photon 3D Imaging
Aug 18, 2019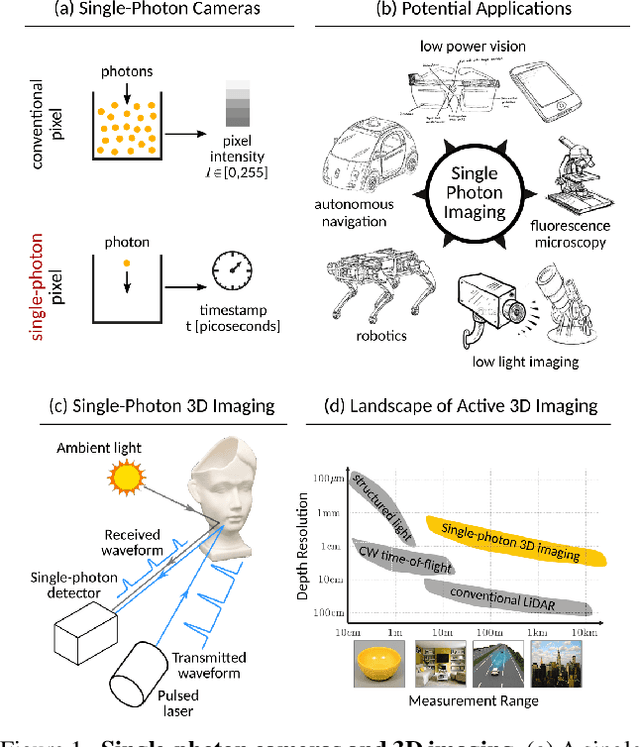
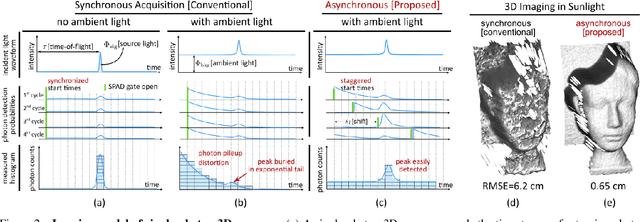
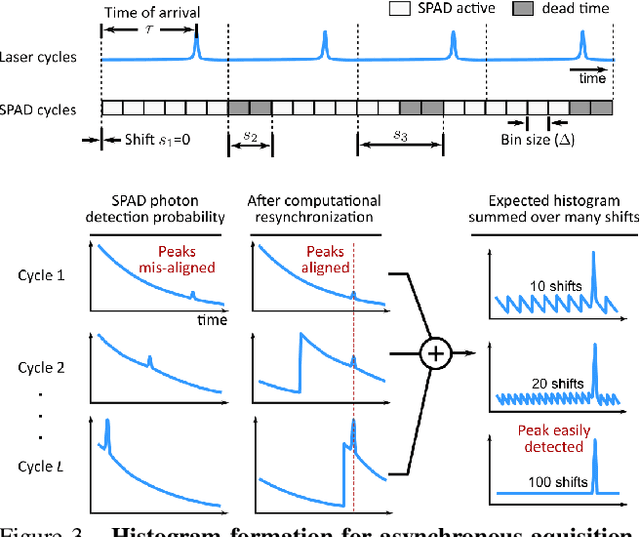
Single-photon avalanche diodes (SPADs) are becoming popular in time-of-flight depth-ranging due to their unique ability to capture individual photons with picosecond timing resolution. However, ambient light (e.g., sunlight) incident on a SPAD-based 3D camera leads to severe non-linear distortions (pileup) in the measured waveform, resulting in large depth errors. We propose asynchronous single-photon 3D imaging, a family of acquisition schemes to mitigate pileup during data acquisition itself. Asynchronous acquisition temporally misaligns SPAD measurement windows and the laser cycles through deterministically predefined or randomized offsets. Our key insight is that pileup distortions can be "averaged out" by choosing a sequence of offsets that span the entire depth range. We develop a generalized image formation model and perform theoretical analysis to explore the space of asynchronous acquisition schemes and design high-performance schemes. Our simulations and experiments demonstrate an improvement in depth accuracy of up to an order of magnitude as compared to the state-of-the-art, across a wide range of imaging scenarios, including those with high ambient flux.
Photon-Flooded Single-Photon 3D Cameras
Mar 20, 2019
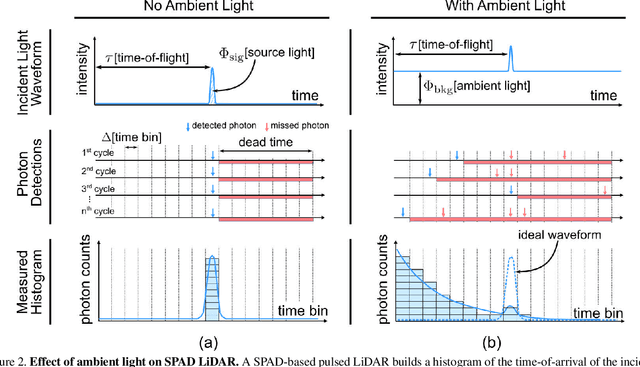
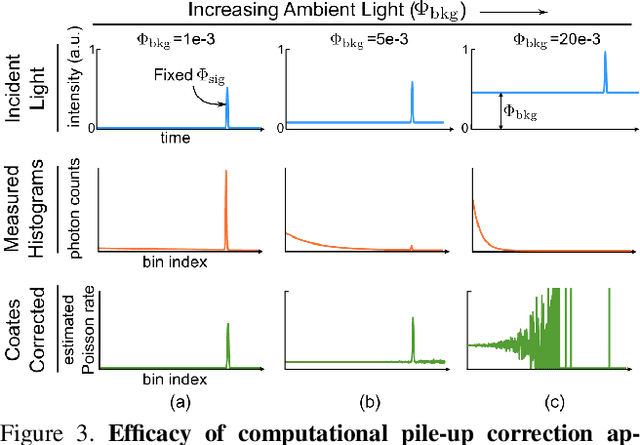
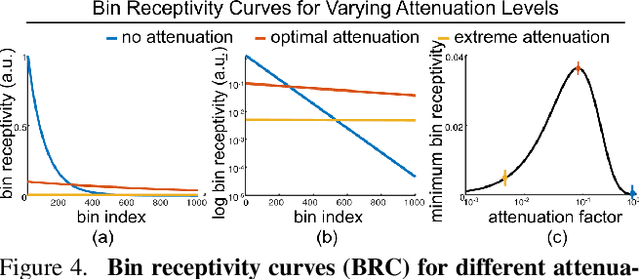
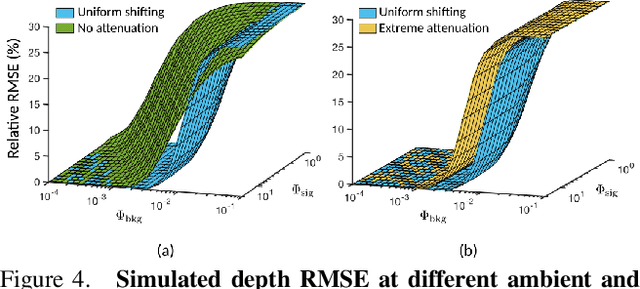
Single photon avalanche diodes (SPADs) are starting to play a pivotal role in the development of photon-efficient, long-range LiDAR systems. However, due to non-linearities in their image formation model, a high photon flux (e.g., due to strong sunlight) leads to distortion of the incident temporal waveform, and potentially, large depth errors. Operating SPADs in low flux regimes can mitigate these distortions, but, often requires attenuating the signal and thus, results in low signal-to-noise ratio. In this paper, we address the following basic question: what is the optimal photon flux that a SPAD-based LiDAR should be operated in? We derive a closed form expression for the optimal flux, which is quasi-depth-invariant, and depends on the ambient light strength. The optimal flux is lower than what a SPAD typically measures in real world scenarios, but surprisingly, considerably higher than what is conventionally suggested for avoiding distortions. We propose a simple, adaptive approach for achieving the optimal flux by attenuating incident flux based on an estimate of ambient light strength. Using extensive simulations and a hardware prototype, we show that the optimal flux criterion holds for several depth estimators, under a wide range of illumination conditions.
Generative Image Translation for Data Augmentation of Bone Lesion Pathology
Feb 06, 2019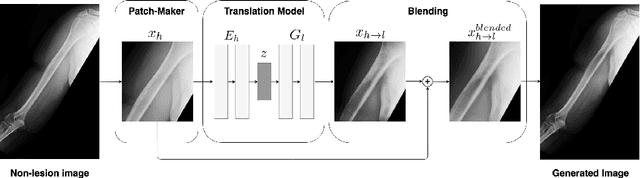
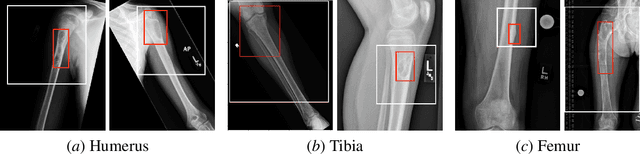
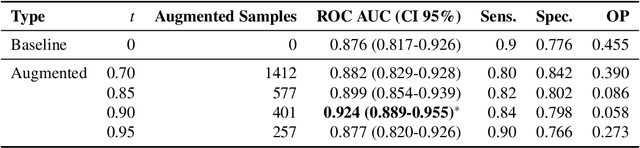
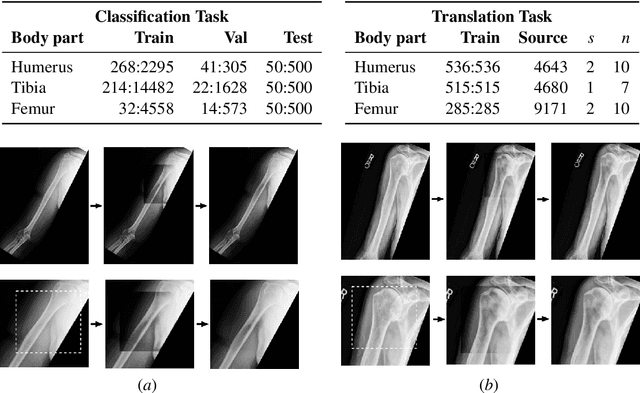
Insufficient training data and severe class imbalance are often limiting factors when developing machine learning models for the classification of rare diseases. In this work, we address the problem of classifying bone lesions from X-ray images by increasing the small number of positive samples in the training set. We propose a generative data augmentation approach based on a cycle-consistent generative adversarial network that synthesizes bone lesions on images without pathology. We pose the generative task as an image-patch translation problem that we optimize specifically for distinct bones (humerus, tibia, femur). In experimental results, we confirm that the described method mitigates the class imbalance problem in the binary classification task of bone lesion detection. We show that the augmented training sets enable the training of superior classifiers achieving better performance on a held-out test set. Additionally, we demonstrate the feasibility of transfer learning and apply a generative model that was trained on one body part to another.
Best-arm identification with cascading bandits
Nov 19, 2018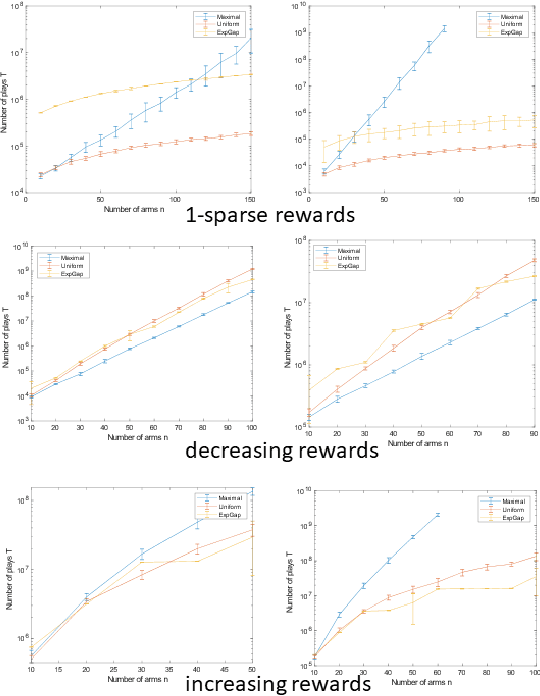
We consider a variant of the problem of best arm identification in multi-arm bandits, where in each round, multiple arms are played in an ordered fashion until a nonzero reward is obtained. Since each round potentially provides information about more than one arm, the sample complexity can be much lower than in the standard formulation. We introduce a subroutine to perform uniform sampling, that allows us to adapt certain optimal algorithms for the standard version to this variant. As we prove, much of the analysis goes through as well.