 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Contextual Information for Effective Entity Salience Detection
Sep 14, 2023
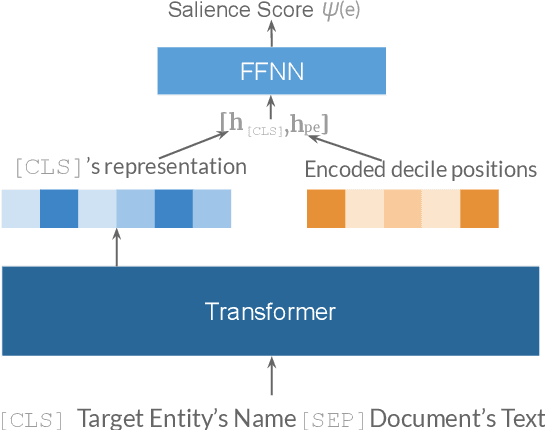
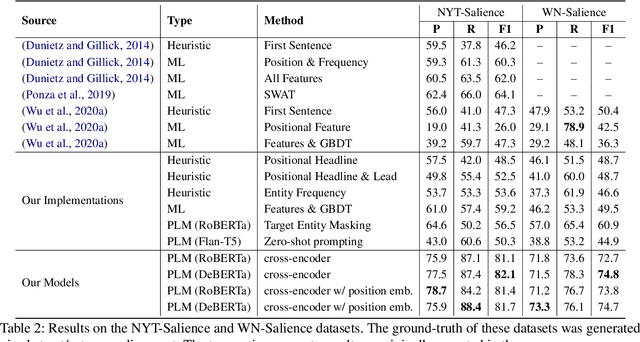
In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
A Study of the Generalizability of Self-Supervised Representations
Sep 19, 2021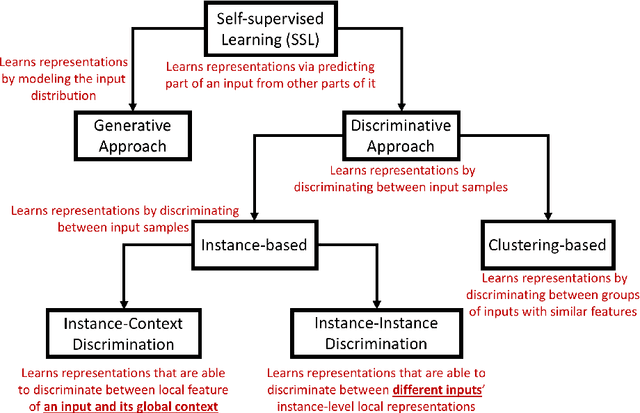


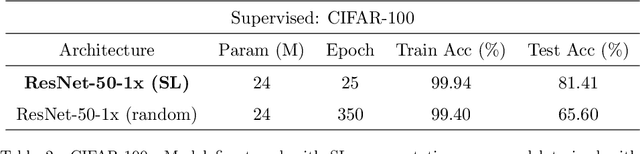
Recent advancements in self-supervised learning (SSL) made it possible to learn generalizable visual representations from unlabeled data. The performance of Deep Learning models fine-tuned on pretrained SSL representations is on par with models fine-tuned on the state-of-the-art supervised learning (SL) representations. Irrespective of the progress made in SSL, its generalizability has not been studied extensively. In this article, we perform a deeper analysis of the generalizability of pretrained SSL and SL representations by conducting a domain-based study for transfer learning classification tasks. The representations are learned from the ImageNet source data, which are then fine-tuned using two types of target datasets: similar to the source dataset, and significantly different from the source dataset. We study generalizability of the SSL and SL-based models via their prediction accuracy as well as prediction confidence. In addition to this, we analyze the attribution of the final convolutional layer of these models to understand how they reason about the semantic identity of the data. We show that the SSL representations are more generalizable as compared to the SL representations. We explain the generalizability of the SSL representations by investigating its invariance property, which is shown to be better than that observed in the SL representations.
* Journal of Machine Learning With Applications (MLWA)
WeightScale: Interpreting Weight Change in Neural Networks
Jul 07, 2021
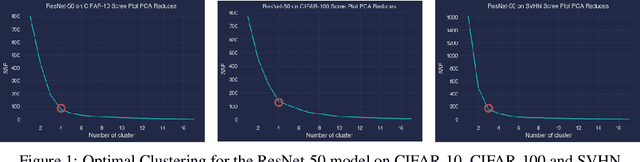
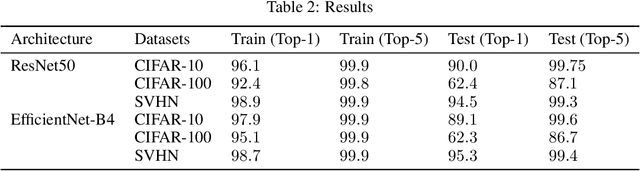
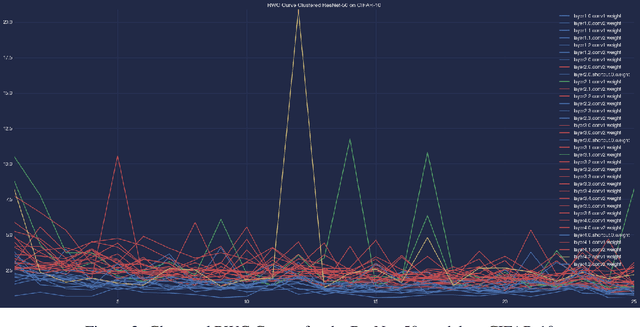
Interpreting the learning dynamics of neural networks can provide useful insights into how networks learn and the development of better training and design approaches. We present an approach to interpret learning in neural networks by measuring relative weight change on a per layer basis and dynamically aggregating emerging trends through combination of dimensionality reduction and clustering which allows us to scale to very deep networks. We use this approach to investigate learning in the context of vision tasks across a variety of state-of-the-art networks and provide insights into the learning behavior of these networks, including how task complexity affects layer-wise learning in deeper layers of networks.
Investigating Learning in Deep Neural Networks using Layer-Wise Weight Change
Dec 01, 2020
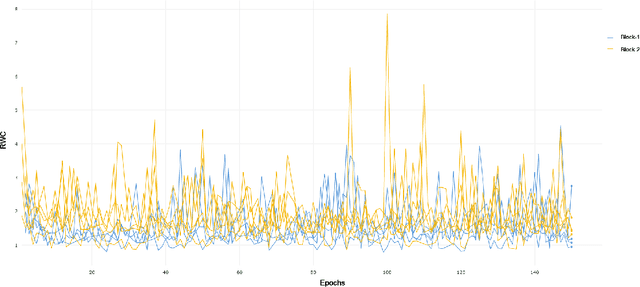
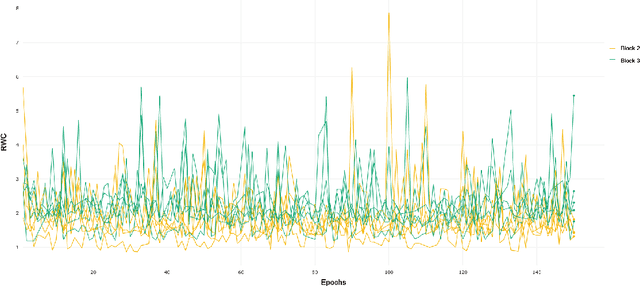
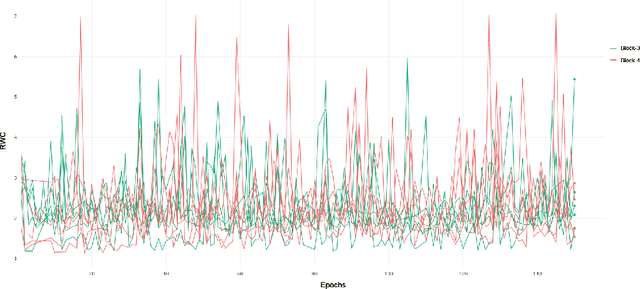
Understanding the per-layer learning dynamics of deep neural networks is of significant interest as it may provide insights into how neural networks learn and the potential for better training regimens. We investigate learning in Deep Convolutional Neural Networks (CNNs) by measuring the relative weight change of layers while training. Several interesting trends emerge in a variety of CNN architectures across various computer vision classification tasks, including the overall increase in relative weight change of later layers as compared to earlier ones.