 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Generalizability of Self-Supervised Representations
Paper and Code
Sep 19, 2021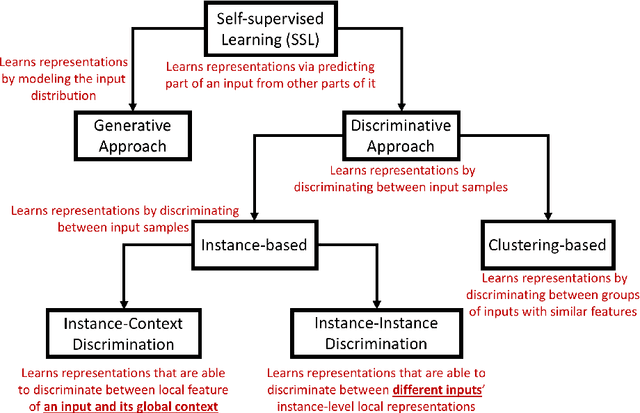


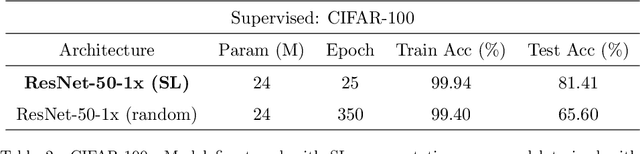
Recent advancements in self-supervised learning (SSL) made it possible to learn generalizable visual representations from unlabeled data. The performance of Deep Learning models fine-tuned on pretrained SSL representations is on par with models fine-tuned on the state-of-the-art supervised learning (SL) representations. Irrespective of the progress made in SSL, its generalizability has not been studied extensively. In this article, we perform a deeper analysis of the generalizability of pretrained SSL and SL representations by conducting a domain-based study for transfer learning classification tasks. The representations are learned from the ImageNet source data, which are then fine-tuned using two types of target datasets: similar to the source dataset, and significantly different from the source dataset. We study generalizability of the SSL and SL-based models via their prediction accuracy as well as prediction confidence. In addition to this, we analyze the attribution of the final convolutional layer of these models to understand how they reason about the semantic identity of the data. We show that the SSL representations are more generalizable as compared to the SL representations. We explain the generalizability of the SSL representations by investigating its invariance property, which is shown to be better than that observed in the SL representations.