 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Language Models for Analyzing Longitudinal Experiential Data in Education
Mar 27, 2025We propose a novel approach to leveraging pre-trained language models (LMs) for early forecasting of academic trajectories in STEM students using high-dimensional longitudinal experiential data. This data, which captures students' study-related activities, behaviors, and psychological states, offers valuable insights for forecasting-based interventions. Key challenges in handling such data include high rates of missing values, limited dataset size due to costly data collection, and complex temporal variability across modalities. Our approach addresses these issues through a comprehensive data enrichment process, integrating strategies for managing missing values, augmenting data, and embedding task-specific instructions and contextual cues to enhance the models' capacity for learning temporal patterns. Through extensive experiments on a curated student learning dataset, we evaluate both encoder-decoder and decoder-only LMs. While our findings show that LMs effectively integrate data across modalities and exhibit resilience to missing data, they primarily rely on high-level statistical patterns rather than demonstrating a deeper understanding of temporal dynamics. Furthermore, their ability to interpret explicit temporal information remains limited. This work advances educational data science by highlighting both the potential and limitations of LMs in modeling student trajectories for early intervention based on longitudinal experiential data.
CLAIM Your Data: Enhancing Imputation Accuracy with Contextual Large Language Models
May 28, 2024This paper introduces the Contextual Language model for Accurate Imputation Method (CLAIM), a novel strategy that capitalizes on the expansive knowledge and reasoning capabilities of pre-trained large language models (LLMs) to address missing data challenges in tabular datasets. Unlike traditional imputation methods, which predominantly rely on numerical estimations, CLAIM utilizes contextually relevant natural language descriptors to fill missing values. This approach transforms datasets into natural language contextualized formats that are inherently more aligned with LLMs' capabilities, thereby facilitating the dual use of LLMs: first, to generate missing value descriptors, and then, to fine-tune the LLM on the enriched dataset for improved performance in downstream tasks. Our evaluations across diverse datasets and missingness patterns reveal CLAIM's superior performance over existing imputation techniques. Furthermore, our investigation into the effectiveness of context-specific versus generic descriptors for missing data highlights the importance of contextual accuracy in enhancing LLM performance for data imputation. The results underscore CLAIM's potential to markedly improve the reliability and quality of data analysis and machine learning models, offering a more nuanced and effective solution for handling missing data.
A Study of the Generalizability of Self-Supervised Representations
Sep 19, 2021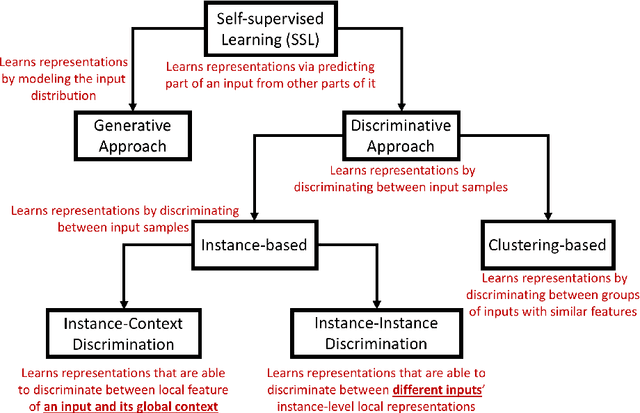


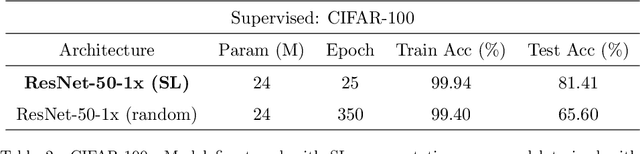
Recent advancements in self-supervised learning (SSL) made it possible to learn generalizable visual representations from unlabeled data. The performance of Deep Learning models fine-tuned on pretrained SSL representations is on par with models fine-tuned on the state-of-the-art supervised learning (SL) representations. Irrespective of the progress made in SSL, its generalizability has not been studied extensively. In this article, we perform a deeper analysis of the generalizability of pretrained SSL and SL representations by conducting a domain-based study for transfer learning classification tasks. The representations are learned from the ImageNet source data, which are then fine-tuned using two types of target datasets: similar to the source dataset, and significantly different from the source dataset. We study generalizability of the SSL and SL-based models via their prediction accuracy as well as prediction confidence. In addition to this, we analyze the attribution of the final convolutional layer of these models to understand how they reason about the semantic identity of the data. We show that the SSL representations are more generalizable as compared to the SL representations. We explain the generalizability of the SSL representations by investigating its invariance property, which is shown to be better than that observed in the SL representations.
* Journal of Machine Learning With Applications (MLWA)