 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-layer Integrated Sensing and Communication: A Joint Industrial and Academic Perspective
May 16, 2025



Integrated sensing and communication (ISAC) enables radio systems to simultaneously sense and communicate with their environment. This paper, developed within the Hexa-X-II project funded by the European Union, presents a comprehensive cross-layer vision for ISAC in 6G networks, integrating insights from physical-layer design, hardware architectures, AI-driven intelligence, and protocol-level innovations. We begin by revisiting the foundational principles of ISAC, highlighting synergies and trade-offs between sensing and communication across different integration levels. Enabling technologies, such as multiband operation, massive and distributed MIMO, non-terrestrial networks, reconfigurable intelligent surfaces, and machine learning, are analyzed in conjunction with hardware considerations including waveform design, synchronization, and full-duplex operation. To bridge implementation and system-level evaluation, we introduce a quantitative cross-layer framework linking design parameters to key performance and value indicators. By synthesizing perspectives from both academia and industry, this paper outlines how deeply integrated ISAC can transform 6G into a programmable and context-aware platform supporting applications from reliable wireless access to autonomous mobility and digital twinning.
Leveraging Language Models for Analyzing Longitudinal Experiential Data in Education
Mar 27, 2025We propose a novel approach to leveraging pre-trained language models (LMs) for early forecasting of academic trajectories in STEM students using high-dimensional longitudinal experiential data. This data, which captures students' study-related activities, behaviors, and psychological states, offers valuable insights for forecasting-based interventions. Key challenges in handling such data include high rates of missing values, limited dataset size due to costly data collection, and complex temporal variability across modalities. Our approach addresses these issues through a comprehensive data enrichment process, integrating strategies for managing missing values, augmenting data, and embedding task-specific instructions and contextual cues to enhance the models' capacity for learning temporal patterns. Through extensive experiments on a curated student learning dataset, we evaluate both encoder-decoder and decoder-only LMs. While our findings show that LMs effectively integrate data across modalities and exhibit resilience to missing data, they primarily rely on high-level statistical patterns rather than demonstrating a deeper understanding of temporal dynamics. Furthermore, their ability to interpret explicit temporal information remains limited. This work advances educational data science by highlighting both the potential and limitations of LMs in modeling student trajectories for early intervention based on longitudinal experiential data.
A Novel GAN Approach to Augment Limited Tabular Data for Short-Term Substance Use Prediction
Jul 17, 2024Substance use is a global issue that negatively impacts millions of persons who use drugs (PWUDs). In practice, identifying vulnerable PWUDs for efficient allocation of appropriate resources is challenging due to their complex use patterns (e.g., their tendency to change usage within months) and the high acquisition costs for collecting PWUD-focused substance use data. Thus, there has been a paucity of machine learning models for accurately predicting short-term substance use behaviors of PWUDs. In this paper, using longitudinal survey data of 258 PWUDs in the U.S. Great Plains collected by our team, we design a novel GAN that deals with high-dimensional low-sample-size tabular data and survey skip logic to augment existing data to improve classification models' prediction on (A) whether the PWUDs would increase usage and (B) at which ordinal frequency they would use a particular drug within the next 12 months. Our evaluation results show that, when trained on augmented data from our proposed GAN, the classification models improve their predictive performance (AUROC) by up to 13.4% in Problem (A) and 15.8% in Problem (B) for usage of marijuana, meth, amphetamines, and cocaine, which outperform state-of-the-art generative models.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Ethics of AI: A Systematic Literature Review of Principles and Challenges
Sep 12, 2021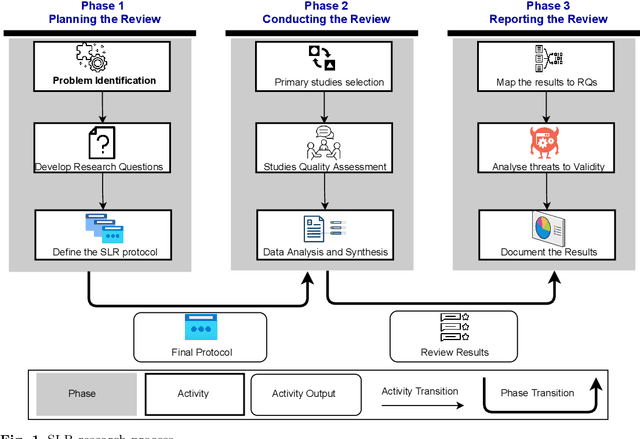

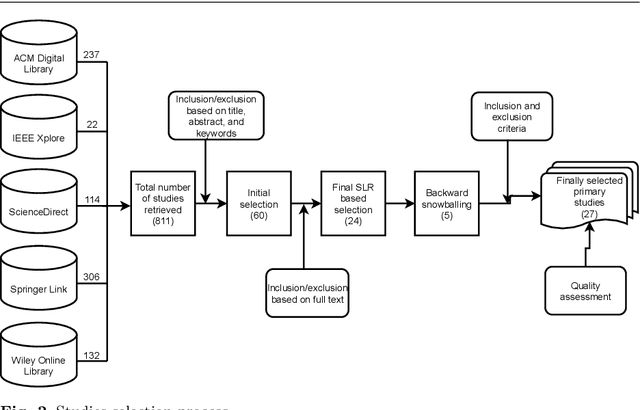

Ethics in AI becomes a global topic of interest for both policymakers and academic researchers. In the last few years, various research organizations, lawyers, think tankers and regulatory bodies get involved in developing AI ethics guidelines and principles. However, there is still debate about the implications of these principles. We conducted a systematic literature review (SLR) study to investigate the agreement on the significance of AI principles and identify the challenging factors that could negatively impact the adoption of AI ethics principles. The results reveal that the global convergence set consists of 22 ethical principles and 15 challenges. Transparency, privacy, accountability and fairness are identified as the most common AI ethics principles. Similarly, lack of ethical knowledge and vague principles are reported as the significant challenges for considering ethics in AI. The findings of this study are the preliminary inputs for proposing a maturity model that assess the ethical capabilities of AI systems and provide best practices for further improvements.