 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Designing Participatory Budgeting Rules
Feb 11, 2026Participatory budgeting (PB) is a democratic paradigm for deciding the funding of public projects given the residents' preferences, which has been adopted in numerous cities across the world. The main focus of PB is designing rules, functions that return feasible budget allocations for a set of projects subject to some budget constraint. Designing PB rules that optimize both utility and fairness objectives based on agent preferences had been challenging due to the extensive domain knowledge required and the proven trade-off between the two notions. Recently, large language models (LLMs) have been increasingly employed for automated algorithmic design. Given the resemblance of PB rules to algorithms for classical knapsack problems, in this paper, we introduce a novel framework, named LLMRule, that addresses the limitations of existing works by incorporating LLMs into an evolutionary search procedure for automating the design of PB rules. Our experimental results, evaluated on more than 600 real-world PB instances obtained from the U.S., Canada, Poland, and the Netherlands with different representations of agent preferences, demonstrate that the LLM-generated rules generally outperform existing handcrafted rules in terms of overall utility while still maintaining a similar degree of fairness.
RedAHD: Reduction-Based End-to-End Automatic Heuristic Design with Large Language Models
May 26, 2025Solving NP-hard combinatorial optimization problems (COPs) (e.g., traveling salesman problems (TSPs) and capacitated vehicle routing problems (CVRPs)) in practice traditionally involves handcrafting heuristics or specifying a search space for finding effective heuristics. The main challenges from these approaches, however, are the sheer amount of domain knowledge and implementation efforts required from human experts. Recently, significant progress has been made to address these challenges, particularly by using large language models (LLMs) to design heuristics within some predetermined generalized algorithmic framework (GAF, e.g., ant colony optimization and guided local search) for building key functions/components (e.g., a priori information on how promising it is to include each edge in a solution for TSP and CVRP). Although existing methods leveraging this idea have shown to yield impressive optimization performance, they are not fully end-to-end and still require considerable manual interventions. In this paper, we propose a novel end-to-end framework, named RedAHD, that enables these LLM-based heuristic design methods to operate without the need of GAFs. More specifically, RedAHD employs LLMs to automate the process of reduction, i.e., transforming the COP at hand into similar COPs that are better-understood, from which LLM-based heuristic design methods can design effective heuristics for directly solving the transformed COPs and, in turn, indirectly solving the original COP. Our experimental results, evaluated on six COPs, show that RedAHD is capable of designing heuristics with competitive or improved results over the state-of-the-art methods with minimal human involvement.
CARE: Compatibility-Aware Incentive Mechanisms for Federated Learning with Budgeted Requesters
Apr 22, 2025Federated learning (FL) is a promising approach that allows requesters (\eg, servers) to obtain local training models from workers (e.g., clients). Since workers are typically unwilling to provide training services/models freely and voluntarily, many incentive mechanisms in FL are designed to incentivize participation by offering monetary rewards from requesters. However, existing studies neglect two crucial aspects of real-world FL scenarios. First, workers can possess inherent incompatibility characteristics (e.g., communication channels and data sources), which can lead to degradation of FL efficiency (e.g., low communication efficiency and poor model generalization). Second, the requesters are budgeted, which limits the amount of workers they can hire for their tasks. In this paper, we investigate the scenario in FL where multiple budgeted requesters seek training services from incompatible workers with private training costs. We consider two settings: the cooperative budget setting where requesters cooperate to pool their budgets to improve their overall utility and the non-cooperative budget setting where each requester optimizes their utility within their own budgets. To address efficiency degradation caused by worker incompatibility, we develop novel compatibility-aware incentive mechanisms, CARE-CO and CARE-NO, for both settings to elicit true private costs and determine workers to hire for requesters and their rewards while satisfying requester budget constraints. Our mechanisms guarantee individual rationality, truthfulness, budget feasibility, and approximation performance. We conduct extensive experiments using real-world datasets to show that the proposed mechanisms significantly outperform existing baselines.
Large Language Models for Multi-Facility Location Mechanism Design
Mar 13, 2025Designing strategyproof mechanisms for multi-facility location that optimize social costs based on agent preferences had been challenging due to the extensive domain knowledge required and poor worst-case guarantees. Recently, deep learning models have been proposed as alternatives. However, these models require some domain knowledge and extensive hyperparameter tuning as well as lacking interpretability, which is crucial in practice when transparency of the learned mechanisms is mandatory. In this paper, we introduce a novel approach, named LLMMech, that addresses these limitations by incorporating large language models (LLMs) into an evolutionary framework for generating interpretable, hyperparameter-free, empirically strategyproof, and nearly optimal mechanisms. Our experimental results, evaluated on various problem settings where the social cost is arbitrarily weighted across agents and the agent preferences may not be uniformly distributed, demonstrate that the LLM-generated mechanisms generally outperform existing handcrafted baselines and deep learning models. Furthermore, the mechanisms exhibit impressive generalizability to out-of-distribution agent preferences and to larger instances with more agents.
Double Oracle Neural Architecture Search for Game Theoretic Deep Learning Models
Oct 07, 2024



In this paper, we propose a new approach to train deep learning models using game theory concepts including Generative Adversarial Networks (GANs) and Adversarial Training (AT) where we deploy a double-oracle framework using best response oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. The same concept can be applied to AT with attacker and classifier as players. Training these models is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as training algorithms for both GAN and AT have a large-scale strategy space. Extending our preliminary model DO-GAN, we propose the methods to apply the double oracle framework concept to Adversarial Neural Architecture Search (NAS for GAN) and Adversarial Training (NAS for AT) algorithms. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple network models of best responses are stored in the memory, we prune the weakly-dominated players' strategies to keep the oracles from becoming intractable. Finally, we conduct experiments on MNIST, CIFAR-10 and TinyImageNet for DONAS-GAN. We also evaluate the robustness under FGSM and PGD attacks on CIFAR-10, SVHN and TinyImageNet for DONAS-AT. We show that all our variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective base architectures.
In-Context Exploiter for Extensive-Form Games
Aug 10, 2024



Nash equilibrium (NE) is a widely adopted solution concept in game theory due to its stability property. However, we observe that the NE strategy might not always yield the best results, especially against opponents who do not adhere to NE strategies. Based on this observation, we pose a new game-solving question: Can we learn a model that can exploit any, even NE, opponent to maximize their own utility? In this work, we make the first attempt to investigate this problem through in-context learning. Specifically, we introduce a novel method, In-Context Exploiter (ICE), to train a single model that can act as any player in the game and adaptively exploit opponents entirely by in-context learning. Our ICE algorithm involves generating diverse opponent strategies, collecting interactive history training data by a reinforcement learning algorithm, and training a transformer-based agent within a well-designed curriculum learning framework. Finally, comprehensive experimental results validate the effectiveness of our ICE algorithm, showcasing its in-context learning ability to exploit any unknown opponent, thereby positively answering our initial game-solving question.
A Novel GAN Approach to Augment Limited Tabular Data for Short-Term Substance Use Prediction
Jul 17, 2024Substance use is a global issue that negatively impacts millions of persons who use drugs (PWUDs). In practice, identifying vulnerable PWUDs for efficient allocation of appropriate resources is challenging due to their complex use patterns (e.g., their tendency to change usage within months) and the high acquisition costs for collecting PWUD-focused substance use data. Thus, there has been a paucity of machine learning models for accurately predicting short-term substance use behaviors of PWUDs. In this paper, using longitudinal survey data of 258 PWUDs in the U.S. Great Plains collected by our team, we design a novel GAN that deals with high-dimensional low-sample-size tabular data and survey skip logic to augment existing data to improve classification models' prediction on (A) whether the PWUDs would increase usage and (B) at which ordinal frequency they would use a particular drug within the next 12 months. Our evaluation results show that, when trained on augmented data from our proposed GAN, the classification models improve their predictive performance (AUROC) by up to 13.4% in Problem (A) and 15.8% in Problem (B) for usage of marijuana, meth, amphetamines, and cocaine, which outperform state-of-the-art generative models.
Configurable Mirror Descent: Towards a Unification of Decision Making
May 20, 2024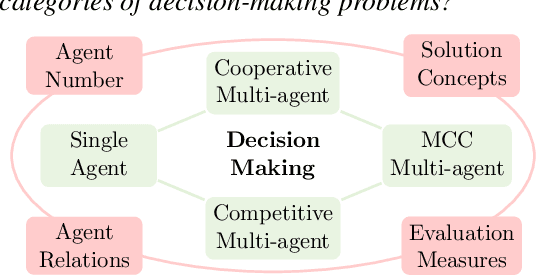



Decision-making problems, categorized as single-agent, e.g., Atari, cooperative multi-agent, e.g., Hanabi, competitive multi-agent, e.g., Hold'em poker, and mixed cooperative and competitive, e.g., football, are ubiquitous in the real world. Various methods are proposed to address the specific decision-making problems. Despite the successes in specific categories, these methods typically evolve independently and cannot generalize to other categories. Therefore, a fundamental question for decision-making is: \emph{Can we develop \textbf{a single algorithm} to tackle \textbf{ALL} categories of decision-making problems?} There are several main challenges to address this question: i) different decision-making categories involve different numbers of agents and different relationships between agents, ii) different categories have different solution concepts and evaluation measures, and iii) there lacks a comprehensive benchmark covering all the categories. This work presents a preliminary attempt to address the question with three main contributions. i) We propose the generalized mirror descent (GMD), a generalization of MD variants, which considers multiple historical policies and works with a broader class of Bregman divergences. ii) We propose the configurable mirror descent (CMD) where a meta-controller is introduced to dynamically adjust the hyper-parameters in GMD conditional on the evaluation measures. iii) We construct the \textsc{GameBench} with 15 academic-friendly games across different decision-making categories. Extensive experiments demonstrate that CMD achieves empirically competitive or better outcomes compared to baselines while providing the capability of exploring diverse dimensions of decision making.
Grasper: A Generalist Pursuer for Pursuit-Evasion Problems
Apr 19, 2024


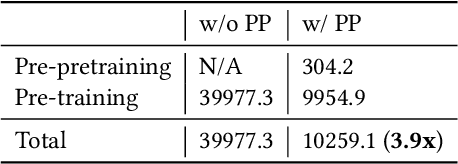
Pursuit-evasion games (PEGs) model interactions between a team of pursuers and an evader in graph-based environments such as urban street networks. Recent advancements have demonstrated the effectiveness of the pre-training and fine-tuning paradigm in PSRO to improve scalability in solving large-scale PEGs. However, these methods primarily focus on specific PEGs with fixed initial conditions that may vary substantially in real-world scenarios, which significantly hinders the applicability of the traditional methods. To address this issue, we introduce Grasper, a GeneRAlist purSuer for Pursuit-Evasion pRoblems, capable of efficiently generating pursuer policies tailored to specific PEGs. Our contributions are threefold: First, we present a novel architecture that offers high-quality solutions for diverse PEGs, comprising critical components such as (i) a graph neural network (GNN) to encode PEGs into hidden vectors, and (ii) a hypernetwork to generate pursuer policies based on these hidden vectors. As a second contribution, we develop an efficient three-stage training method involving (i) a pre-pretraining stage for learning robust PEG representations through self-supervised graph learning techniques like GraphMAE, (ii) a pre-training stage utilizing heuristic-guided multi-task pre-training (HMP) where heuristic-derived reference policies (e.g., through Dijkstra's algorithm) regularize pursuer policies, and (iii) a fine-tuning stage that employs PSRO to generate pursuer policies on designated PEGs. Finally, we perform extensive experiments on synthetic and real-world maps, showcasing Grasper's significant superiority over baselines in terms of solution quality and generalizability. We demonstrate that Grasper provides a versatile approach for solving pursuit-evasion problems across a broad range of scenarios, enabling practical deployment in real-world situations.
Self-adaptive PSRO: Towards an Automatic Population-based Game Solver
Apr 17, 2024Policy-Space Response Oracles (PSRO) as a general algorithmic framework has achieved state-of-the-art performance in learning equilibrium policies of two-player zero-sum games. However, the hand-crafted hyperparameter value selection in most of the existing works requires extensive domain knowledge, forming the main barrier to applying PSRO to different games. In this work, we make the first attempt to investigate the possibility of self-adaptively determining the optimal hyperparameter values in the PSRO framework. Our contributions are three-fold: (1) Using several hyperparameters, we propose a parametric PSRO that unifies the gradient descent ascent (GDA) and different PSRO variants. (2) We propose the self-adaptive PSRO (SPSRO) by casting the hyperparameter value selection of the parametric PSRO as a hyperparameter optimization (HPO) problem where our objective is to learn an HPO policy that can self-adaptively determine the optimal hyperparameter values during the running of the parametric PSRO. (3) To overcome the poor performance of online HPO methods, we propose a novel offline HPO approach to optimize the HPO policy based on the Transformer architecture. Experiments on various two-player zero-sum games demonstrate the superiority of SPSRO over different baselines.