 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasper: A Generalist Pursuer for Pursuit-Evasion Problems
Apr 19, 2024


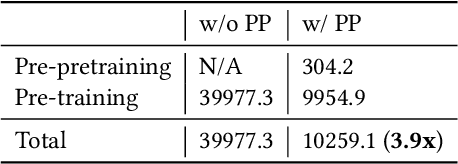
Pursuit-evasion games (PEGs) model interactions between a team of pursuers and an evader in graph-based environments such as urban street networks. Recent advancements have demonstrated the effectiveness of the pre-training and fine-tuning paradigm in PSRO to improve scalability in solving large-scale PEGs. However, these methods primarily focus on specific PEGs with fixed initial conditions that may vary substantially in real-world scenarios, which significantly hinders the applicability of the traditional methods. To address this issue, we introduce Grasper, a GeneRAlist purSuer for Pursuit-Evasion pRoblems, capable of efficiently generating pursuer policies tailored to specific PEGs. Our contributions are threefold: First, we present a novel architecture that offers high-quality solutions for diverse PEGs, comprising critical components such as (i) a graph neural network (GNN) to encode PEGs into hidden vectors, and (ii) a hypernetwork to generate pursuer policies based on these hidden vectors. As a second contribution, we develop an efficient three-stage training method involving (i) a pre-pretraining stage for learning robust PEG representations through self-supervised graph learning techniques like GraphMAE, (ii) a pre-training stage utilizing heuristic-guided multi-task pre-training (HMP) where heuristic-derived reference policies (e.g., through Dijkstra's algorithm) regularize pursuer policies, and (iii) a fine-tuning stage that employs PSRO to generate pursuer policies on designated PEGs. Finally, we perform extensive experiments on synthetic and real-world maps, showcasing Grasper's significant superiority over baselines in terms of solution quality and generalizability. We demonstrate that Grasper provides a versatile approach for solving pursuit-evasion problems across a broad range of scenarios, enabling practical deployment in real-world situations.
Offline Equilibrium Finding
Jul 12, 2022
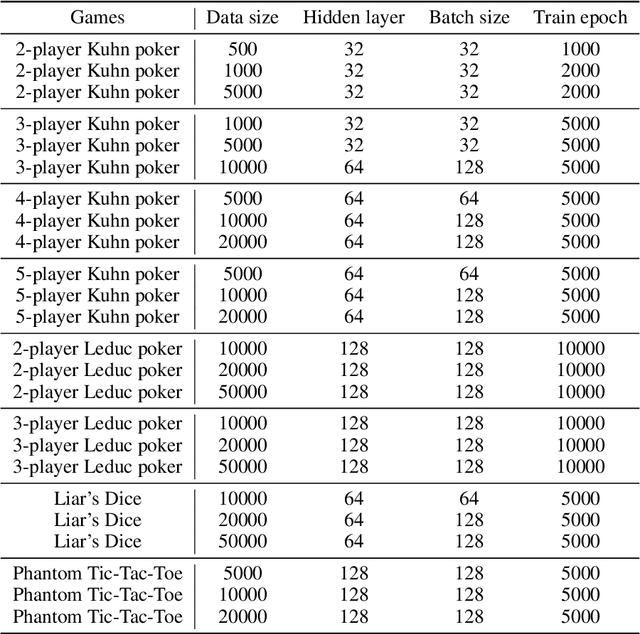
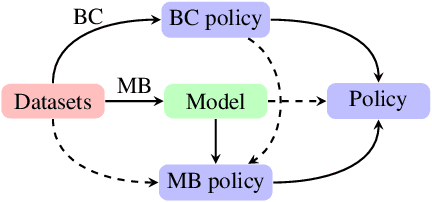
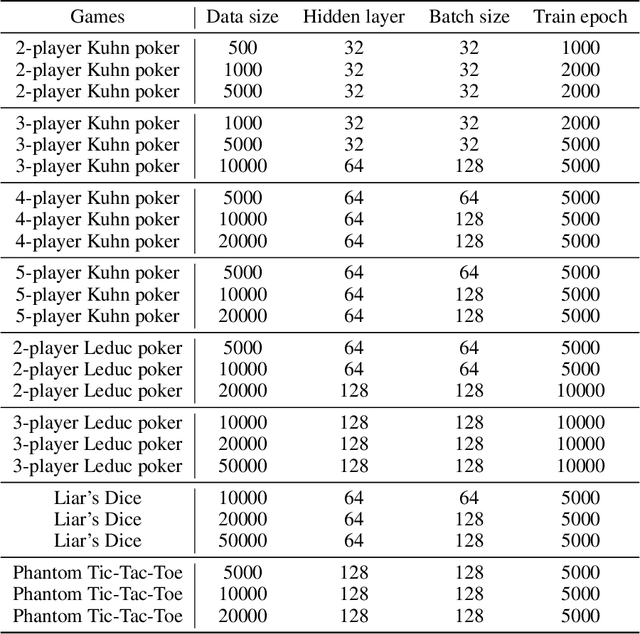
Offline reinforcement learning (Offline RL) is an emerging field that has recently begun gaining attention across various application domains due to its ability to learn behavior from earlier collected datasets. Using logged data is imperative when further interaction with the environment is expensive (computationally or otherwise), unsafe, or entirely unfeasible. Offline RL proved very successful, paving a path to solving previously intractable real-world problems, and we aim to generalize this paradigm to a multi-agent or multiplayer-game setting. Very little research has been done in this area, as the progress is hindered by the lack of standardized datasets and meaningful benchmarks. In this work, we coin the term offline equilibrium finding (OEF) to describe this area and construct multiple datasets consisting of strategies collected across a wide range of games using several established methods. We also propose a benchmark method -- an amalgamation of a behavior-cloning and a model-based algorithm. Our two model-based algorithms -- OEF-PSRO and OEF-CFR -- are adaptations of the widely-used equilibrium finding algorithms Deep CFR and PSRO in the context of offline learning. In the empirical part, we evaluate the performance of the benchmark algorithms on the constructed datasets. We hope that our efforts may help to accelerate research in large-scale equilibrium finding. Datasets and code are available at https://github.com/SecurityGames/oef.