 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Instruct Models for Free: A Study on Partial Adaptation
Apr 15, 2025Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model being overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.
Non-contrastive sentence representations via self-supervision
Oct 26, 2023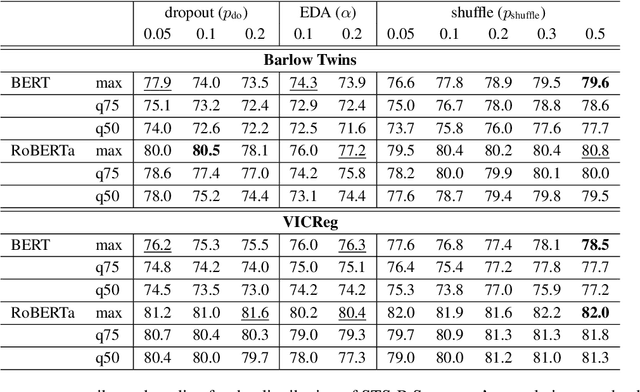
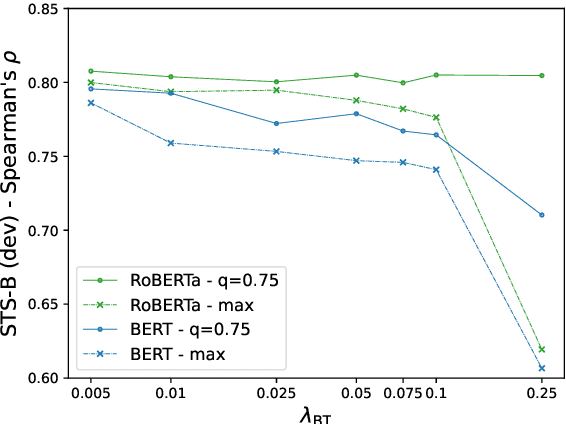
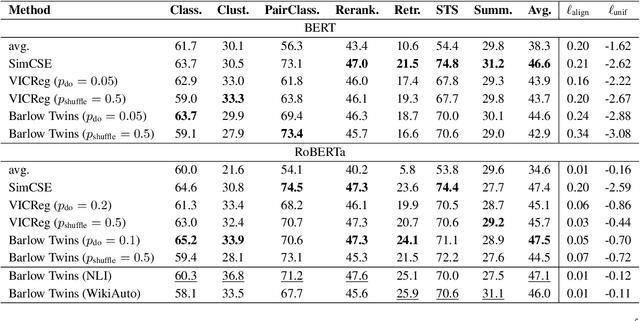
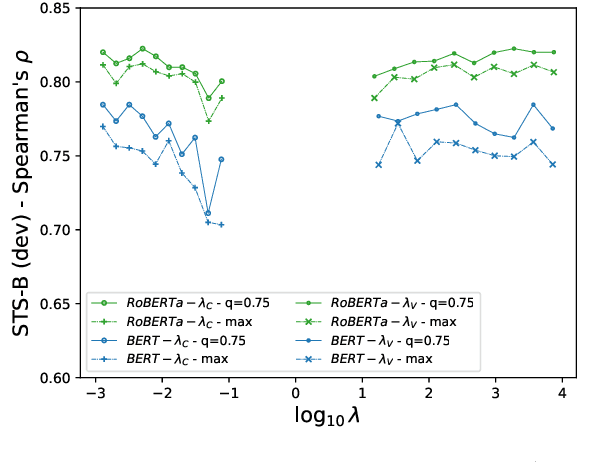
Sample contrastive methods, typically referred to simply as contrastive are the foundation of most unsupervised methods to learn text and sentence embeddings. On the other hand, a different class of self-supervised loss functions and methods have been considered in the computer vision community and referred to as dimension contrastive. In this paper, we thoroughly compare this class of methods with the standard baseline for contrastive sentence embeddings, SimCSE. We find that self-supervised embeddings trained using dimension contrastive objectives can outperform SimCSE on downstream tasks without needing auxiliary loss functions.
Distillation of encoder-decoder transformers for sequence labelling
Feb 10, 2023



Driven by encouraging results on a wide range of tasks, the field of NLP is experiencing an accelerated race to develop bigger language models. This race for bigger models has also underscored the need to continue the pursuit of practical distillation approaches that can leverage the knowledge acquired by these big models in a compute-efficient manner. Having this goal in mind, we build on recent work to propose a hallucination-free framework for sequence tagging that is especially suited for distillation. We show empirical results of new state-of-the-art performance across multiple sequence labelling datasets and validate the usefulness of this framework for distilling a large model in a few-shot learning scenario.
Disentangling Online Chats with DAG-Structured LSTMs
Jun 16, 2021
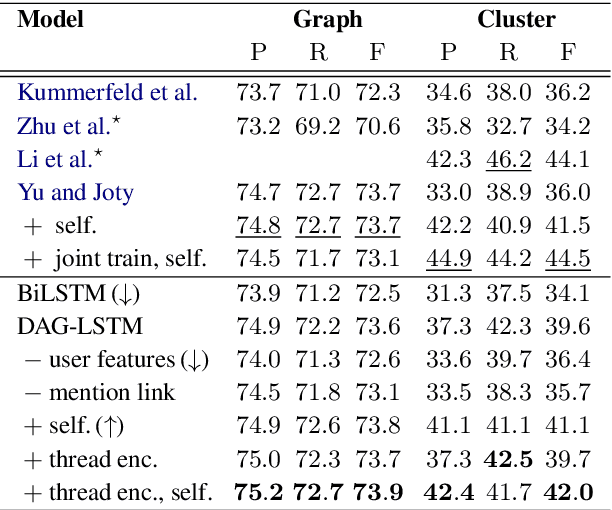
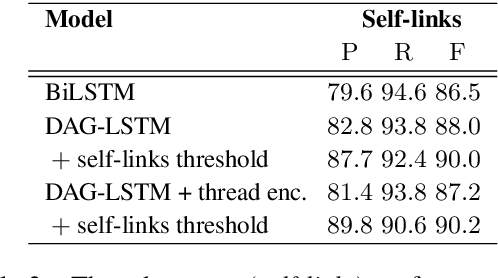

Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
Hierarchical clustering in particle physics through reinforcement learning
Nov 16, 2020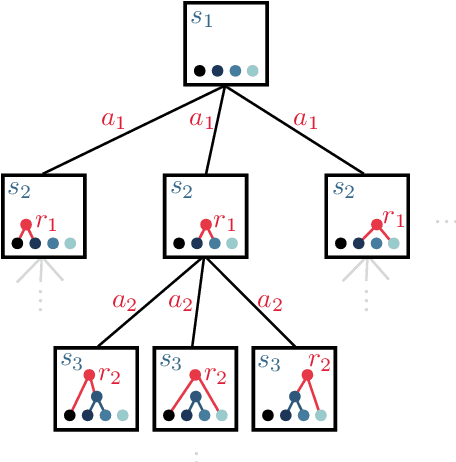
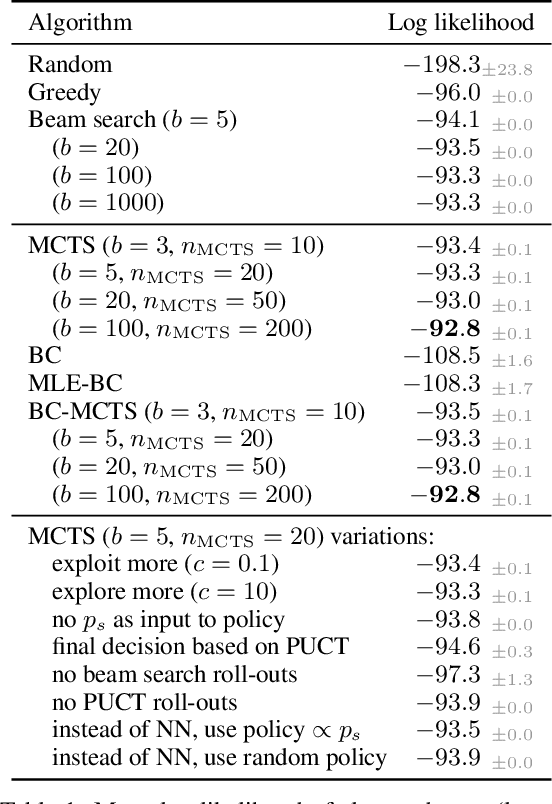
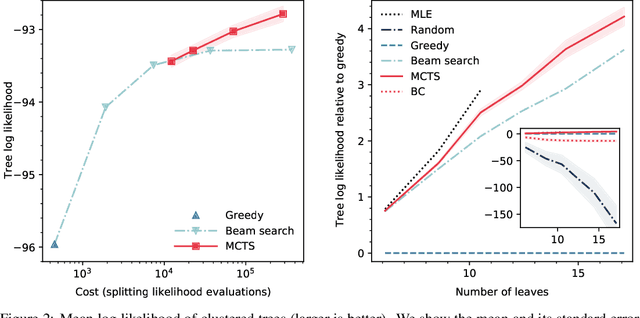
Particle physics experiments often require the reconstruction of decay patterns through a hierarchical clustering of the observed final-state particles. We show that this task can be phrased as a Markov Decision Process and adapt reinforcement learning algorithms to solve it. In particular, we show that Monte-Carlo Tree Search guided by a neural policy can construct high-quality hierarchical clusterings and outperform established greedy and beam search baselines.
Dialogue Act Classification in Group Chats with DAG-LSTMs
Aug 02, 2019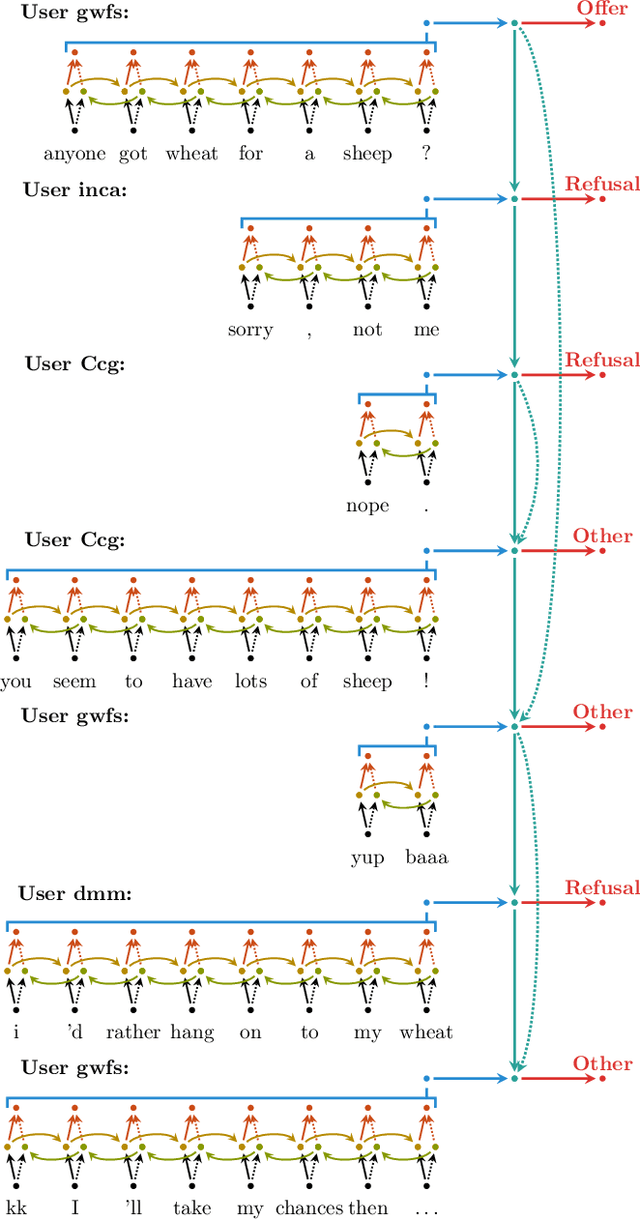
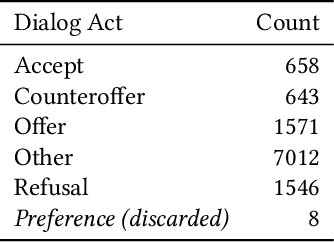

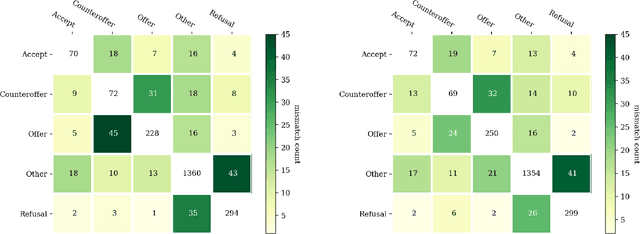
Dialogue act (DA) classification has been studied for the past two decades and has several key applications such as workflow automation and conversation analytics. Researchers have used, to address this problem, various traditional machine learning models, and more recently deep neural network models such as hierarchical convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. In this paper, we introduce a new model architecture, directed-acyclic-graph LSTM (DAG-LSTM) for DA classification. A DAG-LSTM exploits the turn-taking structure naturally present in a multi-party conversation, and encodes this relation in its model structure. Using the STAC corpus, we show that the proposed method performs roughly 0.8% better in accuracy and 1.2% better in macro-F1 score when compared to existing methods. The proposed method is generic and not limited to conversation applications.
Inferring the quantum density matrix with machine learning
Apr 11, 2019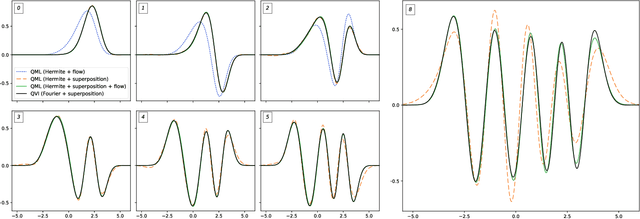

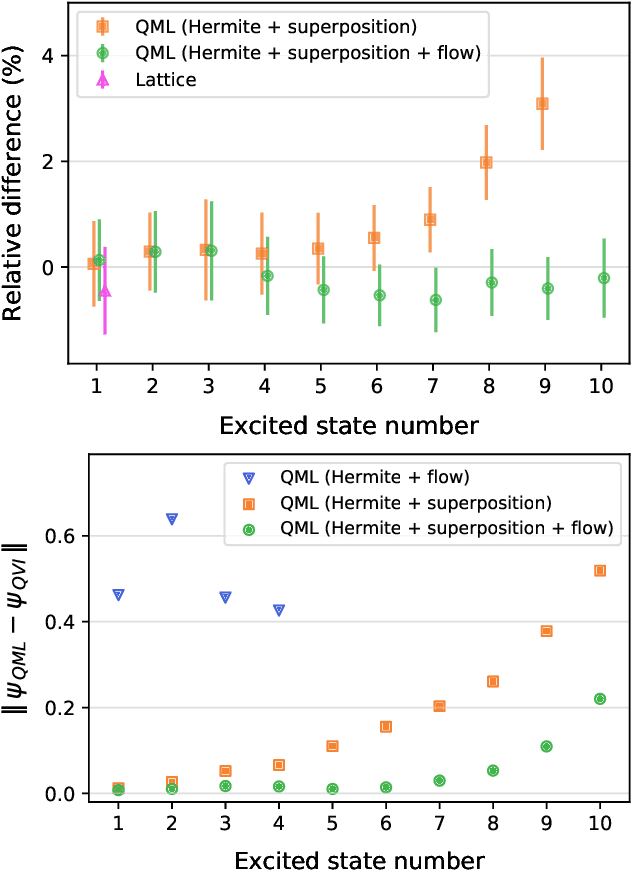

We introduce two methods for estimating the density matrix for a quantum system: Quantum Maximum Likelihood and Quantum Variational Inference. In these methods, we construct a variational family to model the density matrix of a mixed quantum state. We also introduce quantum flows, the quantum analog of normalizing flows, which can be used to increase the expressivity of this variational family. The eigenstates and eigenvalues of interest are then derived by optimizing an appropriate loss function. The approach is qualitatively different than traditional lattice techniques that rely on the time dependence of correlation functions that summarize the lattice configurations. The resulting estimate of the density matrix can then be used to evaluate the expectation of an arbitrary operator, which opens the door to new possibilities.