Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-contrastive sentence representations via self-supervision
Paper and Code
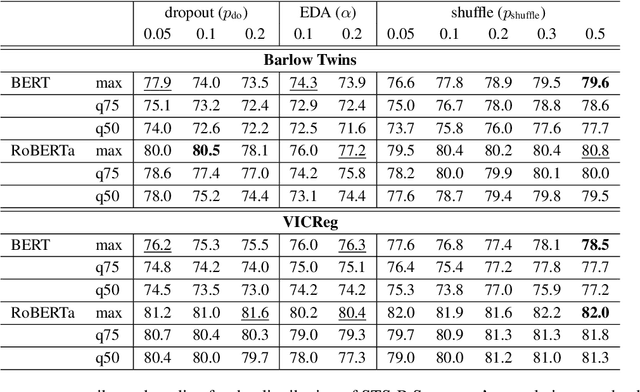
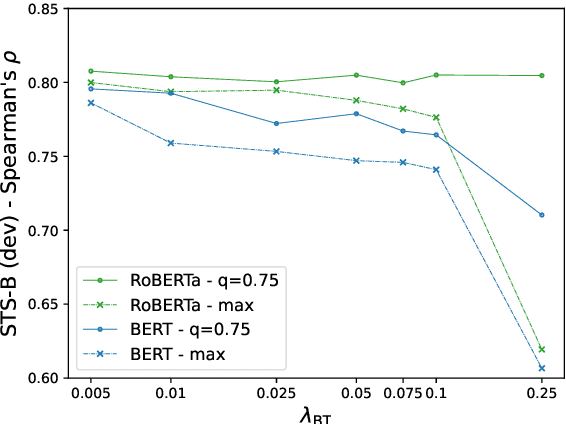
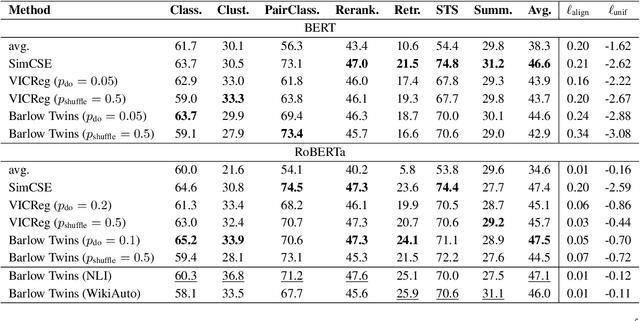
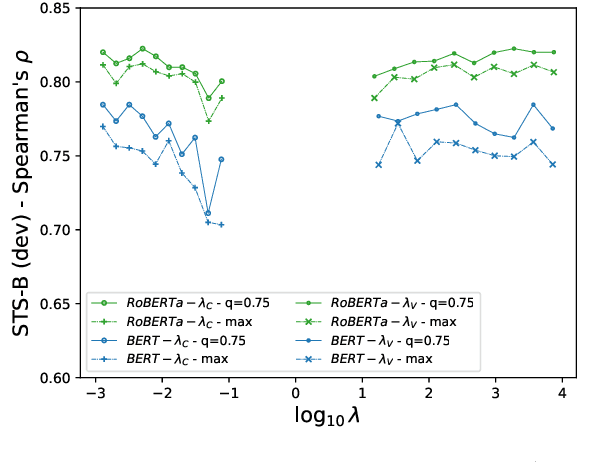
Sample contrastive methods, typically referred to simply as contrastive are the foundation of most unsupervised methods to learn text and sentence embeddings. On the other hand, a different class of self-supervised loss functions and methods have been considered in the computer vision community and referred to as dimension contrastive. In this paper, we thoroughly compare this class of methods with the standard baseline for contrastive sentence embeddings, SimCSE. We find that self-supervised embeddings trained using dimension contrastive objectives can outperform SimCSE on downstream tasks without needing auxiliary loss functions.
* Submitted and rejected by EMNLP 2023. Contact the authors for a copy
of the "reviews"
View paper on