 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024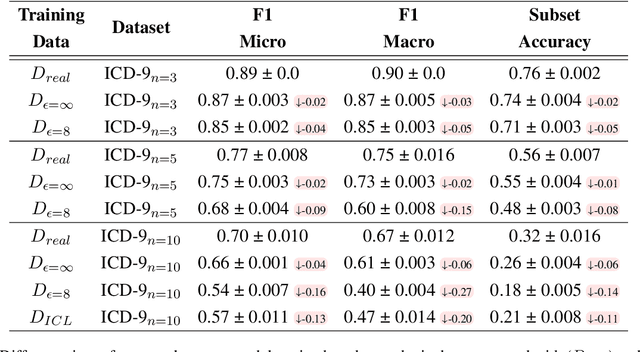


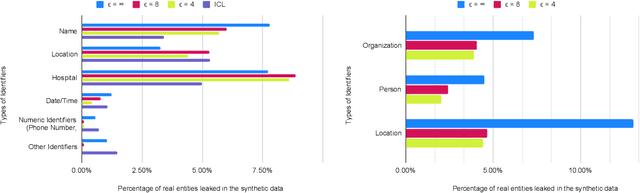
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
Analyzing the Limits of Self-Supervision in Handling Bias in Language
Dec 16, 2021



Prompting inputs with natural language task descriptions has emerged as a popular mechanism to elicit reasonably accurate outputs from large-scale generative language models with little to no in-context supervision. This also helps gain insight into how well language models capture the semantics of a wide range of downstream tasks purely from self-supervised pre-training on massive corpora of unlabeled text. Such models have naturally also been exposed to a lot of undesirable content like racist and sexist language and there is limited work on awareness of models along these dimensions. In this paper, we define and comprehensively evaluate how well such language models capture the semantics of four tasks for bias: diagnosis, identification, extraction and rephrasing. We define three broad classes of task descriptions for these tasks: statement, question, and completion, with numerous lexical variants within each class. We study the efficacy of prompting for each task using these classes and the null task description across several decoding methods and few-shot examples. Our analyses indicate that language models are capable of performing these tasks to widely varying degrees across different bias dimensions, such as gender and political affiliation. We believe our work is an important step towards unbiased language models by quantifying the limits of current self-supervision objectives at accomplishing such sociologically challenging tasks.
Disentangling Online Chats with DAG-Structured LSTMs
Jun 16, 2021
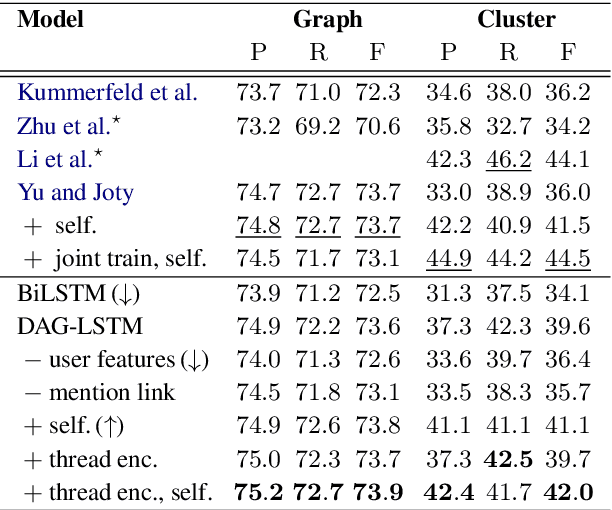
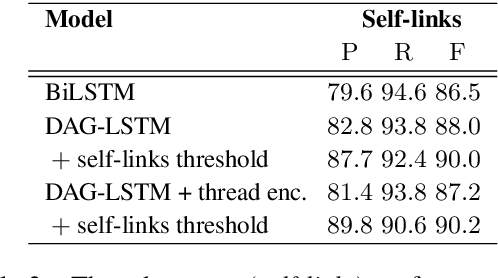

Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
Identify, Align, and Integrate: Matching Knowledge Graphs to Commonsense Reasoning Tasks
Apr 20, 2021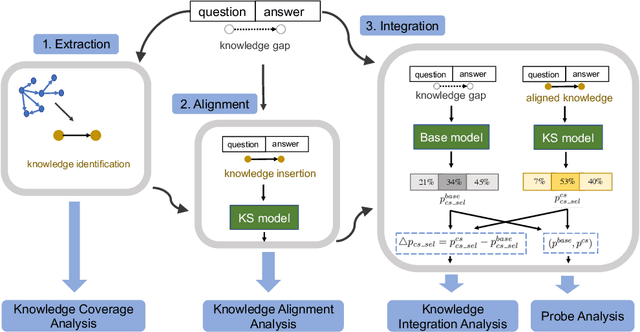

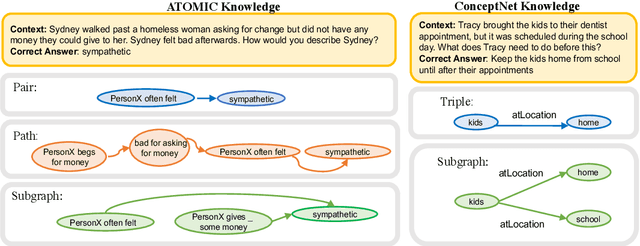
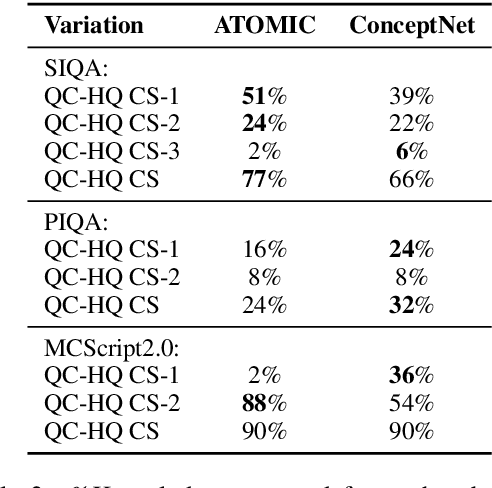
Integrating external knowledge into commonsense reasoning tasks has shown progress in resolving some, but not all, knowledge gaps in these tasks. For knowledge integration to yield peak performance, it is critical to select a knowledge graph (KG) that is well-aligned with the given task's objective. We present an approach to assess how well a candidate KG can correctly identify and accurately fill in gaps of reasoning for a task, which we call KG-to-task match. We show this KG-to-task match in 3 phases: knowledge-task identification, knowledge-task alignment, and knowledge-task integration. We also analyze our transformer-based KG-to-task models via commonsense probes to measure how much knowledge is captured in these models before and after KG integration. Empirically, we investigate KG matches for the SocialIQA (SIQA) (Sap et al., 2019b), Physical IQA (PIQA) (Bisk et al., 2020), and MCScript2.0 (Ostermann et al., 2019) datasets with 3 diverse KGs: ATOMIC (Sap et al., 2019a), ConceptNet (Speer et al., 2017), and an automatically constructed instructional KG based on WikiHow (Koupaee and Wang, 2018). With our methods we are able to demonstrate that ATOMIC, an event-inference focused KG, is the best match for SIQA and MCScript2.0, and that the taxonomic ConceptNet and WikiHow-based KGs are the best matches for PIQA across all 3 analysis phases. We verify our methods and findings with human evaluation.
ExplaGraphs: An Explanation Graph Generation Task for Structured Commonsense Reasoning
Apr 17, 2021

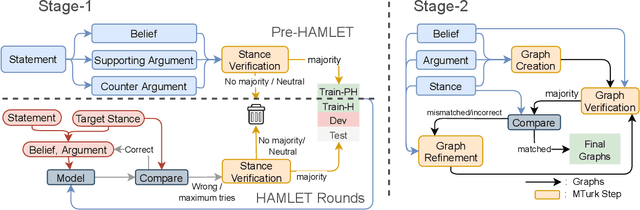

Recent commonsense-reasoning tasks are typically discriminative in nature, where a model answers a multiple-choice question for a certain context. Discriminative tasks are limiting because they fail to adequately evaluate the model's ability to reason and explain predictions with underlying commonsense knowledge. They also allow such models to use reasoning shortcuts and not be "right for the right reasons". In this work, we present ExplaGraphs, a new generative and structured commonsense-reasoning task (and an associated dataset) of explanation graph generation for stance prediction. Specifically, given a belief and an argument, a model has to predict whether the argument supports or counters the belief and also generate a commonsense-augmented graph that serves as non-trivial, complete, and unambiguous explanation for the predicted stance. The explanation graphs for our dataset are collected via crowdsourcing through a novel Collect-Judge-And-Refine graph collection framework that improves the graph quality via multiple rounds of verification and refinement. A significant 83% of our graphs contain external commonsense nodes with diverse structures and reasoning depths. We also propose a multi-level evaluation framework that checks for the structural and semantic correctness of the generated graphs and their plausibility with human-written graphs. We experiment with state-of-the-art text generation models like BART and T5 to generate explanation graphs and observe that there is a large gap with human performance, thereby encouraging useful future work for this new commonsense graph-based explanation generation task.
Commonsense for Generative Multi-Hop Question Answering Tasks
Sep 17, 2018



Reading comprehension QA tasks have seen a recent surge in popularity, yet most works have focused on fact-finding extractive QA. We instead focus on a more challenging multi-hop generative task (NarrativeQA), which requires the model to reason, gather, and synthesize disjoint pieces of information within the context to generate an answer. This type of multi-step reasoning also often requires understanding implicit relations, which humans resolve via external, background commonsense knowledge. We first present a strong generative baseline that uses a multi-attention mechanism to perform multiple hops of reasoning and a pointer-generator decoder to synthesize the answer. This model performs substantially better than previous generative models, and is competitive with current state-of-the-art span prediction models. We next introduce a novel system for selecting grounded multi-hop relational commonsense information from ConceptNet via a pointwise mutual information and term-frequency based scoring function. Finally, we effectively use this extracted commonsense information to fill in gaps of reasoning between context hops, using a selectively-gated attention mechanism. This boosts the model's performance significantly (also verified via human evaluation), establishing a new state-of-the-art for the task. We also show that our background knowledge enhancements are generalizable and improve performance on QAngaroo-WikiHop, another multi-hop reasoning dataset.