 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Instruct Models for Free: A Study on Partial Adaptation
Apr 15, 2025Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model being overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.
Distillation of encoder-decoder transformers for sequence labelling
Feb 10, 2023



Driven by encouraging results on a wide range of tasks, the field of NLP is experiencing an accelerated race to develop bigger language models. This race for bigger models has also underscored the need to continue the pursuit of practical distillation approaches that can leverage the knowledge acquired by these big models in a compute-efficient manner. Having this goal in mind, we build on recent work to propose a hallucination-free framework for sequence tagging that is especially suited for distillation. We show empirical results of new state-of-the-art performance across multiple sequence labelling datasets and validate the usefulness of this framework for distilling a large model in a few-shot learning scenario.
Weakly Supervised Headline Dependency Parsing
Jan 25, 2023



English news headlines form a register with unique syntactic properties that have been documented in linguistics literature since the 1930s. However, headlines have received surprisingly little attention from the NLP syntactic parsing community. We aim to bridge this gap by providing the first news headline corpus of Universal Dependencies annotated syntactic dependency trees, which enables us to evaluate existing state-of-the-art dependency parsers on news headlines. To improve English news headline parsing accuracies, we develop a projection method to bootstrap silver training data from unlabeled news headline-article lead sentence pairs. Models trained on silver headline parses demonstrate significant improvements in performance over models trained solely on gold-annotated long-form texts. Ultimately, we find that, although projected silver training data improves parser performance across different news outlets, the improvement is moderated by constructions idiosyncratic to outlet.
* Findings of EMNLP 2022
PathFinder: Discovering Decision Pathways in Deep Neural Networks
Oct 01, 2022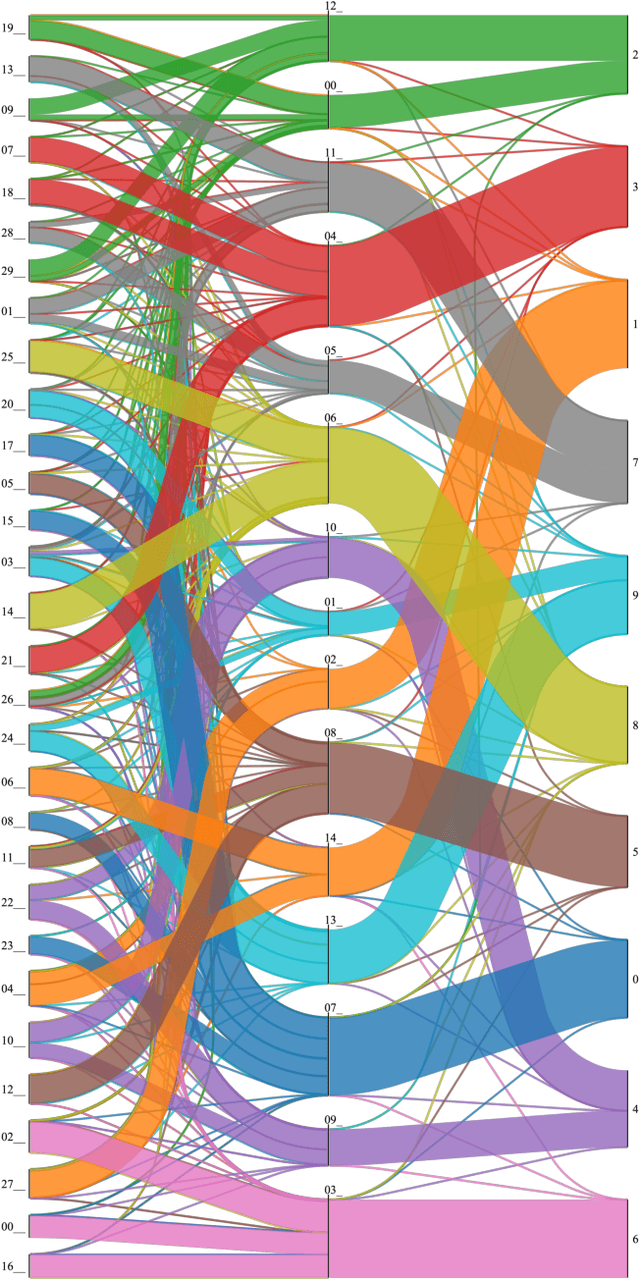

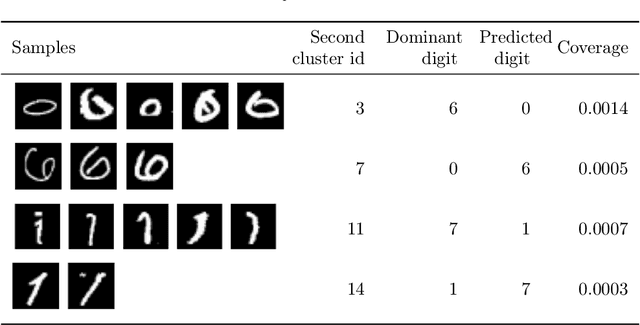
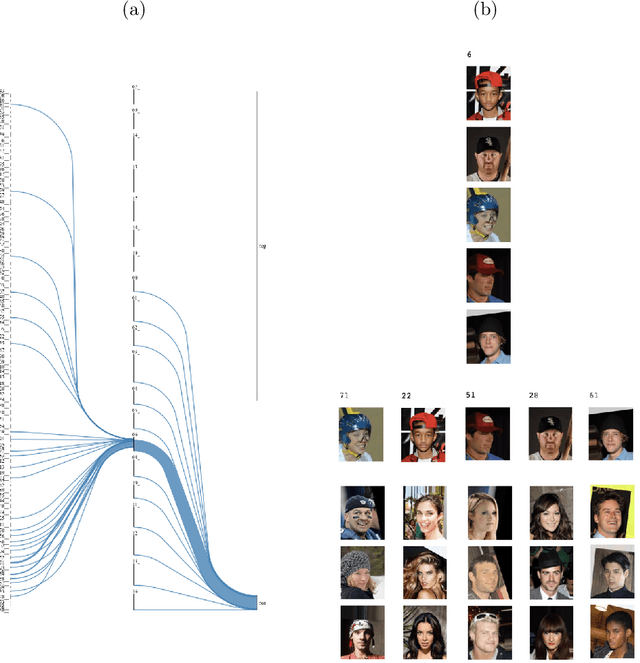
Explainability is becoming an increasingly important topic for deep neural networks. Though the operation in convolutional layers is easier to understand, processing becomes opaque in fully-connected layers. The basic idea in our work is that each instance, as it flows through the layers, causes a different activation pattern in the hidden layers and in our Paths methodology, we cluster these activation vectors for each hidden layer and then see how the clusters in successive layers connect to one another as activation flows from the input layer to the output. We find that instances of the same class follow a small number of cluster sequences over the layers, which we name ``decision paths." Such paths explain how classification decisions are typically made, and also help us determine outliers that follow unusual paths. We also propose using the Sankey diagram to visualize such pathways. We validate our method with experiments on two feed-forward networks trained on MNIST and CELEB data sets, and one recurrent network trained on PenDigits.
Disentangling Online Chats with DAG-Structured LSTMs
Jun 16, 2021
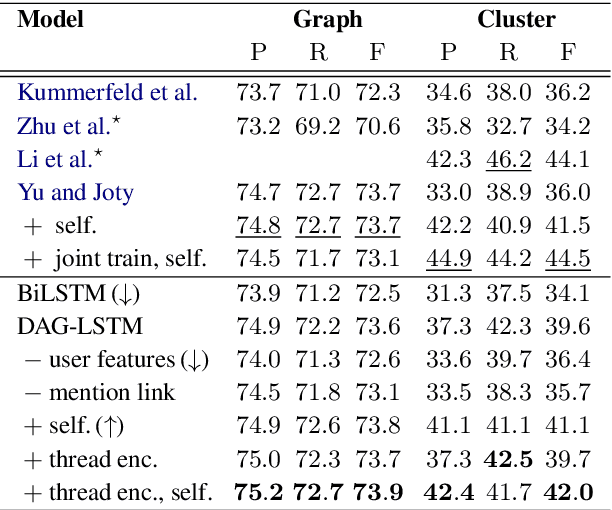
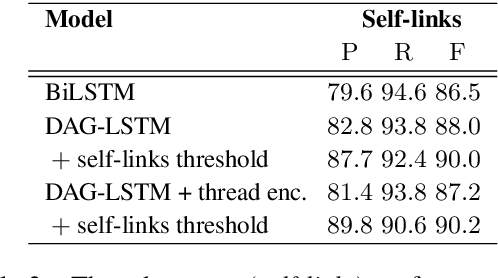

Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
Diversity-Aware Batch Active Learning for Dependency Parsing
Apr 28, 2021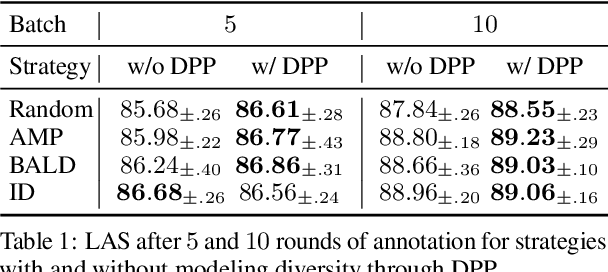
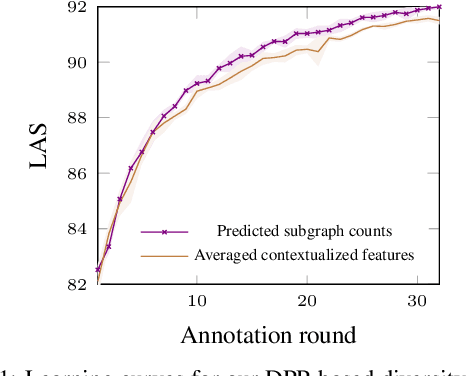
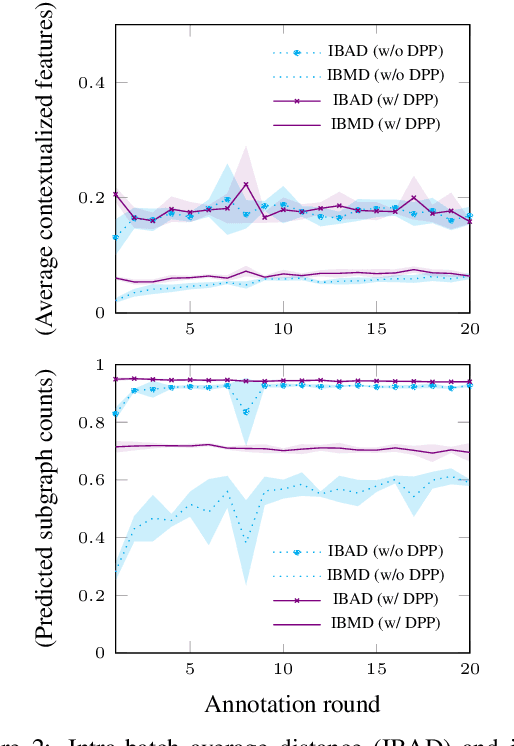
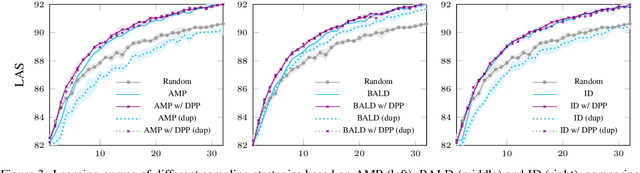
While the predictive performance of modern statistical dependency parsers relies heavily on the availability of expensive expert-annotated treebank data, not all annotations contribute equally to the training of the parsers. In this paper, we attempt to reduce the number of labeled examples needed to train a strong dependency parser using batch active learning (AL). In particular, we investigate whether enforcing diversity in the sampled batches, using determinantal point processes (DPPs), can improve over their diversity-agnostic counterparts. Simulation experiments on an English newswire corpus show that selecting diverse batches with DPPs is superior to strong selection strategies that do not enforce batch diversity, especially during the initial stages of the learning process. Additionally, our diversityaware strategy is robust under a corpus duplication setting, where diversity-agnostic sampling strategies exhibit significant degradation.
* NAACL 2021
Learning Syntax from Naturally-Occurring Bracketings
Apr 28, 2021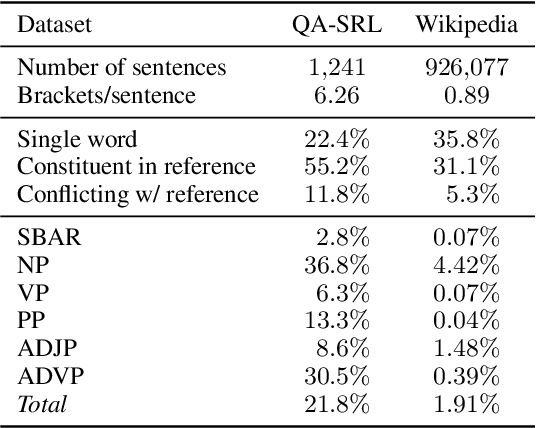
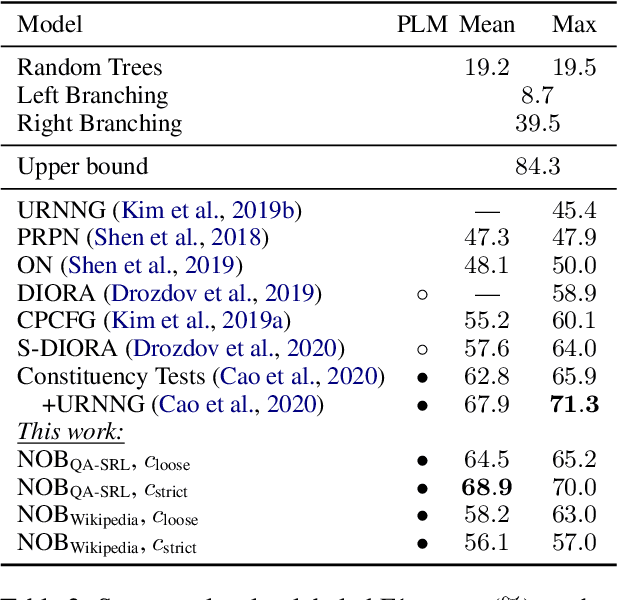
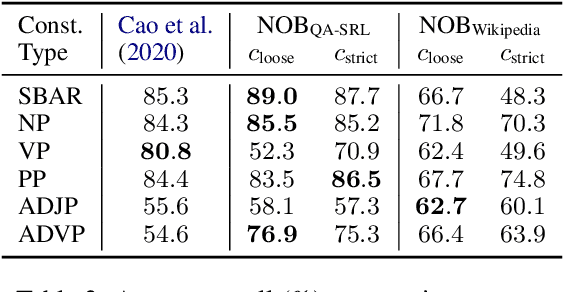
Naturally-occurring bracketings, such as answer fragments to natural language questions and hyperlinks on webpages, can reflect human syntactic intuition regarding phrasal boundaries. Their availability and approximate correspondence to syntax make them appealing as distant information sources to incorporate into unsupervised constituency parsing. But they are noisy and incomplete; to address this challenge, we develop a partial-brackets-aware structured ramp loss in learning. Experiments demonstrate that our distantly-supervised models trained on naturally-occurring bracketing data are more accurate in inducing syntactic structures than competing unsupervised systems. On the English WSJ corpus, our models achieve an unlabeled F1 score of 68.9 for constituency parsing.
* NAACL 2021
kōan: A Corrected CBOW Implementation
Dec 30, 2020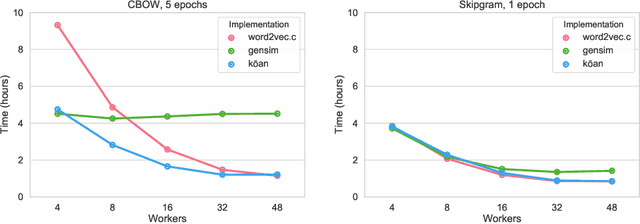

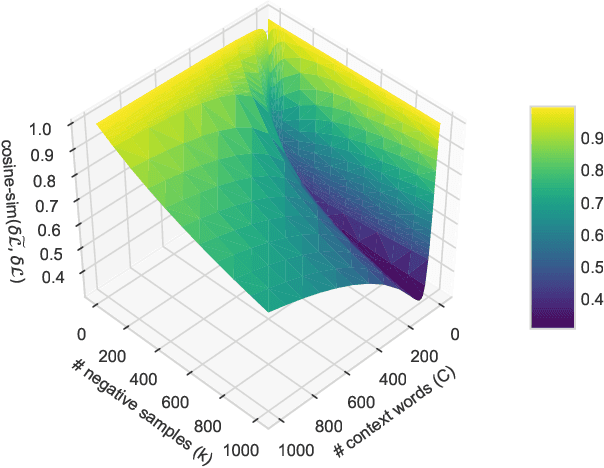
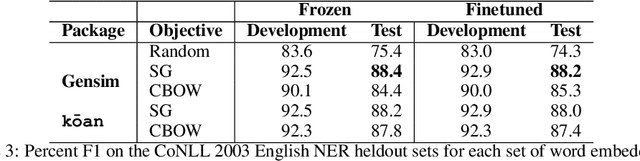
It is a common belief in the NLP community that continuous bag-of-words (CBOW) word embeddings tend to underperform skip-gram (SG) embeddings. We find that this belief is founded less on theoretical differences in their training objectives but more on faulty CBOW implementations in standard software libraries such as the official implementation word2vec.c and Gensim. We show that our correct implementation of CBOW yields word embeddings that are fully competitive with SG on various intrinsic and extrinsic tasks while being more than three times as fast to train. We release our implementation, k\=oan, at https://github.com/bloomberg/koan.
Semantic Role Labeling as Syntactic Dependency Parsing
Oct 21, 2020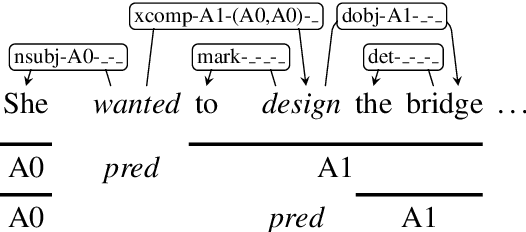
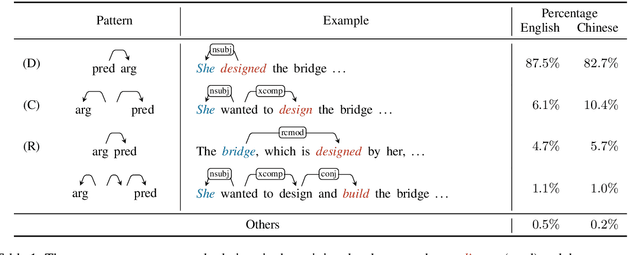
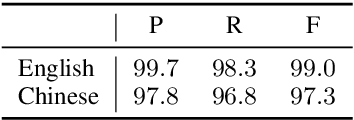
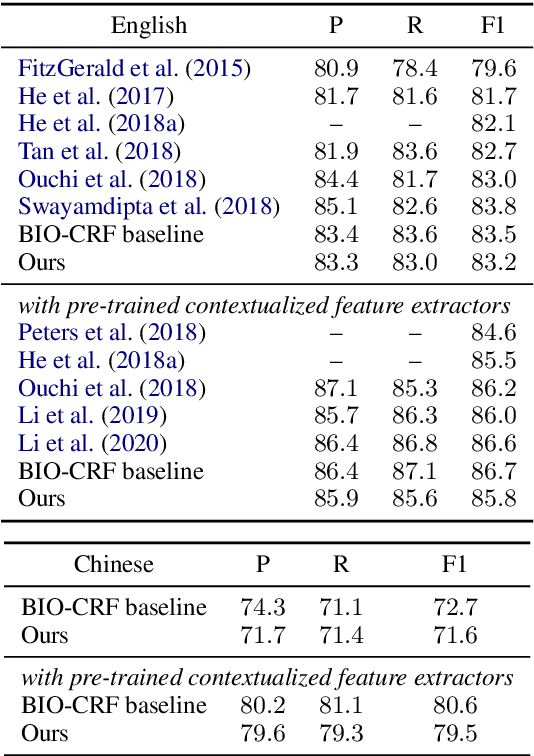
We reduce the task of (span-based) PropBank-style semantic role labeling (SRL) to syntactic dependency parsing. Our approach is motivated by our empirical analysis that shows three common syntactic patterns account for over 98% of the SRL annotations for both English and Chinese data. Based on this observation, we present a conversion scheme that packs SRL annotations into dependency tree representations through joint labels that permit highly accurate recovery back to the original format. This representation allows us to train statistical dependency parsers to tackle SRL and achieve competitive performance with the current state of the art. Our findings show the promise of syntactic dependency trees in encoding semantic role relations within their syntactic domain of locality, and point to potential further integration of syntactic methods into semantic role labeling in the future.
Dialogue Act Classification in Group Chats with DAG-LSTMs
Aug 02, 2019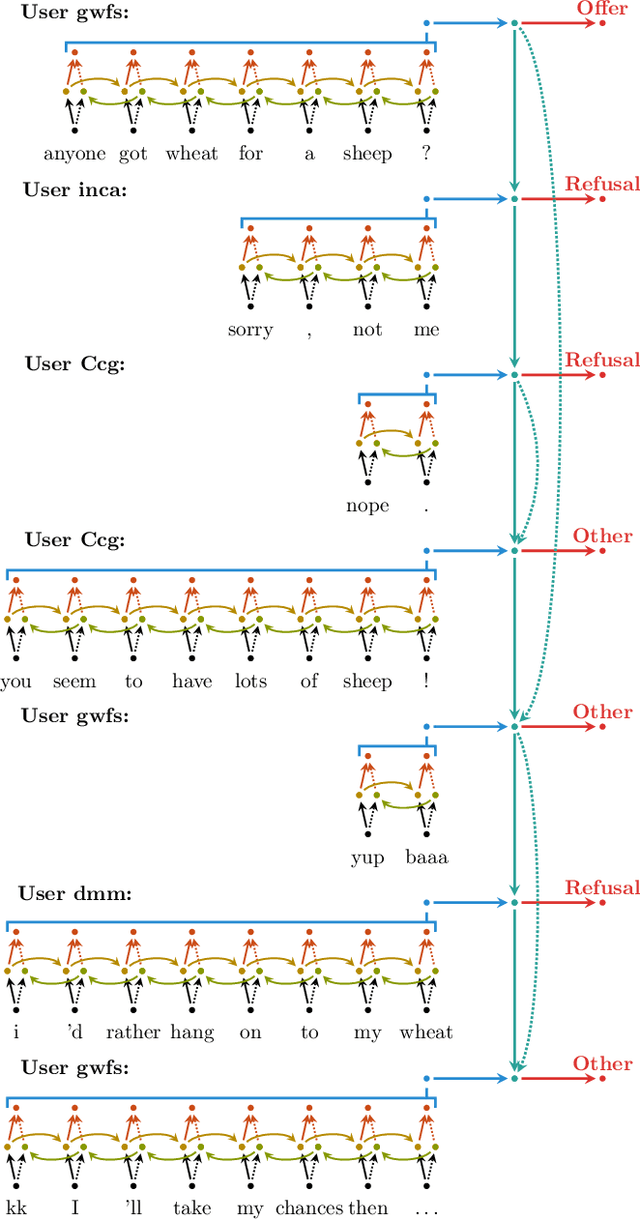
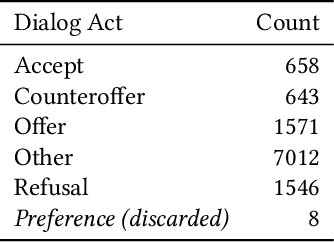

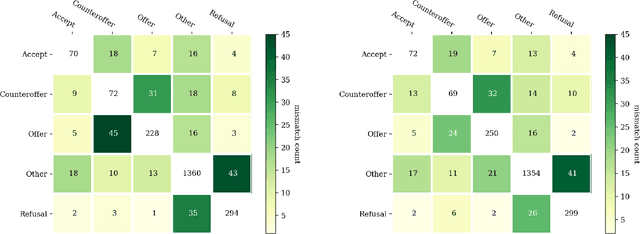
Dialogue act (DA) classification has been studied for the past two decades and has several key applications such as workflow automation and conversation analytics. Researchers have used, to address this problem, various traditional machine learning models, and more recently deep neural network models such as hierarchical convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. In this paper, we introduce a new model architecture, directed-acyclic-graph LSTM (DAG-LSTM) for DA classification. A DAG-LSTM exploits the turn-taking structure naturally present in a multi-party conversation, and encodes this relation in its model structure. Using the STAC corpus, we show that the proposed method performs roughly 0.8% better in accuracy and 1.2% better in macro-F1 score when compared to existing methods. The proposed method is generic and not limited to conversation applications.