 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathFinder: Discovering Decision Pathways in Deep Neural Networks
Paper and Code
Oct 01, 2022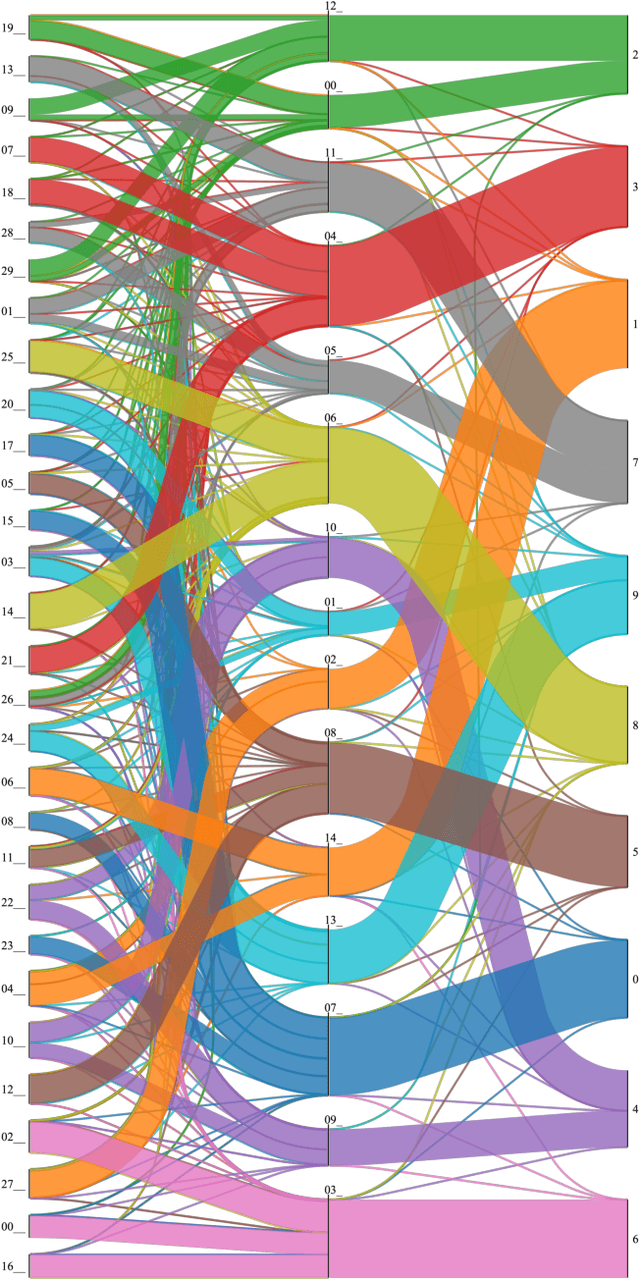

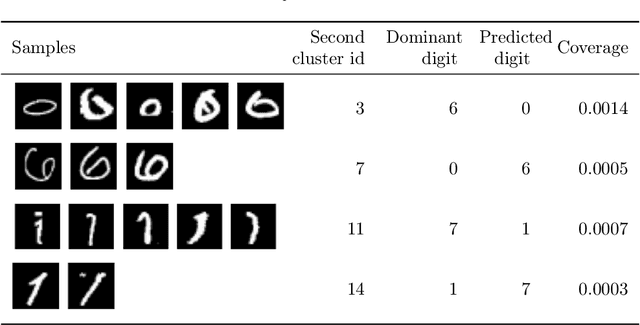
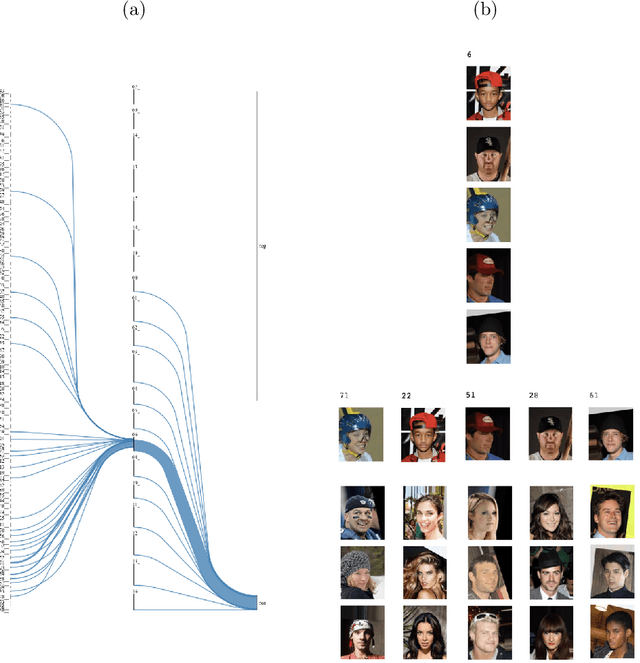
Explainability is becoming an increasingly important topic for deep neural networks. Though the operation in convolutional layers is easier to understand, processing becomes opaque in fully-connected layers. The basic idea in our work is that each instance, as it flows through the layers, causes a different activation pattern in the hidden layers and in our Paths methodology, we cluster these activation vectors for each hidden layer and then see how the clusters in successive layers connect to one another as activation flows from the input layer to the output. We find that instances of the same class follow a small number of cluster sequences over the layers, which we name ``decision paths." Such paths explain how classification decisions are typically made, and also help us determine outliers that follow unusual paths. We also propose using the Sankey diagram to visualize such pathways. We validate our method with experiments on two feed-forward networks trained on MNIST and CELEB data sets, and one recurrent network trained on PenDigits.