 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Context for Predicting Citation Worthiness of Sentences in Scholarly Articles
Apr 18, 2021
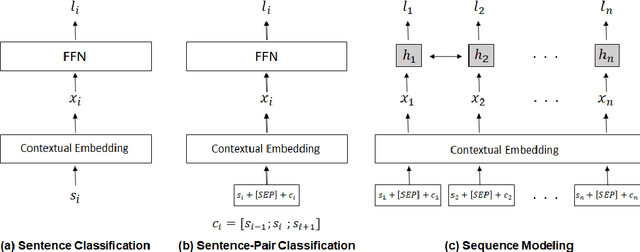
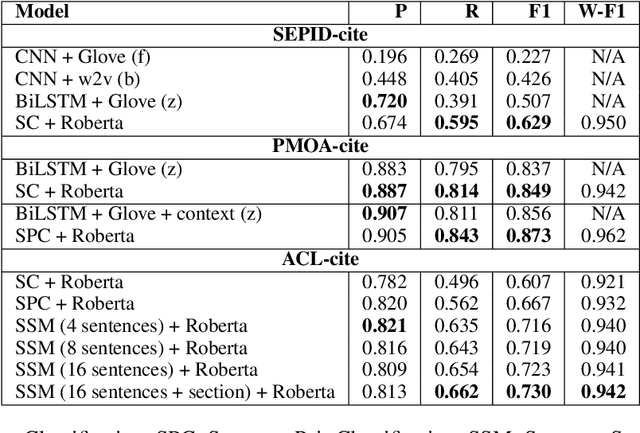
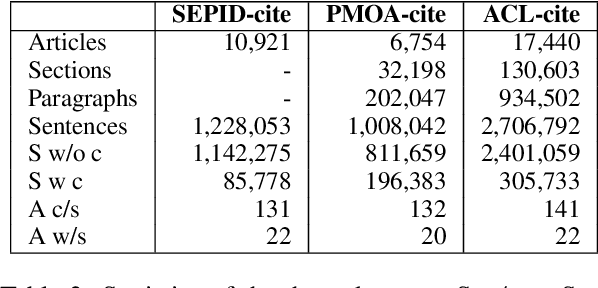
In this paper, we study the importance of context in predicting the citation worthiness of sentences in scholarly articles. We formulate this problem as a sequence labeling task solved using a hierarchical BiLSTM model. We contribute a new benchmark dataset containing over two million sentences and their corresponding labels. We preserve the sentence order in this dataset and perform document-level train/test splits, which importantly allows incorporating contextual information in the modeling process. We evaluate the proposed approach on three benchmark datasets. Our results quantify the benefits of using context and contextual embeddings for citation worthiness. Lastly, through error analysis, we provide insights into cases where context plays an essential role in predicting citation worthiness.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021



Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset
MIDAS at SemEval-2020 Task 10: Emphasis Selection using Label Distribution Learning and Contextual Embeddings
Sep 06, 2020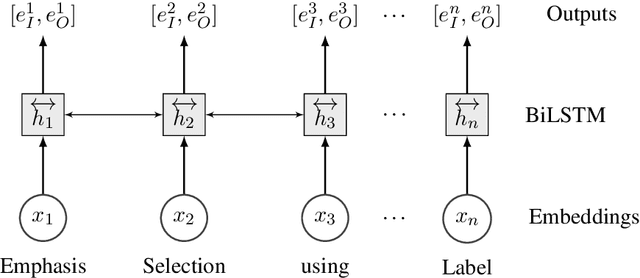
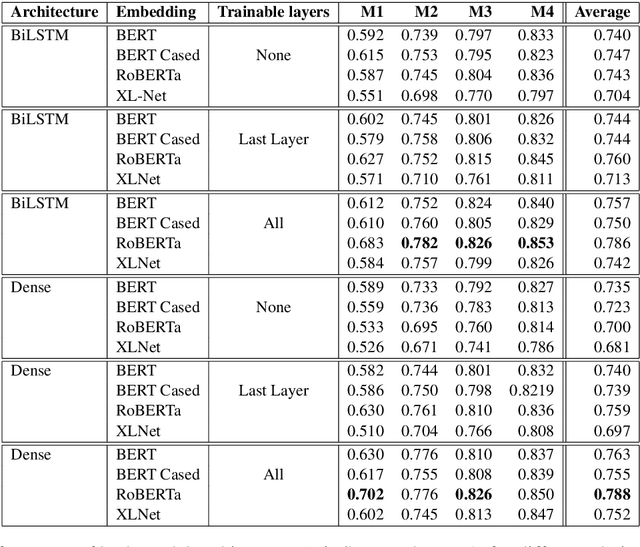


This paper presents our submission to the SemEval 2020 - Task 10 on emphasis selection in written text. We approach this emphasis selection problem as a sequence labeling task where we represent the underlying text with various contextual embedding models. We also employ label distribution learning to account for annotator disagreements. We experiment with the choice of model architectures, trainability of layers, and different contextual embeddings. Our best performing architecture is an ensemble of different models, which achieved an overall matching score of 0.783, placing us 15th out of 31 participating teams. Lastly, we analyze the results in terms of parts of speech tags, sentence lengths, and word ordering.
#MeTooMA: Multi-Aspect Annotations of Tweets Related to the MeToo Movement
Dec 14, 2019
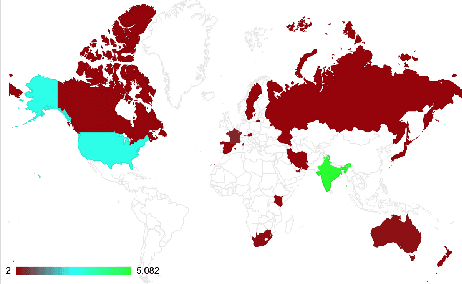

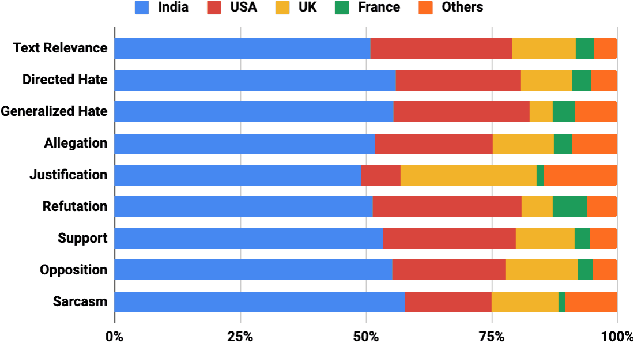
In this paper, we present a dataset containing 9,973 tweets related to the MeToo movement that were manually annotated for five different linguistic aspects: relevance, stance, hate speech, sarcasm, and dialogue acts. We present a detailed account of the data collection and annotation processes. The annotations have a very high inter-annotator agreement (0.79 to 0.93 k-alpha) due to the domain expertise of the annotators and clear annotation instructions. We analyze the data in terms of geographical distribution, label correlations, and keywords. Lastly, we present some potential use cases of this dataset. We expect this dataset would be of great interest to psycholinguists, socio-linguists, and computational linguists to study the discursive space of digitally mobilized social movements on sensitive issues like sexual harassment.
Keyphrase Extraction from Scholarly Articles as Sequence Labeling using Contextualized Embeddings
Oct 19, 2019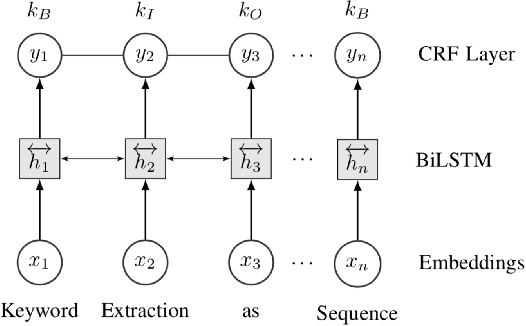
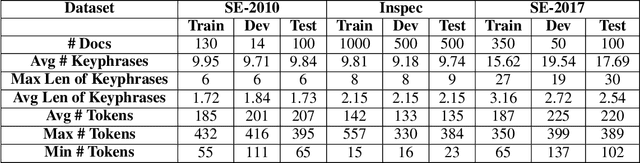
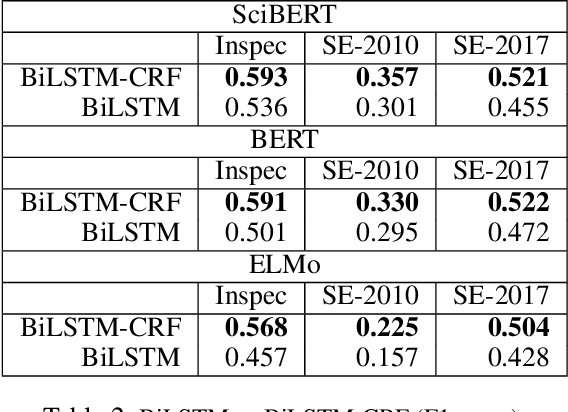
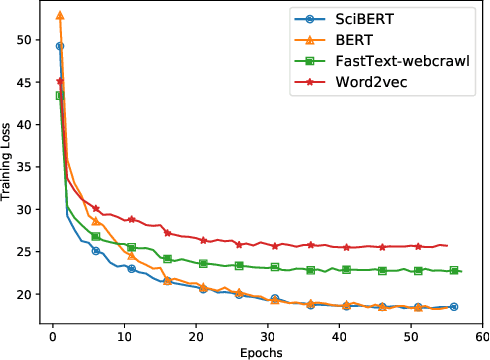
In this paper, we formulate keyphrase extraction from scholarly articles as a sequence labeling task solved using a BiLSTM-CRF, where the words in the input text are represented using deep contextualized embeddings. We evaluate the proposed architecture using both contextualized and fixed word embedding models on three different benchmark datasets (Inspec, SemEval 2010, SemEval 2017) and compare with existing popular unsupervised and supervised techniques. Our results quantify the benefits of (a) using contextualized embeddings (e.g. BERT) over fixed word embeddings (e.g. Glove); (b) using a BiLSTM-CRF architecture with contextualized word embeddings over fine-tuning the contextualized word embedding model directly, and (c) using genre-specific contextualized embeddings (SciBERT). Through error analysis, we also provide some insights into why particular models work better than others. Lastly, we present a case study where we analyze different self-attention layers of the two best models (BERT and SciBERT) to better understand the predictions made by each for the task of keyphrase extraction.
Keyphrase Generation for Scientific Articles using GANs
Sep 24, 2019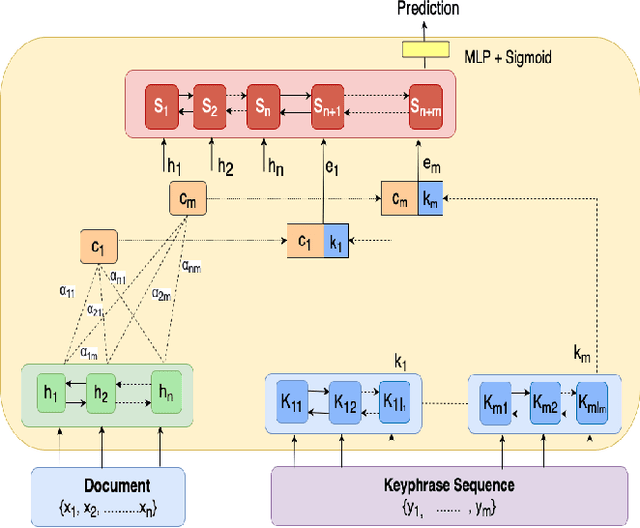
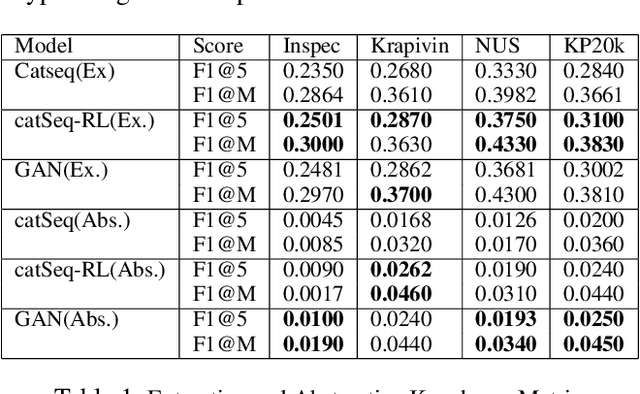
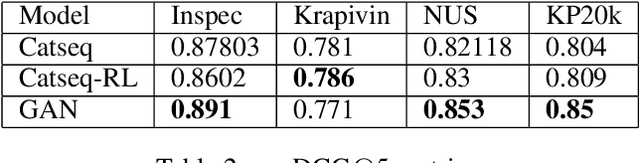
In this paper, we present a keyphrase generation approach using conditional Generative Adversarial Networks (GAN). In our GAN model, the generator outputs a sequence of keyphrases based on the title and abstract of a scientific article. The discriminator learns to distinguish between machine-generated and human-curated keyphrases. We evaluate this approach on standard benchmark datasets. Our model achieves state-of-the-art performance in generation of abstractive keyphrases and is also comparable to the best performing extractive techniques. We also demonstrate that our method generates more diverse keyphrases and make our implementation publicly available.
Dialogue Act Classification in Group Chats with DAG-LSTMs
Aug 02, 2019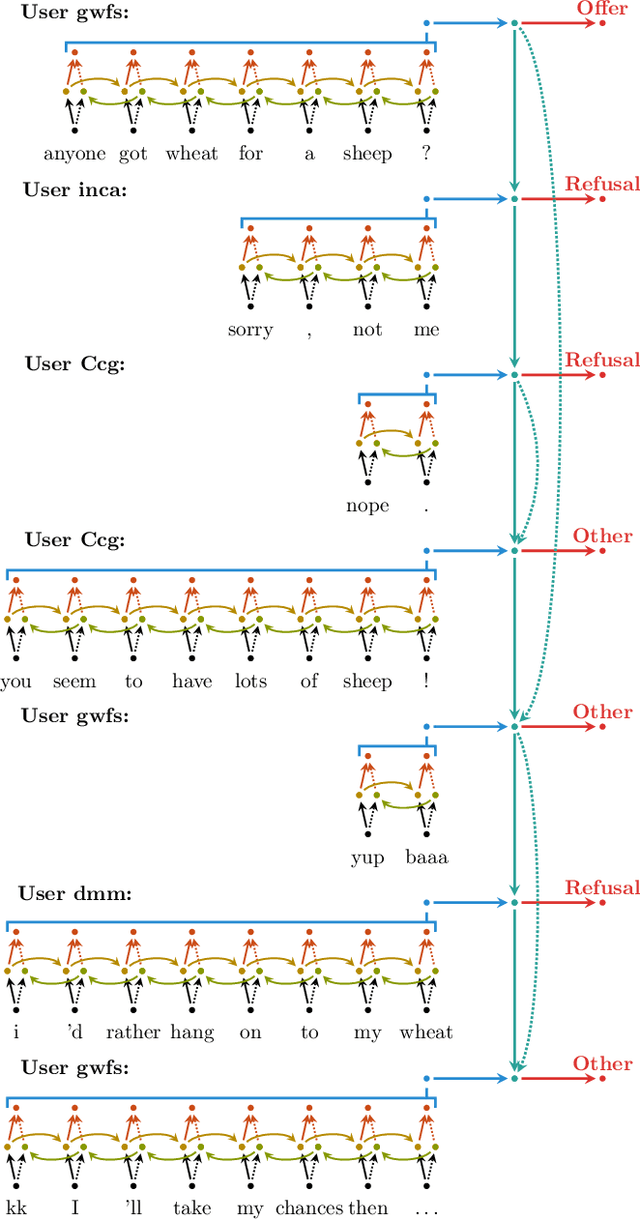
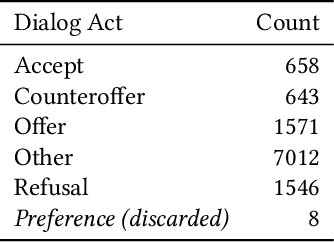

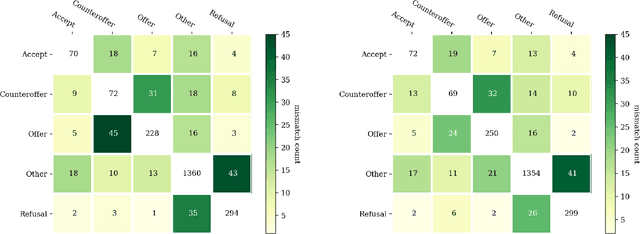
Dialogue act (DA) classification has been studied for the past two decades and has several key applications such as workflow automation and conversation analytics. Researchers have used, to address this problem, various traditional machine learning models, and more recently deep neural network models such as hierarchical convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. In this paper, we introduce a new model architecture, directed-acyclic-graph LSTM (DAG-LSTM) for DA classification. A DAG-LSTM exploits the turn-taking structure naturally present in a multi-party conversation, and encodes this relation in its model structure. Using the STAC corpus, we show that the proposed method performs roughly 0.8% better in accuracy and 1.2% better in macro-F1 score when compared to existing methods. The proposed method is generic and not limited to conversation applications.