 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Selection for Analyzing Conversations with Autism Spectrum Disorder
Jan 18, 2024



The diagnosis of autism spectrum disorder (ASD) is a complex, challenging task as it depends on the analysis of interactional behaviors by psychologists rather than the use of biochemical diagnostics. In this paper, we present a modeling approach to ASD diagnosis by analyzing acoustic/prosodic and linguistic features extracted from diagnostic conversations between a psychologist and children who either are typically developing (TD) or have ASD. We compare the contributions of different features across a range of conversation tasks. We focus on finding a minimal set of parameters that characterize conversational behaviors of children with ASD. Because ASD is diagnosed through conversational interaction, in addition to analyzing the behavior of the children, we also investigate whether the psychologist's conversational behaviors vary across diagnostic groups. Our results can facilitate fine-grained analysis of conversation data for children with ASD to support diagnosis and intervention.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
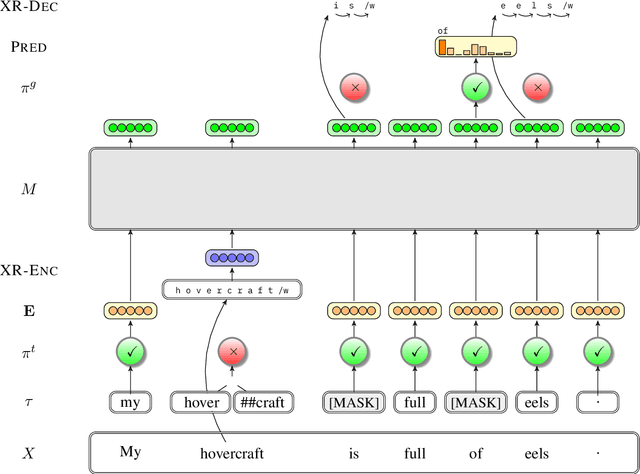


Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
LIFI: Towards Linguistically Informed Frame Interpolation
Nov 11, 2020
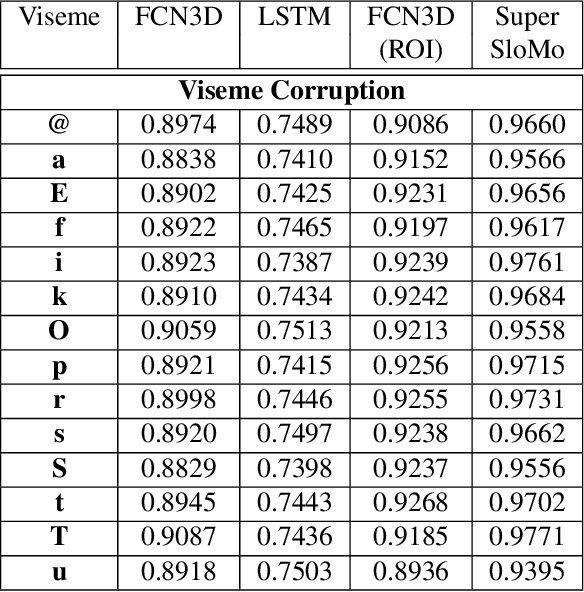
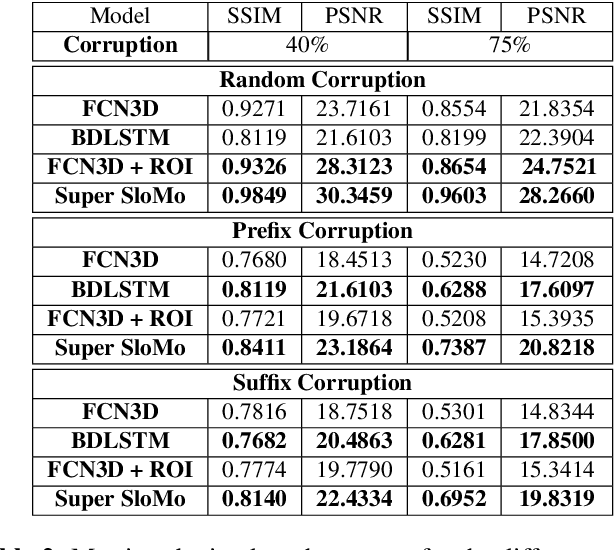

In this work, we explore a new problem of frame interpolation for speech videos. Such content today forms the major form of online communication. We try to solve this problem by using several deep learning video generation algorithms to generate the missing frames. We also provide examples where computer vision models despite showing high performance on conventional non-linguistic metrics fail to accurately produce faithful interpolation of speech. With this motivation, we provide a new set of linguistically-informed metrics specifically targeted to the problem of speech videos interpolation. We also release several datasets to test computer vision video generation models of their speech understanding.
Keyphrase Extraction from Scholarly Articles as Sequence Labeling using Contextualized Embeddings
Oct 19, 2019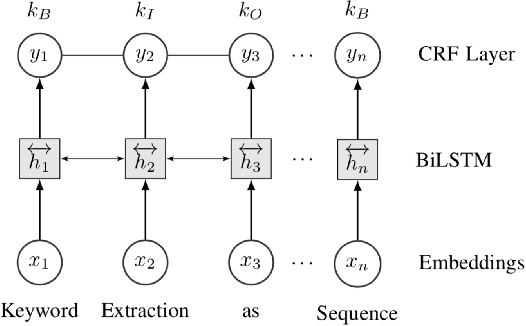
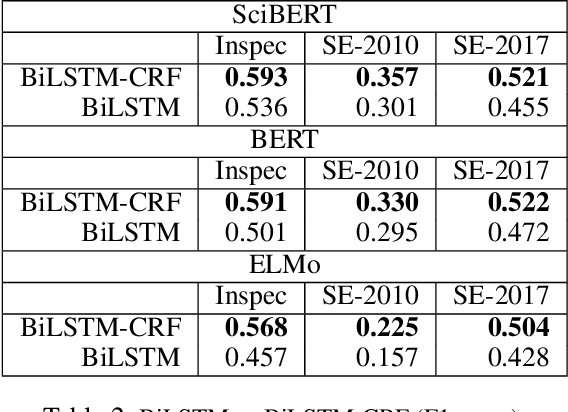
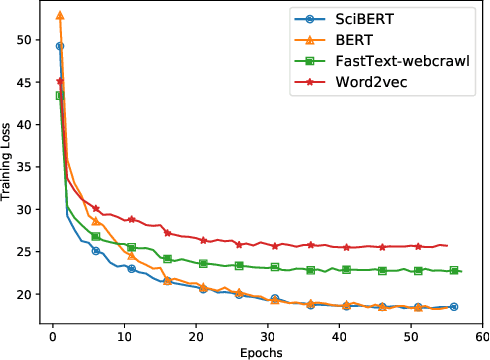
In this paper, we formulate keyphrase extraction from scholarly articles as a sequence labeling task solved using a BiLSTM-CRF, where the words in the input text are represented using deep contextualized embeddings. We evaluate the proposed architecture using both contextualized and fixed word embedding models on three different benchmark datasets (Inspec, SemEval 2010, SemEval 2017) and compare with existing popular unsupervised and supervised techniques. Our results quantify the benefits of (a) using contextualized embeddings (e.g. BERT) over fixed word embeddings (e.g. Glove); (b) using a BiLSTM-CRF architecture with contextualized word embeddings over fine-tuning the contextualized word embedding model directly, and (c) using genre-specific contextualized embeddings (SciBERT). Through error analysis, we also provide some insights into why particular models work better than others. Lastly, we present a case study where we analyze different self-attention layers of the two best models (BERT and SciBERT) to better understand the predictions made by each for the task of keyphrase extraction.
Modeling financial analysts' decision making via the pragmatics and semantics of earnings calls
Jun 24, 2019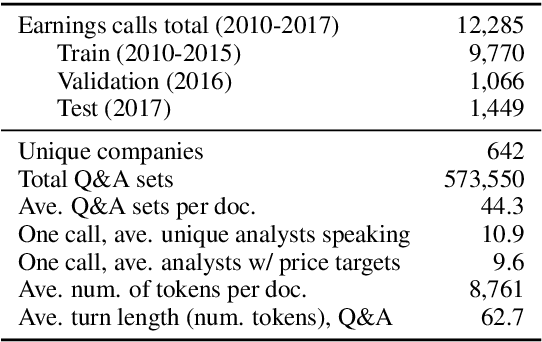
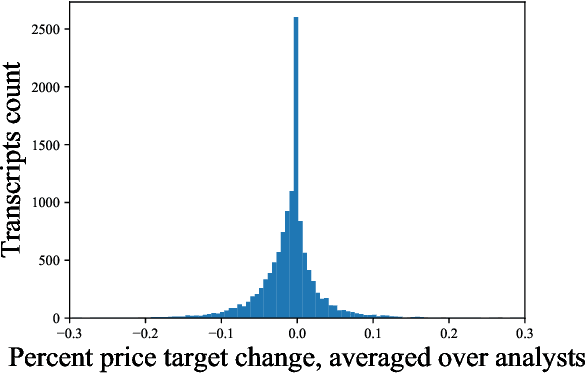

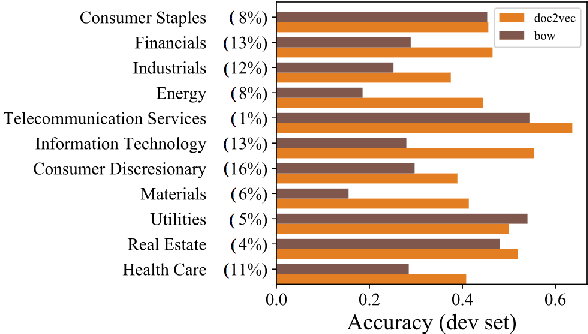
Every fiscal quarter, companies hold earnings calls in which company executives respond to questions from analysts. After these calls, analysts often change their price target recommendations, which are used in equity research reports to help investors make decisions. In this paper, we examine analysts' decision making behavior as it pertains to the language content of earnings calls. We identify a set of 20 pragmatic features of analysts' questions which we correlate with analysts' pre-call investor recommendations. We also analyze the degree to which semantic and pragmatic features from an earnings call complement market data in predicting analysts' post-call changes in price targets. Our results show that earnings calls are moderately predictive of analysts' decisions even though these decisions are influenced by a number of other factors including private communication with company executives and market conditions. A breakdown of model errors indicates disparate performance on calls from different market sectors.
MobiVSR: A Visual Speech Recognition Solution for Mobile Devices
Jun 05, 2019
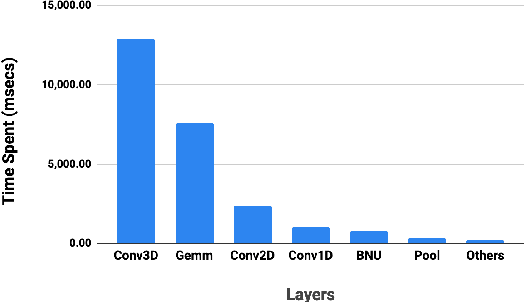


Visual speech recognition (VSR) is the task of recognizing spoken language from video input only, without any audio. VSR has many applications as an assistive technology, especially if it could be deployed in mobile devices and embedded systems. The need of intensive computational resources and large memory footprint are two of the major obstacles in developing neural network models for VSR in a resource constrained environment. We propose a novel end-to-end deep neural network architecture for word level VSR called MobiVSR with a design parameter that aids in balancing the model's accuracy and parameter count. We use depthwise-separable 3D convolution for the first time in the domain of VSR and show how it makes our model efficient. MobiVSR achieves an accuracy of 73\% on a challenging Lip Reading in the Wild dataset with 6 times fewer parameters and 20 times lesser memory footprint than the current state of the art. MobiVSR can also be compressed to 6 MB by applying post training quantization.
Humor in Collective Discourse: Unsupervised Funniness Detection in the New Yorker Cartoon Caption Contest
Jun 26, 2015
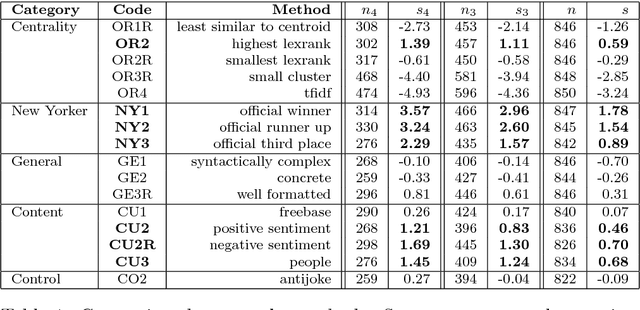


The New Yorker publishes a weekly captionless cartoon. More than 5,000 readers submit captions for it. The editors select three of them and ask the readers to pick the funniest one. We describe an experiment that compares a dozen automatic methods for selecting the funniest caption. We show that negative sentiment, human-centeredness, and lexical centrality most strongly match the funniest captions, followed by positive sentiment. These results are useful for understanding humor and also in the design of more engaging conversational agents in text and multimodal (vision+text) systems. As part of this work, a large set of cartoons and captions is being made available to the community.