 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Paper and Code
Aug 01, 2021
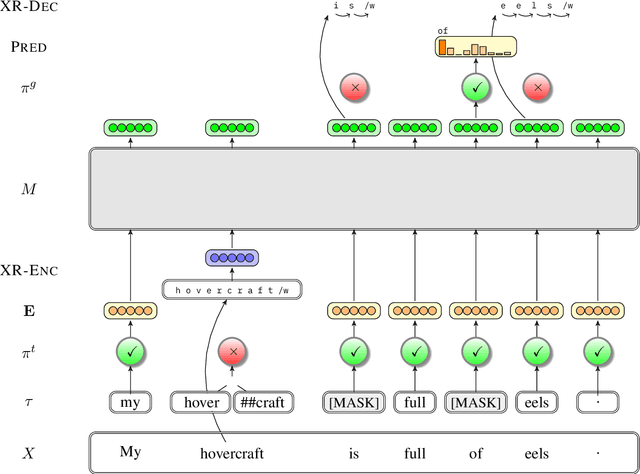


Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.