Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFI: Towards Linguistically Informed Frame Interpolation
Nov 11, 2020
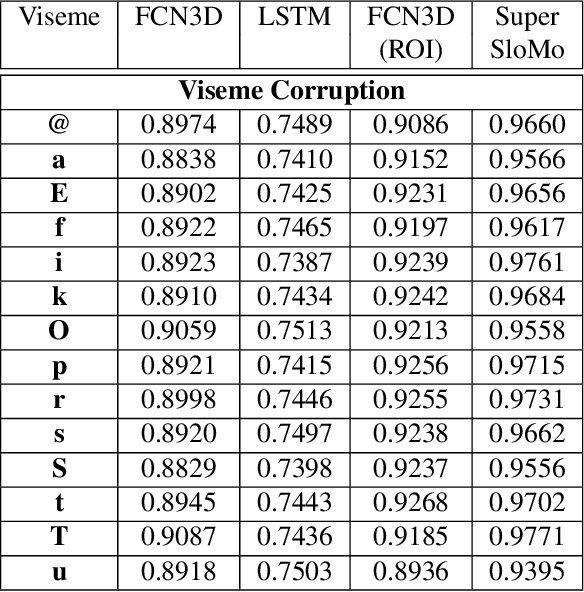
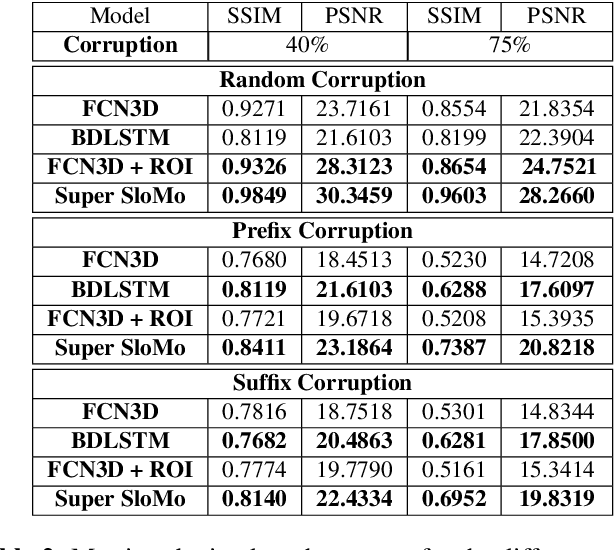

In this work, we explore a new problem of frame interpolation for speech videos. Such content today forms the major form of online communication. We try to solve this problem by using several deep learning video generation algorithms to generate the missing frames. We also provide examples where computer vision models despite showing high performance on conventional non-linguistic metrics fail to accurately produce faithful interpolation of speech. With this motivation, we provide a new set of linguistically-informed metrics specifically targeted to the problem of speech videos interpolation. We also release several datasets to test computer vision video generation models of their speech understanding.
* 9 pages, 7 tables, 4 figures
Via