 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Notic My Speech" -- Blending Speech Patterns With Multimedia
Jun 12, 2020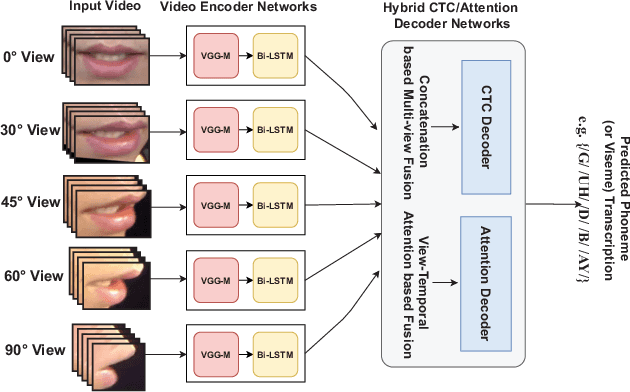
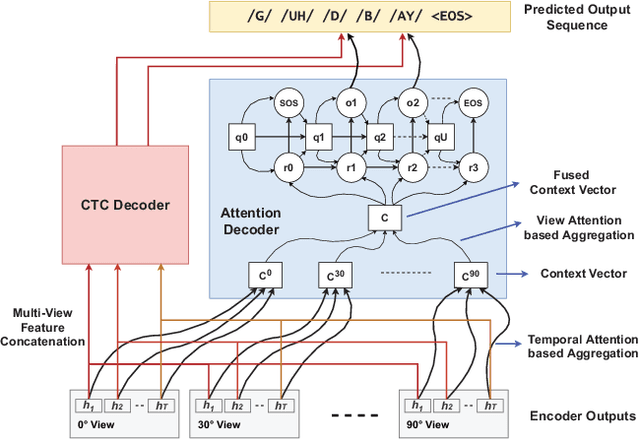
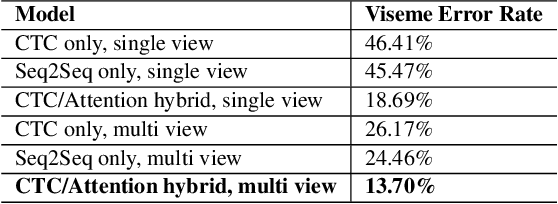
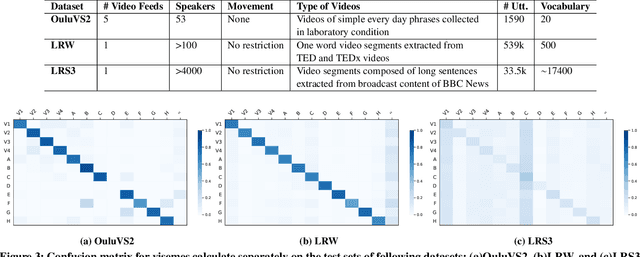
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.
Heterogeneity Loss to Handle Intersubject and Intrasubject Variability in Cancer
Mar 19, 2020

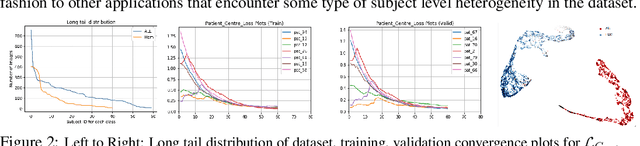
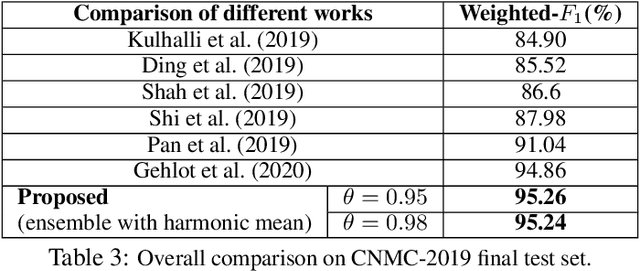
Developing nations lack adequate number of hospitals with modern equipment and skilled doctors. Hence, a significant proportion of these nations' population, particularly in rural areas, is not able to avail specialized and timely healthcare facilities. In recent years, deep learning (DL) models, a class of artificial intelligence (AI) methods, have shown impressive results in medical domain. These AI methods can provide immense support to developing nations as affordable healthcare solutions. This work is focused on one such application of blood cancer diagnosis. However, there are some challenges to DL models in cancer research because of the unavailability of a large data for adequate training and the difficulty of capturing heterogeneity in data at different levels ranging from acquisition characteristics, session, to subject-level (within subjects and across subjects). These challenges render DL models prone to overfitting and hence, models lack generalization on prospective subjects' data. In this work, we address these problems in the application of B-cell Acute Lymphoblastic Leukemia (B-ALL) diagnosis using deep learning. We propose heterogeneity loss that captures subject-level heterogeneity, thereby, forcing the neural network to learn subject-independent features. We also propose an unorthodox ensemble strategy that helps us in providing improved classification over models trained on 7-folds giving a weighted-$F_1$ score of 95.26% on unseen (test) subjects' data that are, so far, the best results on the C-NMC 2019 dataset for B-ALL classification.
Keyphrase Extraction from Scholarly Articles as Sequence Labeling using Contextualized Embeddings
Oct 19, 2019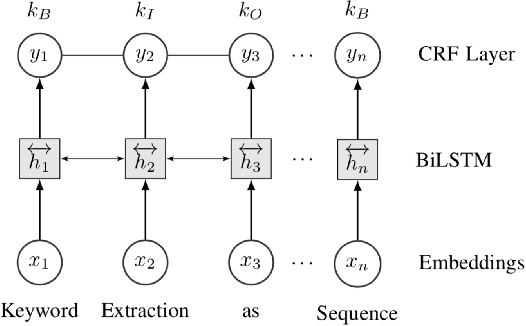
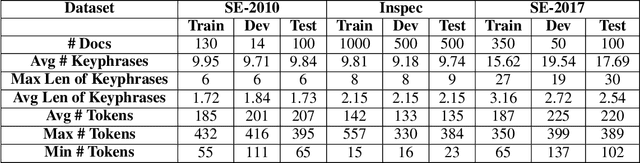
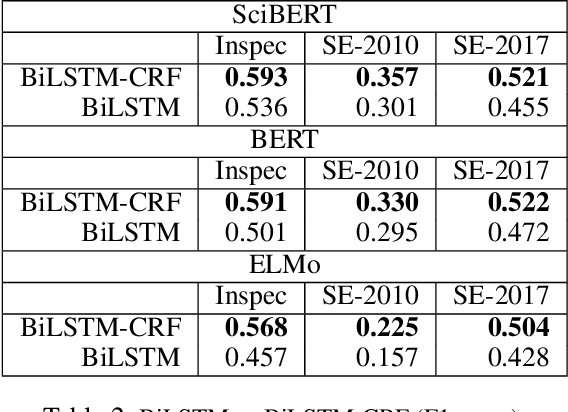
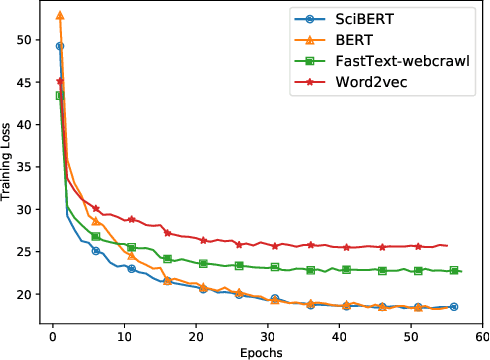
In this paper, we formulate keyphrase extraction from scholarly articles as a sequence labeling task solved using a BiLSTM-CRF, where the words in the input text are represented using deep contextualized embeddings. We evaluate the proposed architecture using both contextualized and fixed word embedding models on three different benchmark datasets (Inspec, SemEval 2010, SemEval 2017) and compare with existing popular unsupervised and supervised techniques. Our results quantify the benefits of (a) using contextualized embeddings (e.g. BERT) over fixed word embeddings (e.g. Glove); (b) using a BiLSTM-CRF architecture with contextualized word embeddings over fine-tuning the contextualized word embedding model directly, and (c) using genre-specific contextualized embeddings (SciBERT). Through error analysis, we also provide some insights into why particular models work better than others. Lastly, we present a case study where we analyze different self-attention layers of the two best models (BERT and SciBERT) to better understand the predictions made by each for the task of keyphrase extraction.
Harnessing GANs for Addition of New Classes in VSR
Jan 30, 2019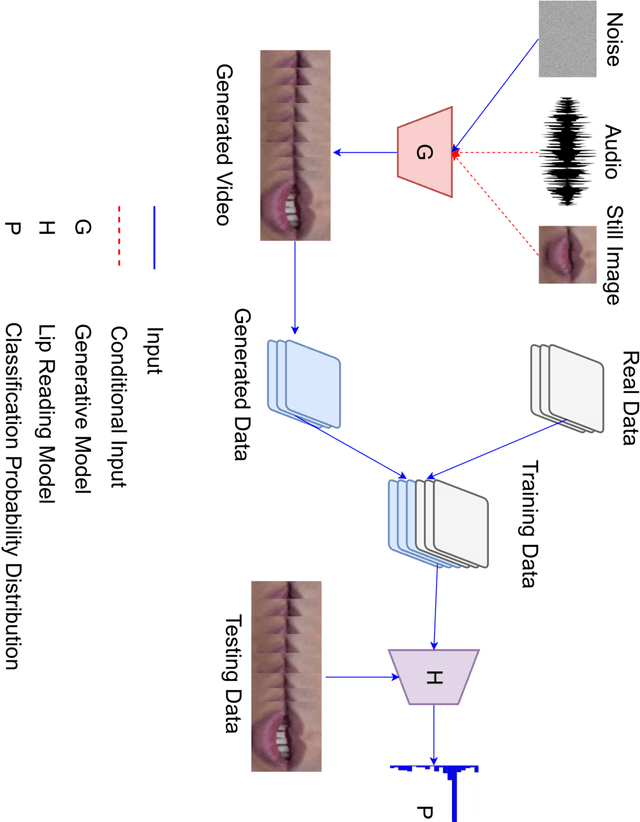
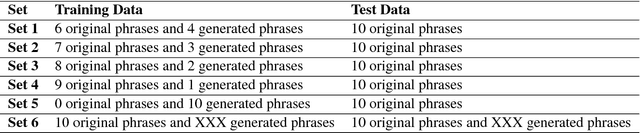
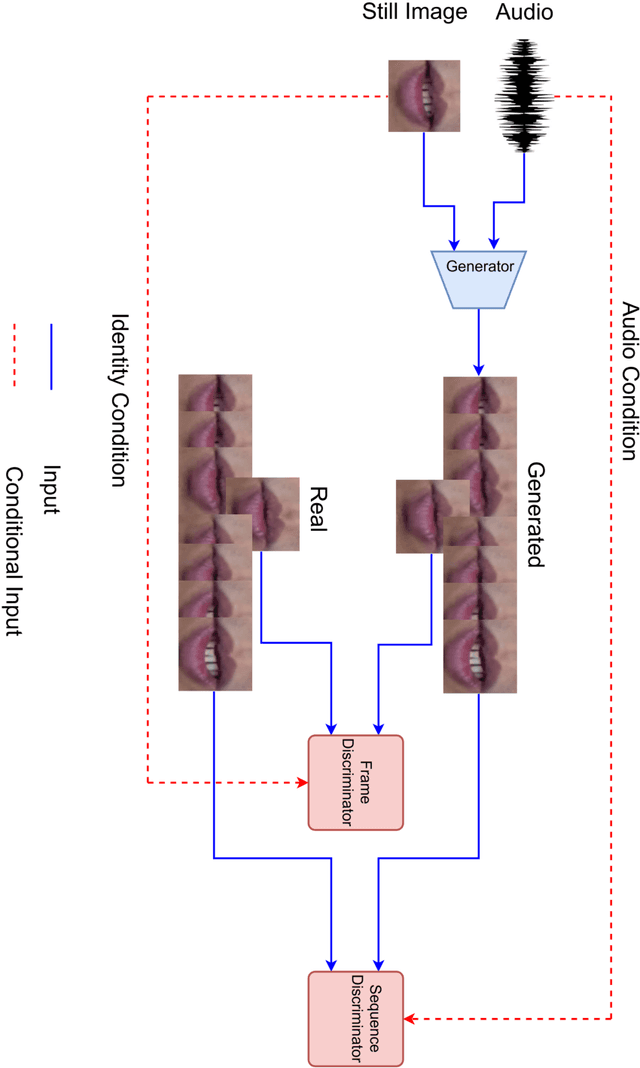
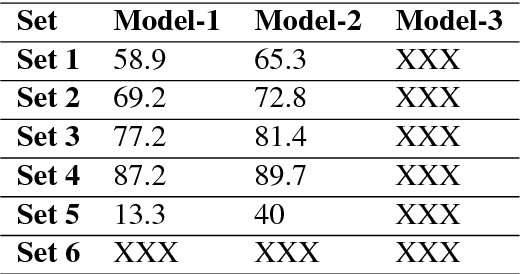
It is an easy task for humans to learn and generalize a problem, perhaps it is due to their ability to visualize and imagine unseen objects and concepts. The power of imagination comes handy especially when interpolating learnt experience (like seen examples) over new classes of a problem. For a machine learning system, acquiring such powers of imagination are still a hard task. We present a novel approach to low-shot learning that uses the idea of imagination over unseen classes in a classification problem setting. We combine a classifier with a `visionary' (i.e., a GAN model) that teaches the classifier to generalize itself over new and unseen classes. This approach can be incorporated into a variety of problem settings where we need a classifier to learn and generalize itself to new and unseen classes. We compare the performance of classifiers with and without the visionary GAN model helping them.