 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Notic My Speech" -- Blending Speech Patterns With Multimedia
Paper and Code
Jun 12, 2020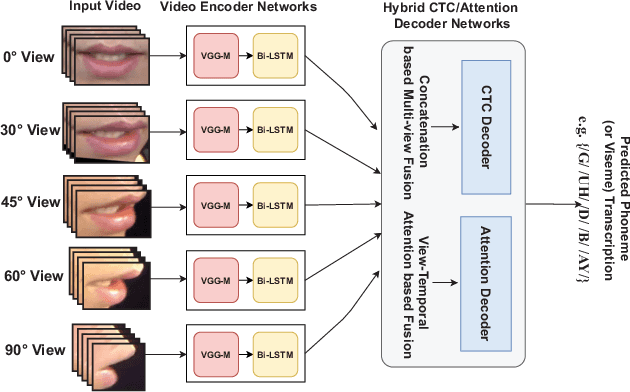
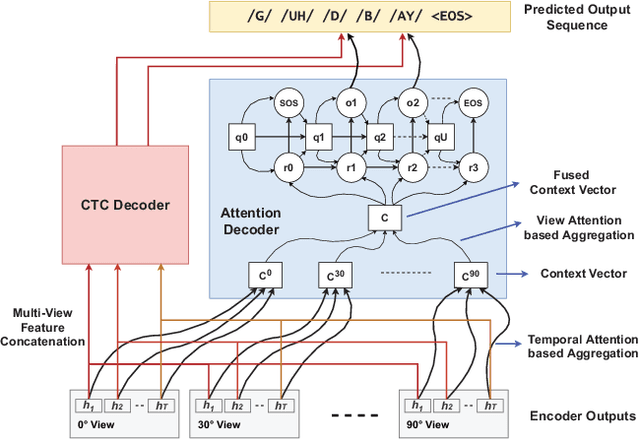
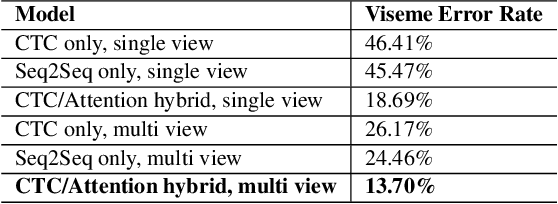
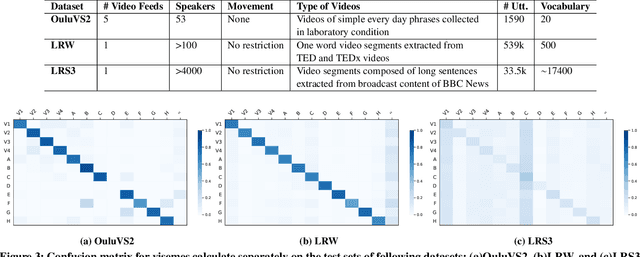
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.