 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Exploration and Knowledge Discovery from Biomedical Dark Data
Sep 28, 2020
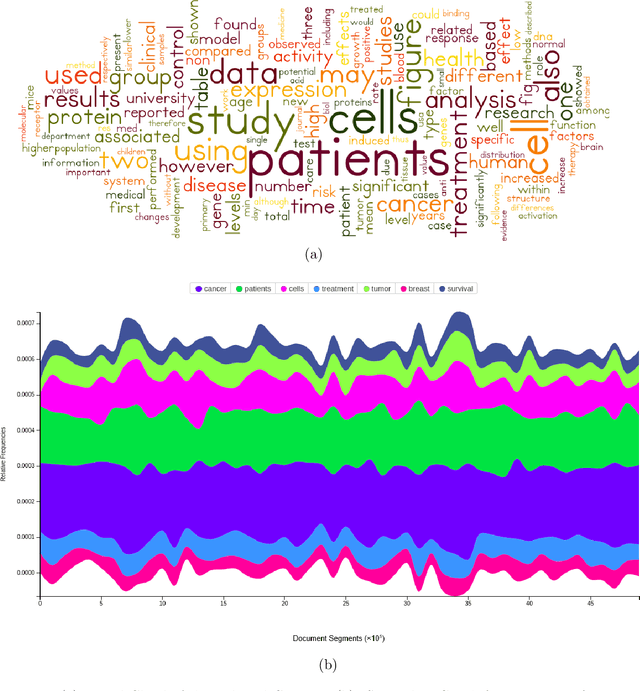
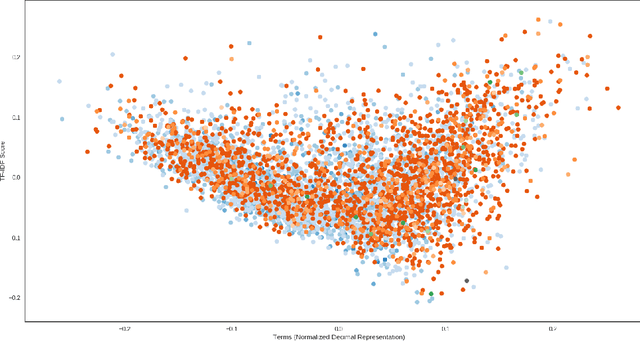
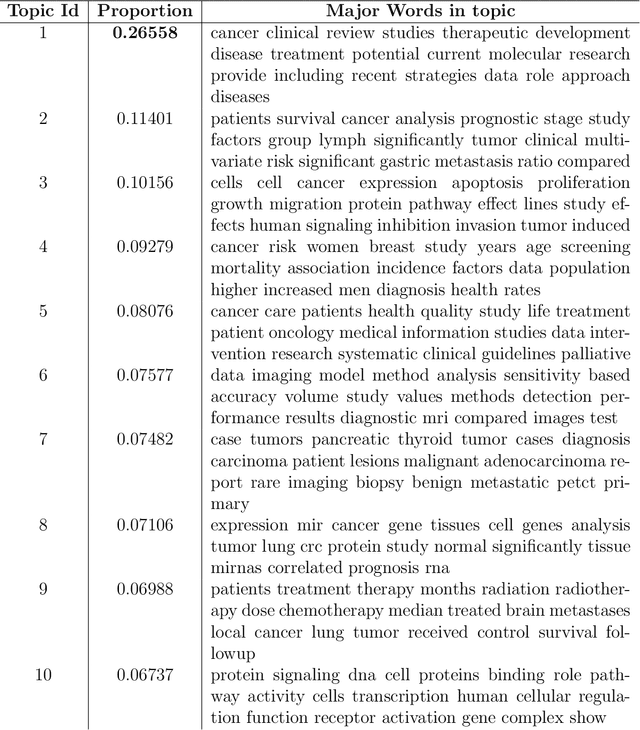
Data visualization techniques proffer efficient means to organize and present data in graphically appealing formats, which not only speeds up the process of decision making and pattern recognition but also enables decision-makers to fully understand data insights and make informed decisions. Over time, with the rise in technological and computational resources, there has been an exponential increase in the world's scientific knowledge. However, most of it lacks structure and cannot be easily categorized and imported into regular databases. This type of data is often termed as Dark Data. Data visualization techniques provide a promising solution to explore such data by allowing quick comprehension of information, the discovery of emerging trends, identification of relationships and patterns, etc. In this empirical research study, we use the rich corpus of PubMed comprising of more than 30 million citations from biomedical literature to visually explore and understand the underlying key-insights using various information visualization techniques. We employ a natural language processing based pipeline to discover knowledge out of the biomedical dark data. The pipeline comprises of different lexical analysis techniques like Topic Modeling to extract inherent topics and major focus areas, Network Graphs to study the relationships between various entities like scientific documents and journals, researchers, and, keywords and terms, etc. With this analytical research, we aim to proffer a potential solution to overcome the problem of analyzing overwhelming amounts of information and diminish the limitation of human cognition and perception in handling and examining such large volumes of data.
Metaphor Detection using Deep Contextualized Word Embeddings
Sep 26, 2020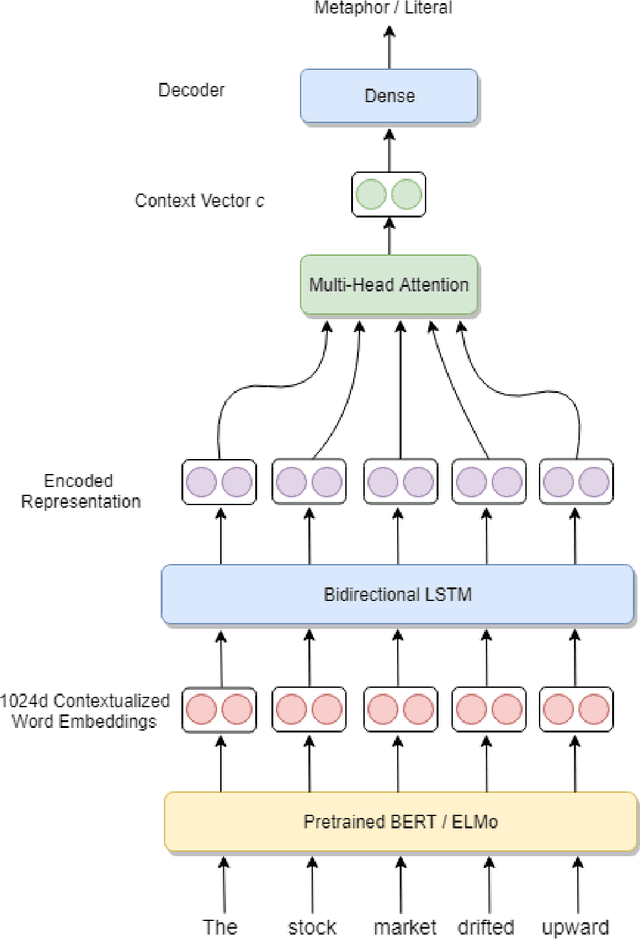


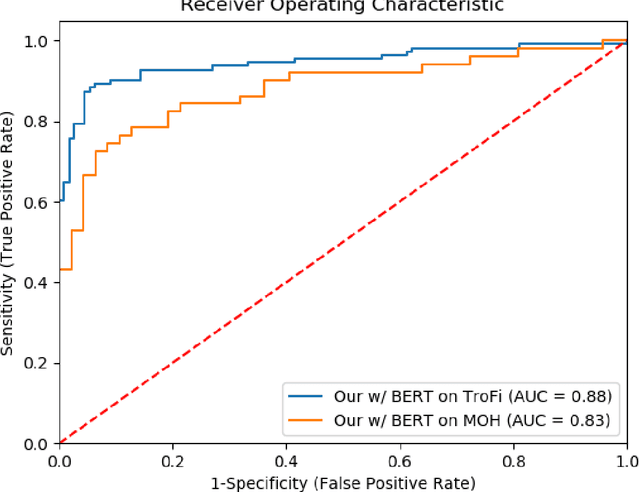
Metaphors are ubiquitous in natural language, and their detection plays an essential role in many natural language processing tasks, such as language understanding, sentiment analysis, etc. Most existing approaches for metaphor detection rely on complex, hand-crafted and fine-tuned feature pipelines, which greatly limit their applicability. In this work, we present an end-to-end method composed of deep contextualized word embeddings, bidirectional LSTMs and multi-head attention mechanism to address the task of automatic metaphor detection. Our method, unlike many other existing approaches, requires only the raw text sequences as input features to detect the metaphoricity of a phrase. We compare the performance of our method against the existing baselines on two benchmark datasets, TroFi, and MOH-X respectively. Experimental evaluations confirm the effectiveness of our approach.
"Notic My Speech" -- Blending Speech Patterns With Multimedia
Jun 12, 2020
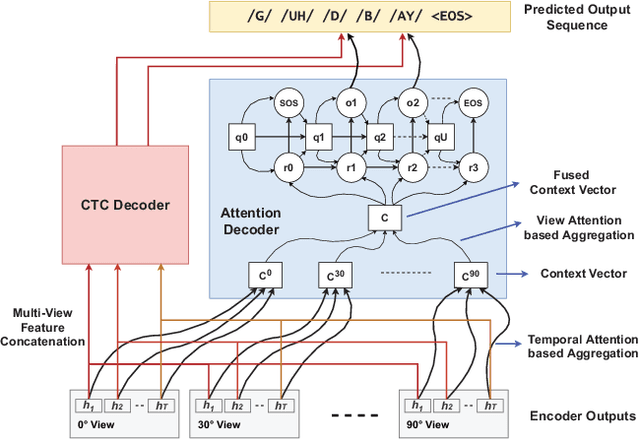
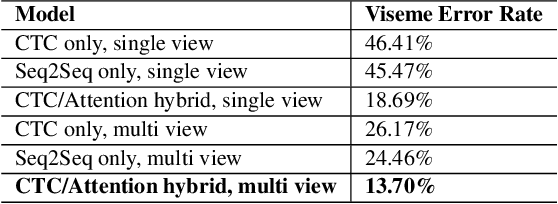
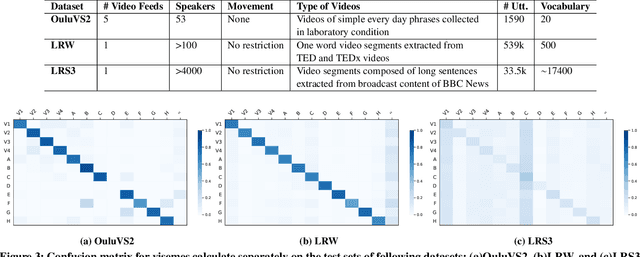
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.