 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn by Selling: Equipping Large Language Models with Product Knowledge for Context-Driven Recommendations
Jul 30, 2024
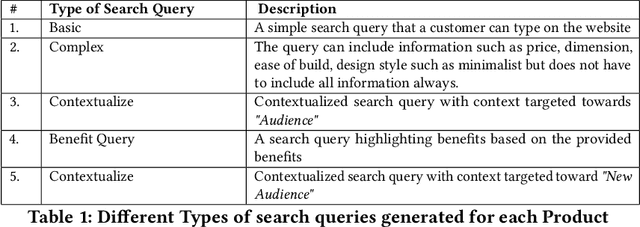


The rapid evolution of large language models (LLMs) has opened up new possibilities for applications such as context-driven product recommendations. However, the effectiveness of these models in this context is heavily reliant on their comprehensive understanding of the product inventory. This paper presents a novel approach to equipping LLMs with product knowledge by training them to respond contextually to synthetic search queries that include product IDs. We delve into an extensive analysis of this method, evaluating its effectiveness, outlining its benefits, and highlighting its constraints. The paper also discusses the potential improvements and future directions for this approach, providing a comprehensive understanding of the role of LLMs in product recommendations.
Studying the impacts of pre-training using ChatGPT-generated text on downstream tasks
Sep 02, 2023In recent times, significant advancements have been witnessed in the field of language models, particularly with the emergence of Large Language Models (LLMs) that are trained on vast amounts of data extracted from internet archives. These LLMs, such as ChatGPT, have become widely accessible, allowing users to generate text for various purposes including articles, essays, jokes, and poetry. Given that LLMs are trained on a diverse range of text sources, encompassing platforms like Reddit and Twitter, it is foreseeable that future training datasets will also incorporate text generated by previous iterations of the models themselves. In light of this development, our research aims to investigate the influence of artificial text in the pre-training phase of language models. Specifically, we conducted a comparative analysis between a language model, RoBERTa, pre-trained using CNN/DailyMail news articles, and ChatGPT, which employed the same articles for its training and evaluated their performance on three downstream tasks as well as their potential gender bias, using sentiment analysis as a metric. Through a series of experiments, we demonstrate that the utilization of artificial text during pre-training does not have a significant impact on either the performance of the models in downstream tasks or their gender bias. In conclusion, our findings suggest that the inclusion of text generated by LLMs in their own pre-training process does not yield substantial effects on the subsequent performance of the models in downstream tasks or their potential gender bias.
Is it Required? Ranking the Skills Required for a Job-Title
Nov 28, 2022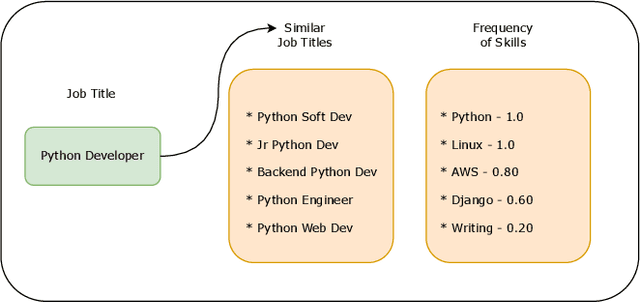
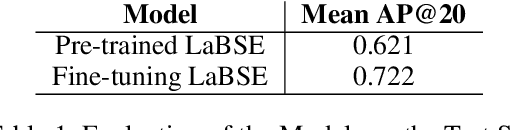
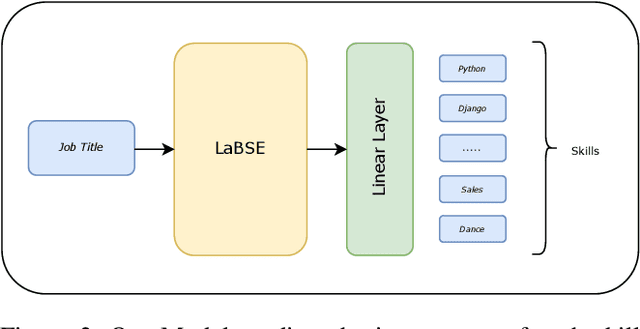
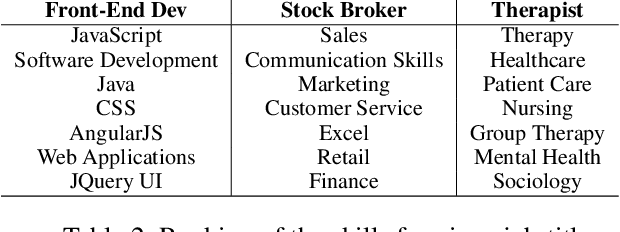
In this paper, we describe our method for ranking the skills required for a given job title. Our analysis shows that important/relevant skills appear more frequently in similar job titles. We train a Language-agnostic BERT Sentence Encoder (LaBSE) model to predict the importance of the skills using weak supervision. We show the model can learn the importance of skills and perform well in other languages. Furthermore, we show how the Inverse Document Frequency factor of skill boosts the specialised skills.
MIDAS at SemEval-2020 Task 10: Emphasis Selection using Label Distribution Learning and Contextual Embeddings
Sep 06, 2020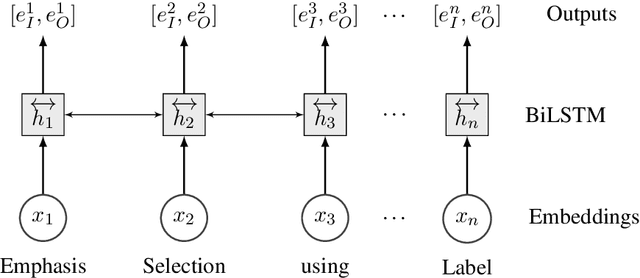
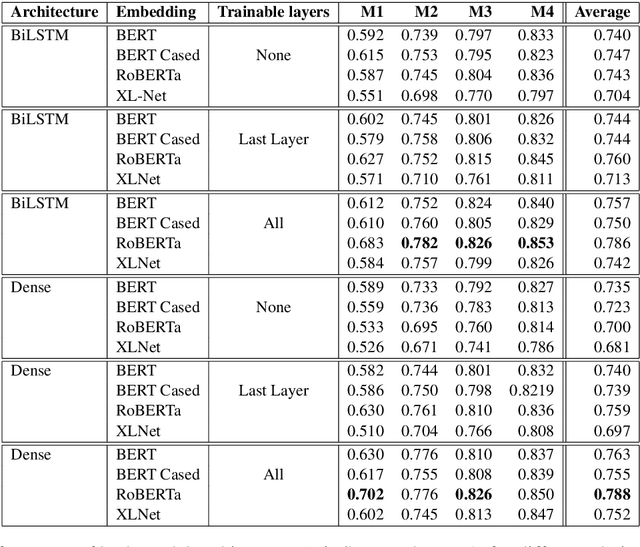


This paper presents our submission to the SemEval 2020 - Task 10 on emphasis selection in written text. We approach this emphasis selection problem as a sequence labeling task where we represent the underlying text with various contextual embedding models. We also employ label distribution learning to account for annotator disagreements. We experiment with the choice of model architectures, trainability of layers, and different contextual embeddings. Our best performing architecture is an ensemble of different models, which achieved an overall matching score of 0.783, placing us 15th out of 31 participating teams. Lastly, we analyze the results in terms of parts of speech tags, sentence lengths, and word ordering.
Suggestion Mining from Online Reviews using ULMFiT
Apr 19, 2019
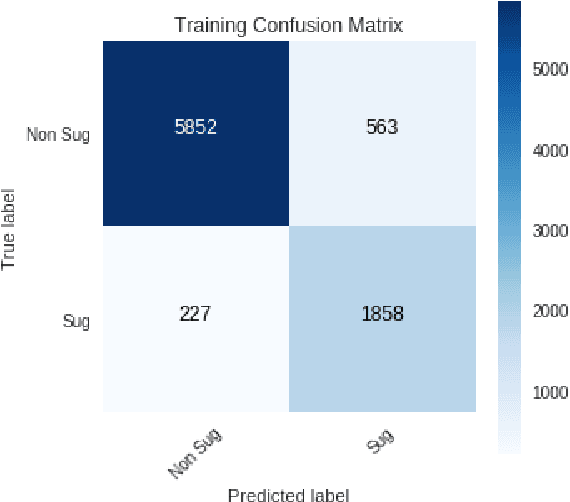

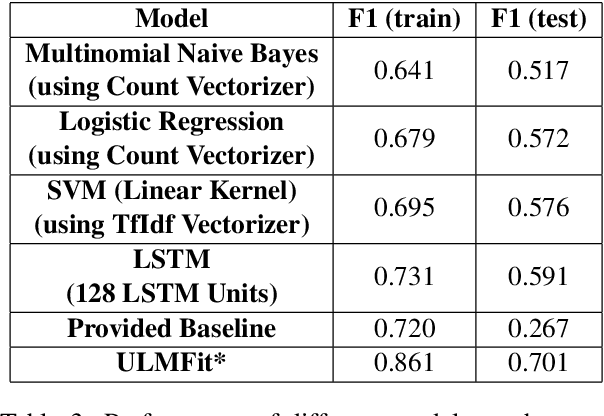
In this paper we present our approach and the system description for Sub Task A of SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. Given a sentence, the task asks to predict whether the sentence consists of a suggestion or not. Our model is based on Universal Language Model Fine-tuning for Text Classification. We apply various pre-processing techniques before training the language and the classification model. We further provide detailed analysis of the results obtained using the trained model. Our team ranked 10th out of 34 participants, achieving an F1 score of 0.7011. We publicly share our implementation at https://github.com/isarth/SemEval9_MIDAS
Identifying Offensive Posts and Targeted Offense from Twitter
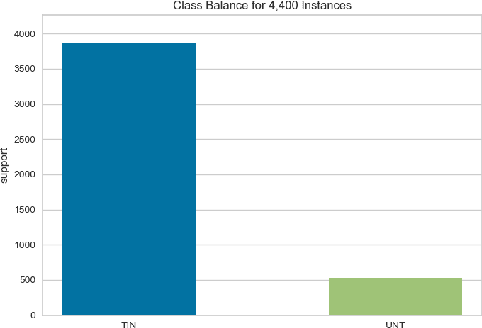
Apr 19, 2019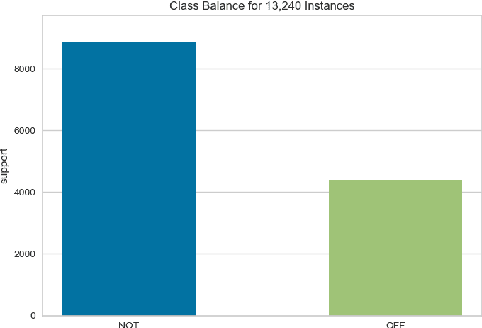

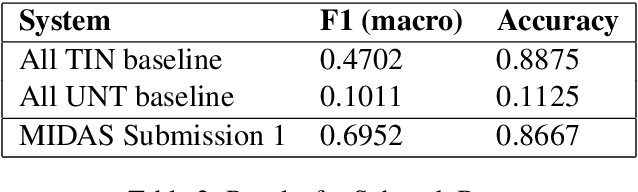
In this paper we present our approach and the system description for Sub-task A and Sub Task B of SemEval 2019 Task 6: Identifying and Categorizing Offensive Language in Social Media. Sub-task A involves identifying if a given tweet is offensive or not, and Sub Task B involves detecting if an offensive tweet is targeted towards someone (group or an individual). Our models for Sub-task A is based on an ensemble of Convolutional Neural Network, Bidirectional LSTM with attention, and Bidirectional LSTM + Bidirectional GRU, whereas for Sub-task B, we rely on a set of heuristics derived from the training data and manual observation. We provide detailed analysis of the results obtained using the trained models. Our team ranked 5th out of 103 participants in Sub-task A, achieving a macro F1 score of 0.807, and ranked 8th out of 75 participants in Sub Task B achieving a macro F1 of 0.695.