 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-GLUE: A Suite of Fundamental yet Challenging Visuo-Linguistic Reasoning Tasks
Oct 17, 2024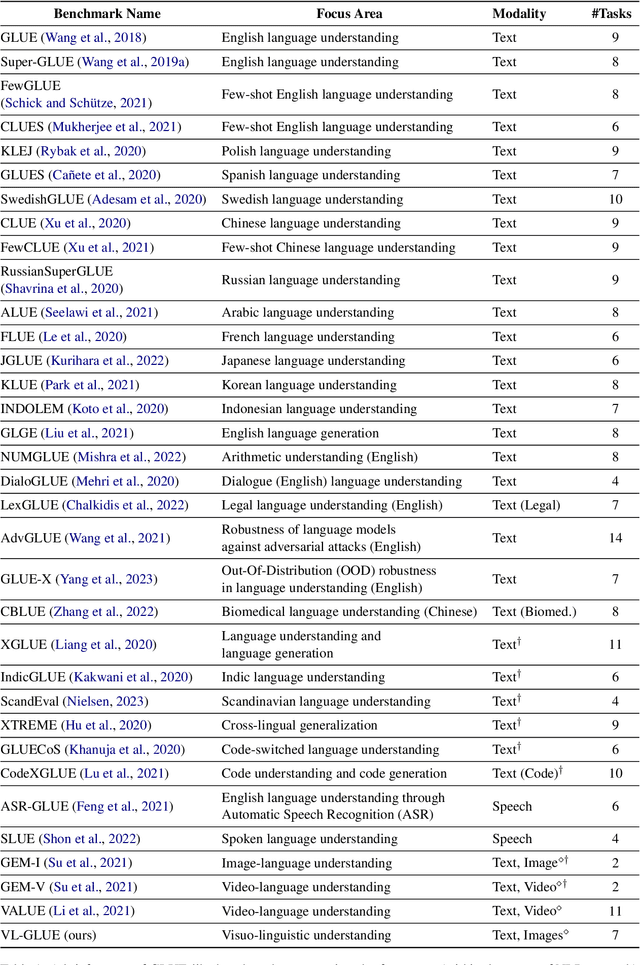

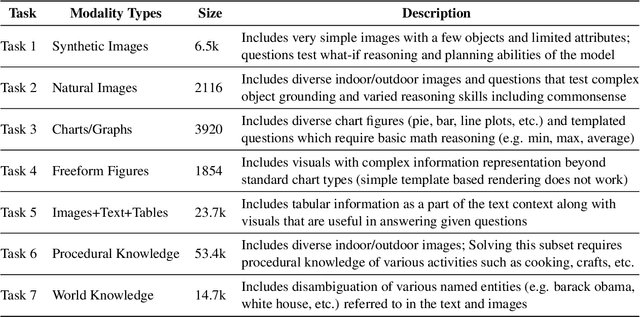

Deriving inference from heterogeneous inputs (such as images, text, and audio) is an important skill for humans to perform day-to-day tasks. A similar ability is desirable for the development of advanced Artificial Intelligence (AI) systems. While state-of-the-art models are rapidly closing the gap with human-level performance on diverse computer vision and NLP tasks separately, they struggle to solve tasks that require joint reasoning over visual and textual modalities. Inspired by GLUE (Wang et. al., 2018)- a multitask benchmark for natural language understanding, we propose VL-GLUE in this paper. VL-GLUE consists of over 100k samples spanned across seven different tasks, which at their core require visuo-linguistic reasoning. Moreover, our benchmark comprises of diverse image types (from synthetically rendered figures, and day-to-day scenes to charts and complex diagrams) and includes a broad variety of domain-specific text (from cooking, politics, and sports to high-school curricula), demonstrating the need for multi-modal understanding in the real-world. We show that this benchmark is quite challenging for existing large-scale vision-language models and encourage development of systems that possess robust visuo-linguistic reasoning capabilities.
Controlling Personality Style in Dialogue with Zero-Shot Prompt-Based Learning
Feb 08, 2023



Prompt-based or in-context learning has achieved high zero-shot performance on many natural language generation (NLG) tasks. Here we explore the performance of prompt-based learning for simultaneously controlling the personality and the semantic accuracy of an NLG for task-oriented dialogue. We experiment with prompt-based learning on the PERSONAGE restaurant recommendation corpus to generate semantically and stylistically-controlled text for 5 different Big-5 personality types: agreeable, disagreeable, conscientious, unconscientious, and extravert. We test two different classes of discrete prompts to generate utterances for a particular personality style: (1) prompts that demonstrate generating directly from a meaning representation that includes a personality specification; and (2) prompts that rely on first converting the meaning representation to a textual pseudo-reference, and then using the pseudo-reference in a textual style transfer (TST) prompt. In each case, we show that we can vastly improve performance by over-generating outputs and ranking them, testing several ranking functions based on automatic metrics for semantic accuracy, personality-match, and fluency. We also test whether NLG personality demonstrations from the restaurant domain can be used with meaning representations for the video game domain to generate personality stylized utterances about video games. Our findings show that the TST prompts produces the highest semantic accuracy (78.46% for restaurants and 87.6% for video games) and personality accuracy (100% for restaurants and 97% for video games). Our results on transferring personality style to video game utterances are surprisingly good. To our knowledge, there is no previous work testing the application of prompt-based learning to simultaneously controlling both style and semantic accuracy in NLG.
Suggestion Mining from Online Reviews using ULMFiT
Apr 19, 2019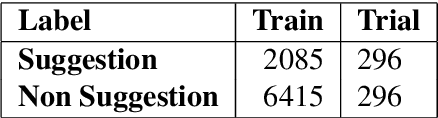
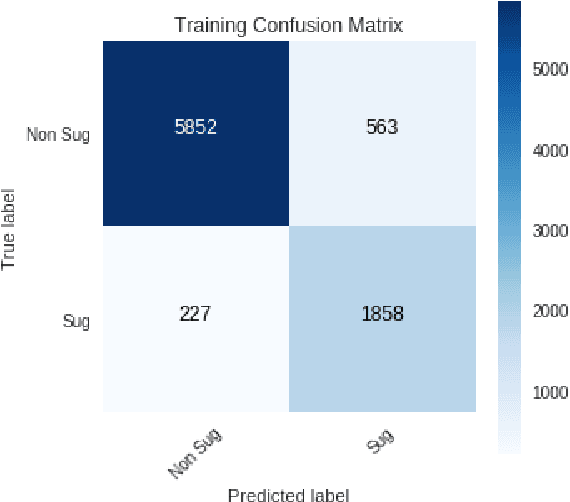

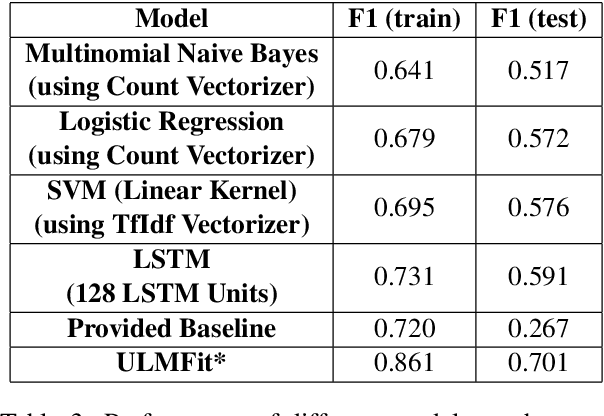
In this paper we present our approach and the system description for Sub Task A of SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. Given a sentence, the task asks to predict whether the sentence consists of a suggestion or not. Our model is based on Universal Language Model Fine-tuning for Text Classification. We apply various pre-processing techniques before training the language and the classification model. We further provide detailed analysis of the results obtained using the trained model. Our team ranked 10th out of 34 participants, achieving an F1 score of 0.7011. We publicly share our implementation at https://github.com/isarth/SemEval9_MIDAS