 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelp Me Identify: Is an LLM+VQA System All We Need to Identify Visual Concepts?
Oct 17, 2024



An ability to learn about new objects from a small amount of visual data and produce convincing linguistic justification about the presence/absence of certain concepts (that collectively compose the object) in novel scenarios is an important characteristic of human cognition. This is possible due to abstraction of attributes/properties that an object is composed of e.g. an object `bird' can be identified by the presence of a beak, feathers, legs, wings, etc. Inspired by this aspect of human reasoning, in this work, we present a zero-shot framework for fine-grained visual concept learning by leveraging large language model and Visual Question Answering (VQA) system. Specifically, we prompt GPT-3 to obtain a rich linguistic description of visual objects in the dataset. We convert the obtained concept descriptions into a set of binary questions. We pose these questions along with the query image to a VQA system and aggregate the answers to determine the presence or absence of an object in the test images. Our experiments demonstrate comparable performance with existing zero-shot visual classification methods and few-shot concept learning approaches, without substantial computational overhead, yet being fully explainable from the reasoning perspective.
ActionCOMET: A Zero-shot Approach to Learn Image-specific Commonsense Concepts about Actions
Oct 17, 2024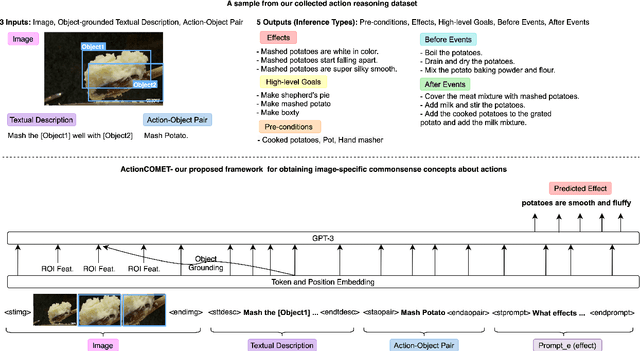
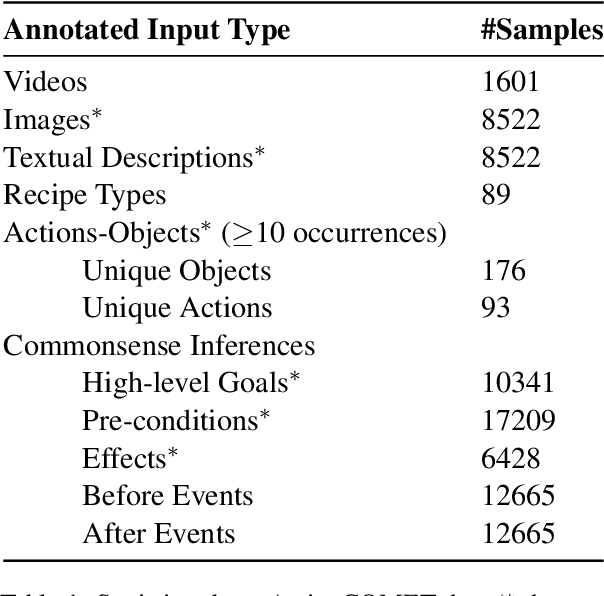
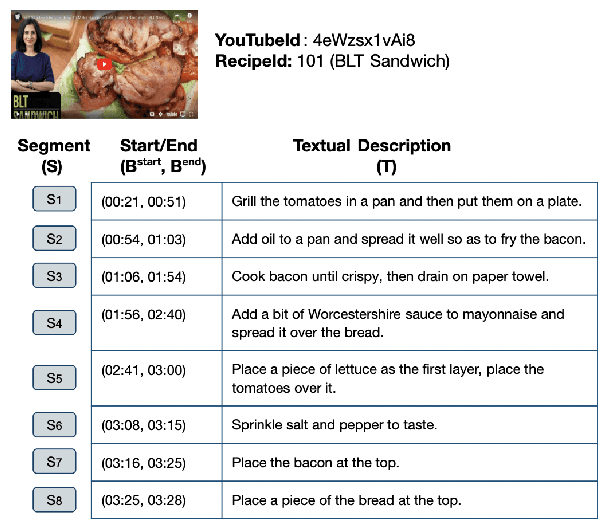
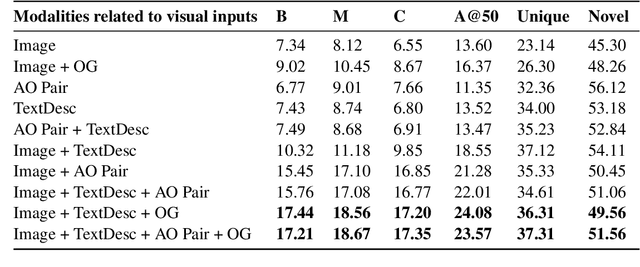
Humans observe various actions being performed by other humans (physically or in videos/images) and can draw a wide range of inferences about it beyond what they can visually perceive. Such inferences include determining the aspects of the world that make action execution possible (e.g. liquid objects can undergo pouring), predicting how the world will change as a result of the action (e.g. potatoes being golden and crispy after frying), high-level goals associated with the action (e.g. beat the eggs to make an omelet) and reasoning about actions that possibly precede or follow the current action (e.g. crack eggs before whisking or draining pasta after boiling). Similar reasoning ability is highly desirable in autonomous systems that would assist us in performing everyday tasks. To that end, we propose a multi-modal task to learn aforementioned concepts about actions being performed in images. We develop a dataset consisting of 8.5k images and 59.3k inferences about actions grounded in those images, collected from an annotated cooking-video dataset. We propose ActionCOMET, a zero-shot framework to discern knowledge present in language models specific to the provided visual input. We present baseline results of ActionCOMET over the collected dataset and compare them with the performance of the best existing VQA approaches.
VL-GLUE: A Suite of Fundamental yet Challenging Visuo-Linguistic Reasoning Tasks
Oct 17, 2024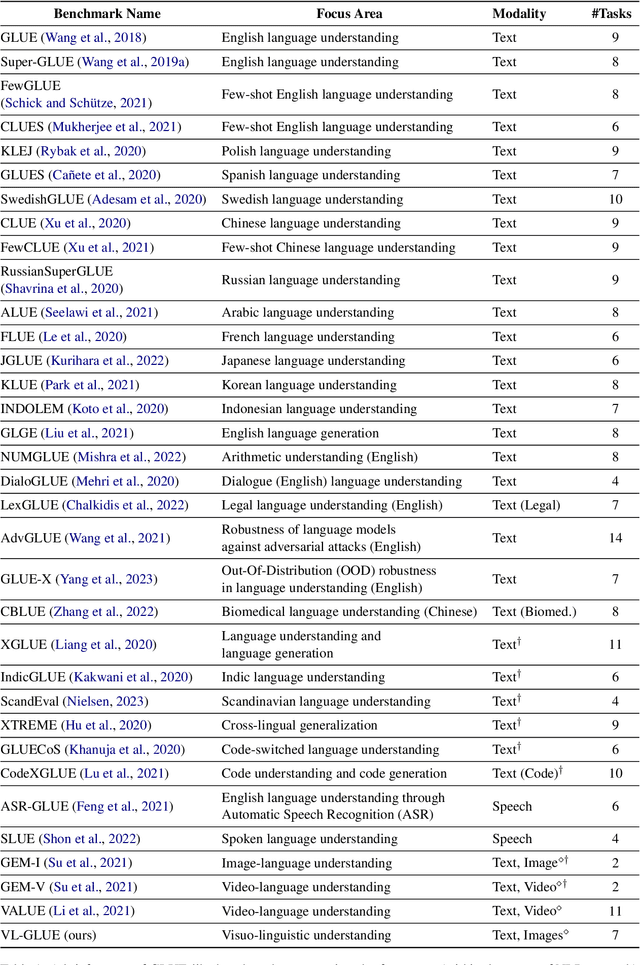

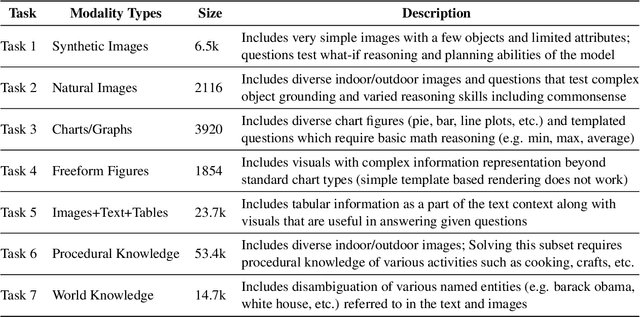

Deriving inference from heterogeneous inputs (such as images, text, and audio) is an important skill for humans to perform day-to-day tasks. A similar ability is desirable for the development of advanced Artificial Intelligence (AI) systems. While state-of-the-art models are rapidly closing the gap with human-level performance on diverse computer vision and NLP tasks separately, they struggle to solve tasks that require joint reasoning over visual and textual modalities. Inspired by GLUE (Wang et. al., 2018)- a multitask benchmark for natural language understanding, we propose VL-GLUE in this paper. VL-GLUE consists of over 100k samples spanned across seven different tasks, which at their core require visuo-linguistic reasoning. Moreover, our benchmark comprises of diverse image types (from synthetically rendered figures, and day-to-day scenes to charts and complex diagrams) and includes a broad variety of domain-specific text (from cooking, politics, and sports to high-school curricula), demonstrating the need for multi-modal understanding in the real-world. We show that this benchmark is quite challenging for existing large-scale vision-language models and encourage development of systems that possess robust visuo-linguistic reasoning capabilities.
Learning Action-Effect Dynamics from Pairs of Scene-graphs
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). Recently, there has been growing interest in the study of RAC with visual and linguistic inputs. Graphs are often used to represent semantic structure of the visual content (i.e. objects, their attributes and relationships among objects), commonly referred to as scene-graphs. In this work, we propose a novel method that leverages scene-graph representation of images to reason about the effects of actions described in natural language. We experiment with existing CLEVR_HYP (Sampat et. al, 2021) dataset and show that our proposed approach is effective in terms of performance, data efficiency, and generalization capability compared to existing models.
Learning Action-Effect Dynamics for Hypothetical Vision-Language Reasoning Task
Dec 07, 2022'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). This has been an important research direction in Artificial Intelligence (AI) in general, but the study of RAC with visual and linguistic inputs is relatively recent. The CLEVR_HYP (Sampat et. al., 2021) is one such testbed for hypothetical vision-language reasoning with actions as the key focus. In this work, we propose a novel learning strategy that can improve reasoning about the effects of actions. We implement an encoder-decoder architecture to learn the representation of actions as vectors. We combine the aforementioned encoder-decoder architecture with existing modality parsers and a scene graph question answering model to evaluate our proposed system on the CLEVR_HYP dataset. We conduct thorough experiments to demonstrate the effectiveness of our proposed approach and discuss its advantages over previous baselines in terms of performance, data efficiency, and generalization capability.
Reasoning about Actions over Visual and Linguistic Modalities: A Survey
Jul 15, 2022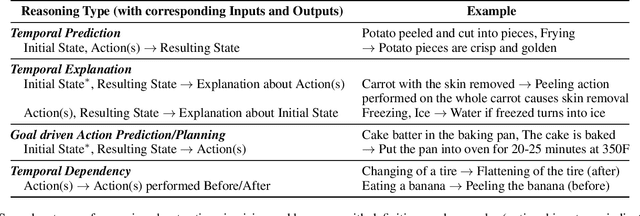


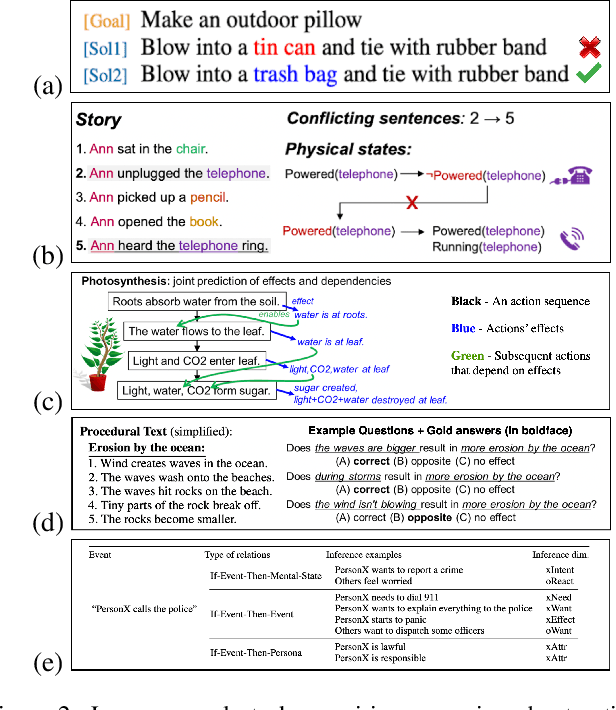
'Actions' play a vital role in how humans interact with the world and enable them to achieve desired goals. As a result, most common sense (CS) knowledge for humans revolves around actions. While 'Reasoning about Actions & Change' (RAC) has been widely studied in the Knowledge Representation community, it has recently piqued the interest of NLP and computer vision researchers. This paper surveys existing tasks, benchmark datasets, various techniques and models, and their respective performance concerning advancements in RAC in the vision and language domain. Towards the end, we summarize our key takeaways, discuss the present challenges facing this research area, and outline potential directions for future research.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

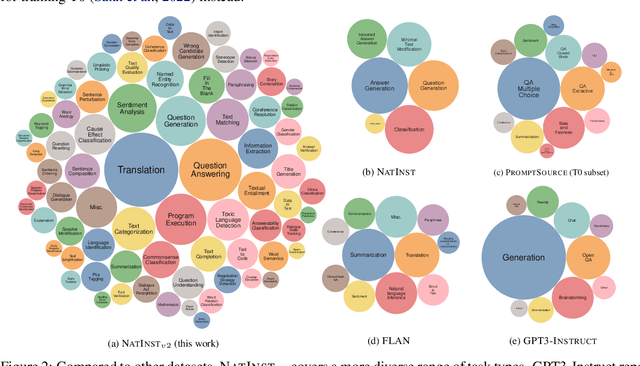
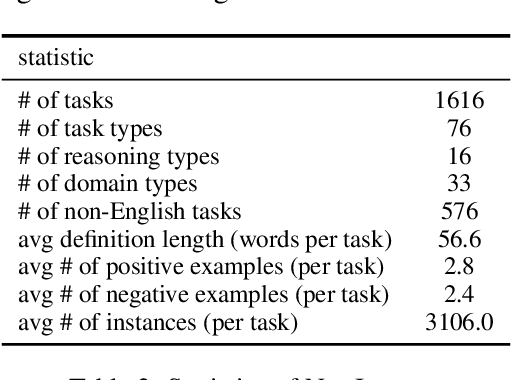
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
CLEVR_HYP: A Challenge Dataset and Baselines for Visual Question Answering with Hypothetical Actions over Images
Apr 13, 2021



Most existing research on visual question answering (VQA) is limited to information explicitly present in an image or a video. In this paper, we take visual understanding to a higher level where systems are challenged to answer questions that involve mentally simulating the hypothetical consequences of performing specific actions in a given scenario. Towards that end, we formulate a vision-language question answering task based on the CLEVR (Johnson et. al., 2017) dataset. We then modify the best existing VQA methods and propose baseline solvers for this task. Finally, we motivate the development of better vision-language models by providing insights about the capability of diverse architectures to perform joint reasoning over image-text modality. Our dataset setup scripts and codes will be made publicly available at https://github.com/shailaja183/clevr_hyp.
'Just because you are right, doesn't mean I am wrong': Overcoming a Bottleneck in the Development and Evaluation of Open-Ended Visual Question Answering Tasks
Mar 28, 2021

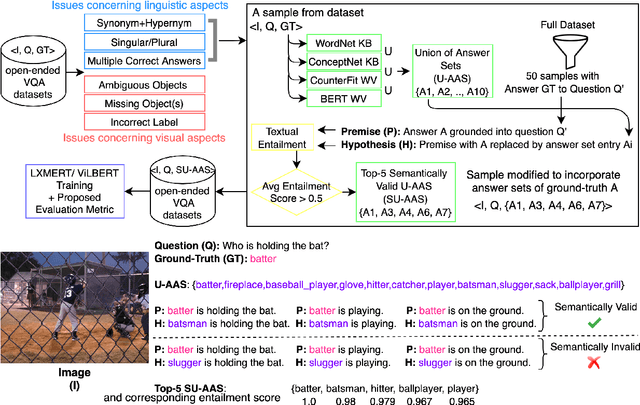

GQA (Hudson and Manning, 2019) is a dataset for real-world visual reasoning and compositional question answering. We found that many answers predicted by the best visionlanguage models on the GQA dataset do not match the ground-truth answer but still are semantically meaningful and correct in the given context. In fact, this is the case with most existing visual question answering (VQA) datasets where they assume only one ground-truth answer for each question. We propose Alternative Answer Sets (AAS) of ground-truth answers to address this limitation, which is created automatically using off-the-shelf NLP tools. We introduce a semantic metric based on AAS and modify top VQA solvers to support multiple plausible answers for a question. We implement this approach on the GQA dataset and show the performance improvements.