 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025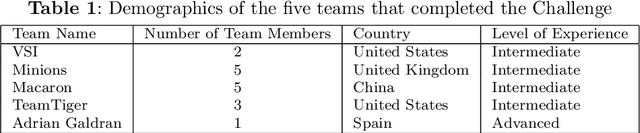
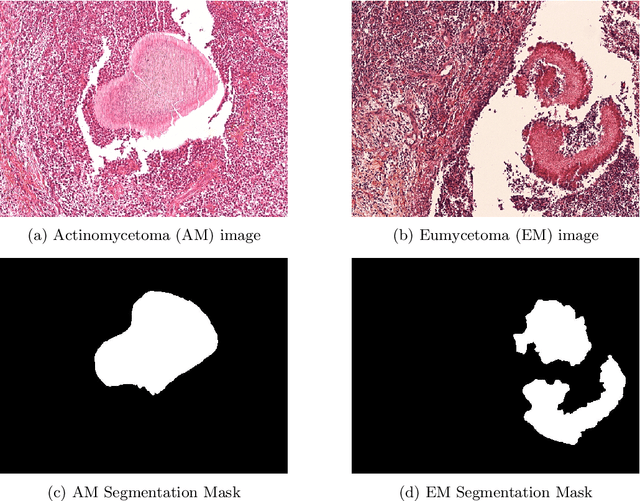
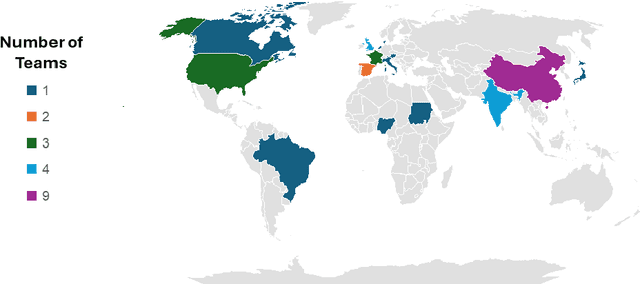

Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
Towards Understanding Gradient Flow Dynamics of Homogeneous Neural Networks Beyond the Origin
Feb 21, 2025
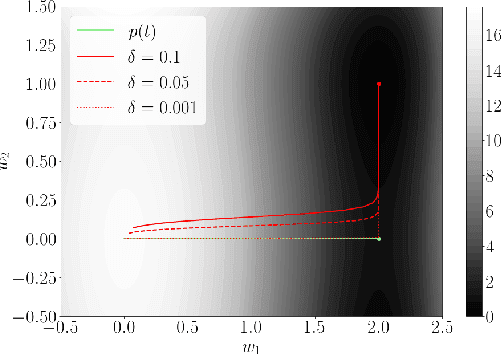


Recent works exploring the training dynamics of homogeneous neural network weights under gradient flow with small initialization have established that in the early stages of training, the weights remain small and near the origin, but converge in direction. Building on this, the current paper studies the gradient flow dynamics of homogeneous neural networks with locally Lipschitz gradients, after they escape the origin. Insights gained from this analysis are used to characterize the first saddle point encountered by gradient flow after escaping the origin. Also, it is shown that for homogeneous feed-forward neural networks, under certain conditions, the sparsity structure emerging among the weights before the escape is preserved after escaping the origin and until reaching the next saddle point.
Fuzzy Logic Control for Indoor Navigation of Mobile Robots
Sep 04, 2024



Autonomous mobile robots have many applications in indoor unstructured environment, wherein optimal movement of the robot is needed. The robot therefore needs to navigate in unknown and dynamic environments. This paper presents an implementation of fuzzy logic controller for navigation of mobile robot in an unknown dynamically cluttered environment. Fuzzy logic controller is used here as it is capable of making inferences even under uncertainties. It helps in rule generation and decision making process in order to reach the goal position under various situations. Sensor readings from the robot and the desired direction of motion are inputs to the fuzz logic controllers and the acceleration of the respective wheels are the output of the controller. Hence, the mobile robot avoids obstacles and reaches the goal position. Keywords: Fuzzy Logic Controller, Membership Functions, Takagi-Sugeno-Kang FIS, Centroid Defuzzification
Kinematics & Dynamics Library for Baxter Arm
Sep 01, 2024



The Baxter robot is a standard research platform used widely in research tasks, supported with an SDK provided by the developers, Rethink Robotics. Despite the ubiquitous use of the robot, the official software support is sub-standard. Especially, the native IK service has a low success rate and is often inconsistent. This unreliable behavior makes Baxter difficult to use for experiments and the research community is in need of a more reliable software support to control the robot. We present our work towards creating a Python based software library supporting the kinematics and dynamics of the Baxter robot. Our toolbox contains implementation of pose and velocity kinematics with support for Jacobian operations for redundancy resolution. We present the implementation and performance of our library, along with a comparison with PyKDL. Keywords- Baxter Research Robot, Manipulator Kinematics, Iterative IK, Dynamical Model, Redundant Manipulator
Early Directional Convergence in Deep Homogeneous Neural Networks for Small Initializations
Mar 12, 2024This paper studies the gradient flow dynamics that arise when training deep homogeneous neural networks, starting with small initializations. The present work considers neural networks that are assumed to have locally Lipschitz gradients and an order of homogeneity strictly greater than two. This paper demonstrates that for sufficiently small initializations, during the early stages of training, the weights of the neural network remain small in norm and approximately converge in direction along the Karush-Kuhn-Tucker (KKT) points of the neural correlation function introduced in [1]. Additionally, for square loss and under a separability assumption on the weights of neural networks, a similar directional convergence of gradient flow dynamics is shown near certain saddle points of the loss function.
Directional Convergence Near Small Initializations and Saddles in Two-Homogeneous Neural Networks
Feb 14, 2024
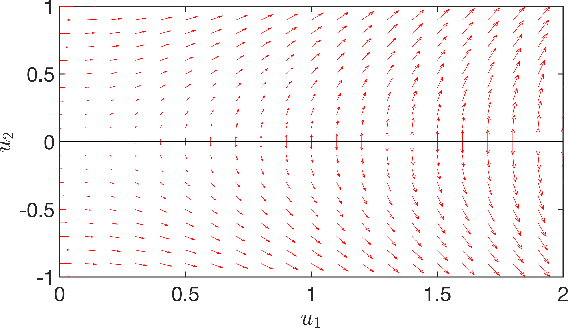

This paper examines gradient flow dynamics of two-homogeneous neural networks for small initializations, where all weights are initialized near the origin. For both square and logistic losses, it is shown that for sufficiently small initializations, the gradient flow dynamics spend sufficient time in the neighborhood of the origin to allow the weights of the neural network to approximately converge in direction to the Karush-Kuhn-Tucker (KKT) points of a neural correlation function that quantifies the correlation between the output of the neural network and corresponding labels in the training data set. For square loss, it has been observed that neural networks undergo saddle-to-saddle dynamics when initialized close to the origin. Motivated by this, this paper also shows a similar directional convergence among weights of small magnitude in the neighborhood of certain saddle points.
CLEVR_HYP: A Challenge Dataset and Baselines for Visual Question Answering with Hypothetical Actions over Images
Apr 13, 2021



Most existing research on visual question answering (VQA) is limited to information explicitly present in an image or a video. In this paper, we take visual understanding to a higher level where systems are challenged to answer questions that involve mentally simulating the hypothetical consequences of performing specific actions in a given scenario. Towards that end, we formulate a vision-language question answering task based on the CLEVR (Johnson et. al., 2017) dataset. We then modify the best existing VQA methods and propose baseline solvers for this task. Finally, we motivate the development of better vision-language models by providing insights about the capability of diverse architectures to perform joint reasoning over image-text modality. Our dataset setup scripts and codes will be made publicly available at https://github.com/shailaja183/clevr_hyp.
Understanding the Role of Scene Graphs in Visual Question Answering
Jan 17, 2021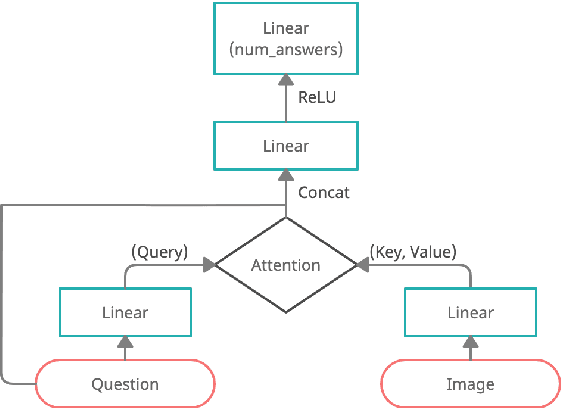
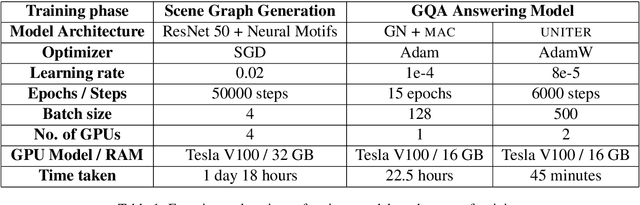
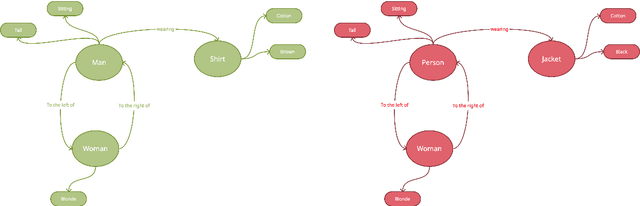
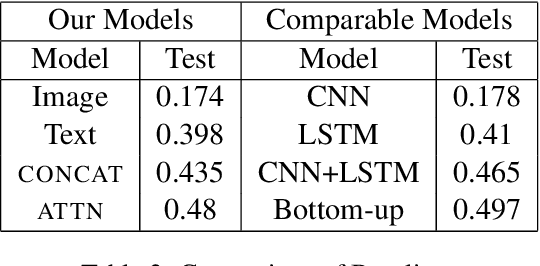
Visual Question Answering (VQA) is of tremendous interest to the research community with important applications such as aiding visually impaired users and image-based search. In this work, we explore the use of scene graphs for solving the VQA task. We conduct experiments on the GQA dataset which presents a challenging set of questions requiring counting, compositionality and advanced reasoning capability, and provides scene graphs for a large number of images. We adopt image + question architectures for use with scene graphs, evaluate various scene graph generation techniques for unseen images, propose a training curriculum to leverage human-annotated and auto-generated scene graphs, and build late fusion architectures to learn from multiple image representations. We present a multi-faceted study into the use of scene graphs for VQA, making this work the first of its kind.
Convexifying Sparse Interpolation with Infinitely Wide Neural Networks: An Atomic Norm Approach
Jul 15, 2020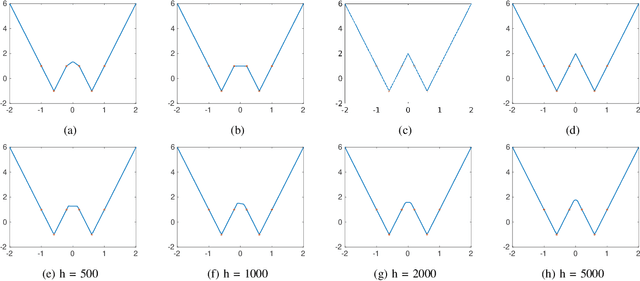
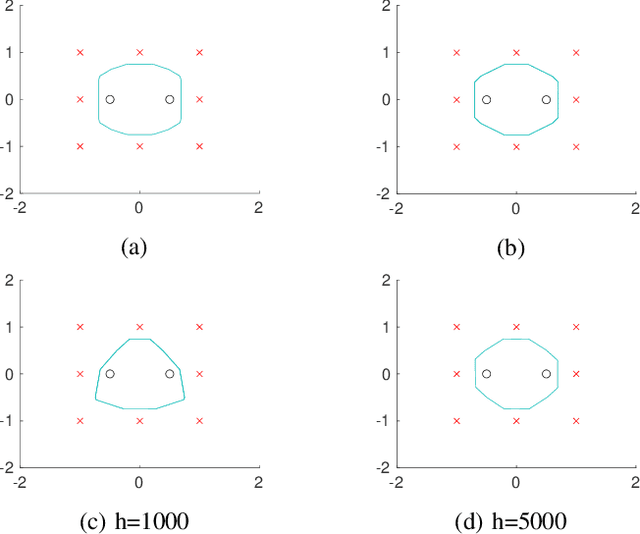
This work examines the problem of exact data interpolation via sparse (neuron count), infinitely wide, single hidden layer neural networks with leaky rectified linear unit activations. Using the atomic norm framework of [Chandrasekaran et al., 2012], we derive simple characterizations of the convex hulls of the corresponding atomic sets for this problem under several different constraints on the weights and biases of the network, thus obtaining equivalent convex formulations for these problems. A modest extension of our proposed framework to a binary classification problem is also presented. We explore the efficacy of the resulting formulations experimentally, and compare with networks trained via gradient descent.