 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying AI for Signal Processing education: Selected challenges and intriguing opportunities
Sep 10, 2025Powerful artificial intelligence (AI) tools that have emerged in recent years -- including large language models, automated coding assistants, and advanced image and speech generation technologies -- are the result of monumental human achievements. These breakthroughs reflect mastery across multiple technical disciplines and the resolution of significant technological challenges. However, some of the most profound challenges may still lie ahead. These challenges are not purely technical but pertain to the fair and responsible use of AI in ways that genuinely improve the global human condition. This article explores one promising application aligned with that vision: the use of AI tools to facilitate and enhance education, with a specific focus on signal processing (SP). It presents two interrelated perspectives: identifying and addressing technical limitations, and applying AI tools in practice to improve educational experiences. Primers are provided on several core technical issues that arise when using AI in educational settings, including how to ensure fairness and inclusivity, handle hallucinated outputs, and achieve efficient use of resources. These and other considerations -- such as transparency, explainability, and trustworthiness -- are illustrated through the development of an immersive, structured, and reliable "smart textbook." The article serves as a resource for researchers and educators seeking to advance AI's role in engineering education.
Towards Understanding Gradient Flow Dynamics of Homogeneous Neural Networks Beyond the Origin
Feb 21, 2025


Recent works exploring the training dynamics of homogeneous neural network weights under gradient flow with small initialization have established that in the early stages of training, the weights remain small and near the origin, but converge in direction. Building on this, the current paper studies the gradient flow dynamics of homogeneous neural networks with locally Lipschitz gradients, after they escape the origin. Insights gained from this analysis are used to characterize the first saddle point encountered by gradient flow after escaping the origin. Also, it is shown that for homogeneous feed-forward neural networks, under certain conditions, the sparsity structure emerging among the weights before the escape is preserved after escaping the origin and until reaching the next saddle point.
Early Directional Convergence in Deep Homogeneous Neural Networks for Small Initializations
Mar 12, 2024This paper studies the gradient flow dynamics that arise when training deep homogeneous neural networks, starting with small initializations. The present work considers neural networks that are assumed to have locally Lipschitz gradients and an order of homogeneity strictly greater than two. This paper demonstrates that for sufficiently small initializations, during the early stages of training, the weights of the neural network remain small in norm and approximately converge in direction along the Karush-Kuhn-Tucker (KKT) points of the neural correlation function introduced in [1]. Additionally, for square loss and under a separability assumption on the weights of neural networks, a similar directional convergence of gradient flow dynamics is shown near certain saddle points of the loss function.
Directional Convergence Near Small Initializations and Saddles in Two-Homogeneous Neural Networks
Feb 14, 2024

This paper examines gradient flow dynamics of two-homogeneous neural networks for small initializations, where all weights are initialized near the origin. For both square and logistic losses, it is shown that for sufficiently small initializations, the gradient flow dynamics spend sufficient time in the neighborhood of the origin to allow the weights of the neural network to approximately converge in direction to the Karush-Kuhn-Tucker (KKT) points of a neural correlation function that quantifies the correlation between the output of the neural network and corresponding labels in the training data set. For square loss, it has been observed that neural networks undergo saddle-to-saddle dynamics when initialized close to the origin. Motivated by this, this paper also shows a similar directional convergence among weights of small magnitude in the neighborhood of certain saddle points.
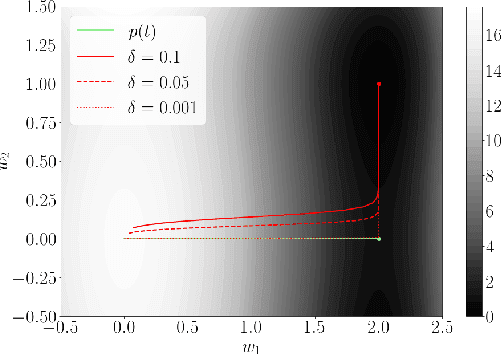
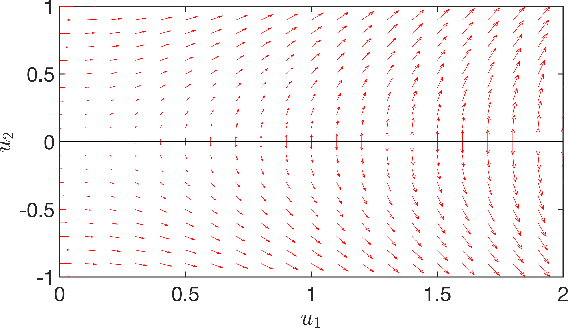
Online Stochastic Gradient Descent Learns Linear Dynamical Systems from A Single Trajectory
Feb 23, 2021
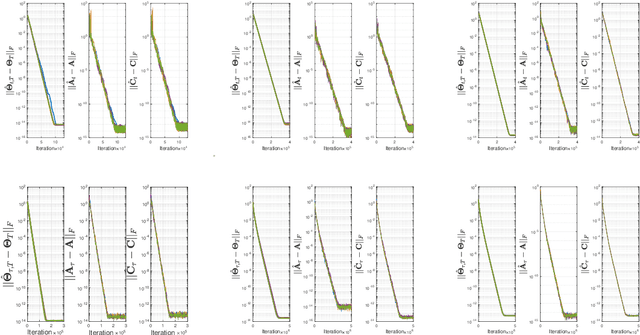
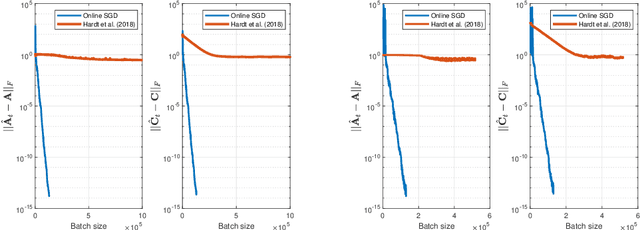
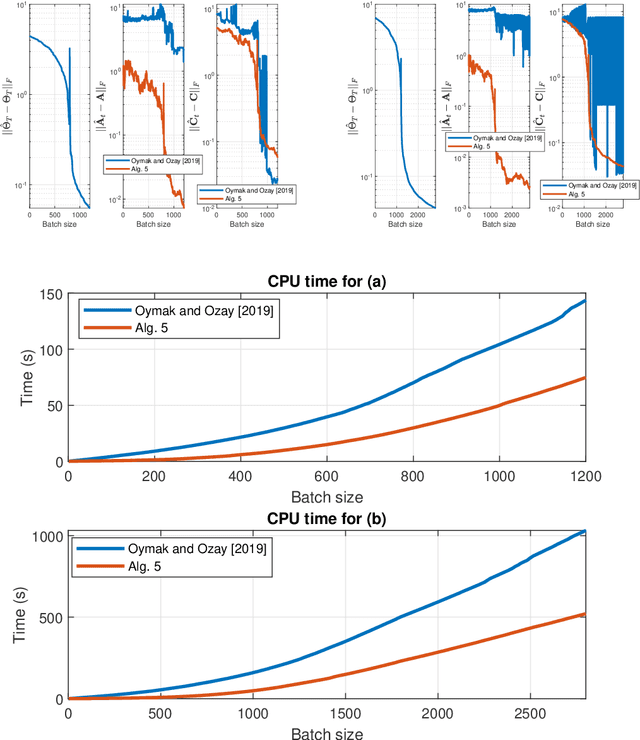
This work investigates the problem of estimating the weight matrices of a stable time-invariant linear dynamical system from a single sequence of noisy measurements. We show that if the unknown weight matrices describing the system are in Brunovsky canonical form, we can efficiently estimate the ground truth unknown matrices of the system from a linear system of equations formulated based on the transfer function of the system, using both online and offline stochastic gradient descent (SGD) methods. Specifically, by deriving concrete complexity bounds, we show that SGD converges linearly in expectation to any arbitrary small Frobenius norm distance from the ground truth weights. To the best of our knowledge, ours is the first work to establish linear convergence characteristics for online and offline gradient-based iterative methods for weight matrix estimation in linear dynamical systems from a single trajectory. Extensive numerical tests verify that the performance of the proposed methods is consistent with our theory, and show their superior performance relative to existing state of the art methods.
Convexifying Sparse Interpolation with Infinitely Wide Neural Networks: An Atomic Norm Approach
Jul 15, 2020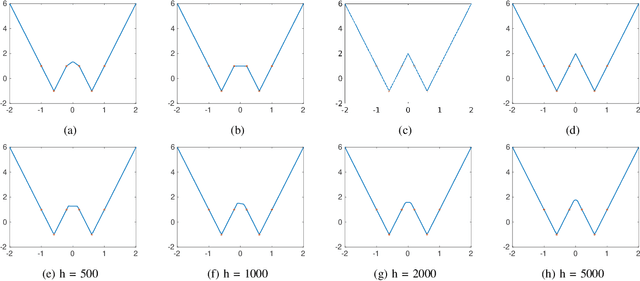
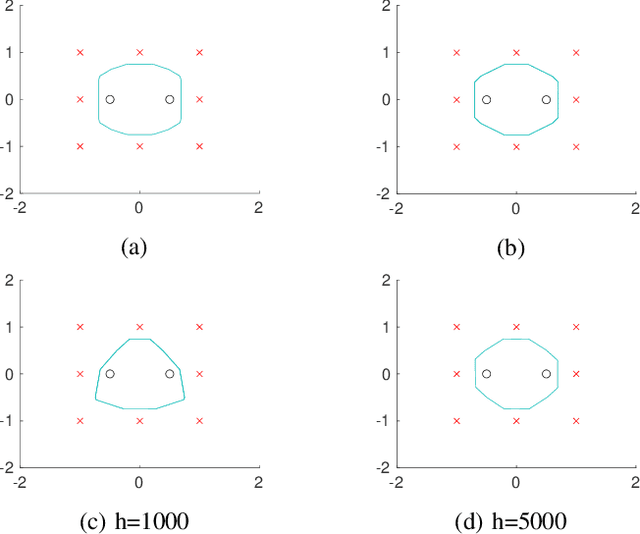
This work examines the problem of exact data interpolation via sparse (neuron count), infinitely wide, single hidden layer neural networks with leaky rectified linear unit activations. Using the atomic norm framework of [Chandrasekaran et al., 2012], we derive simple characterizations of the convex hulls of the corresponding atomic sets for this problem under several different constraints on the weights and biases of the network, thus obtaining equivalent convex formulations for these problems. A modest extension of our proposed framework to a binary classification problem is also presented. We explore the efficacy of the resulting formulations experimentally, and compare with networks trained via gradient descent.
Provable Online CP/PARAFAC Decomposition of a Structured Tensor via Dictionary Learning
Jun 30, 2020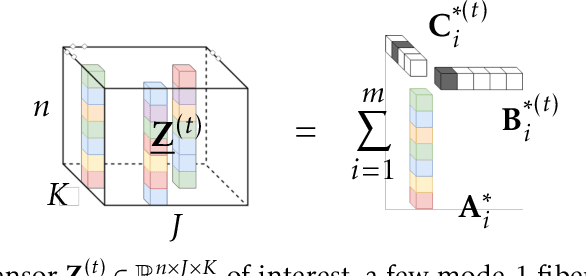

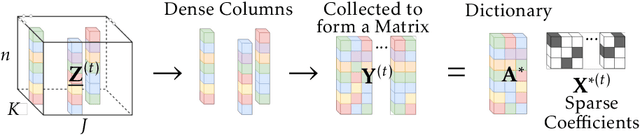
We consider the problem of factorizing a structured 3-way tensor into its constituent Canonical Polyadic (CP) factors. This decomposition, which can be viewed as a generalization of singular value decomposition (SVD) for tensors, reveals how the tensor dimensions (features) interact with each other. However, since the factors are a priori unknown, the corresponding optimization problems are inherently non-convex. The existing guaranteed algorithms which handle this non-convexity incur an irreducible error (bias), and only apply to cases where all factors have the same structure. To this end, we develop a provable algorithm for online structured tensor factorization, wherein one of the factors obeys some incoherence conditions, and the others are sparse. Specifically we show that, under some relatively mild conditions on initialization, rank, and sparsity, our algorithm recovers the factors exactly (up to scaling and permutation) at a linear rate. Complementary to our theoretical results, our synthetic and real-world data evaluations showcase superior performance compared to related techniques. Moreover, its scalability and ability to learn on-the-fly makes it suitable for real-world tasks.
A Provably Communication-Efficient Asynchronous Distributed Inference Method for Convex and Nonconvex Problems
Mar 16, 2019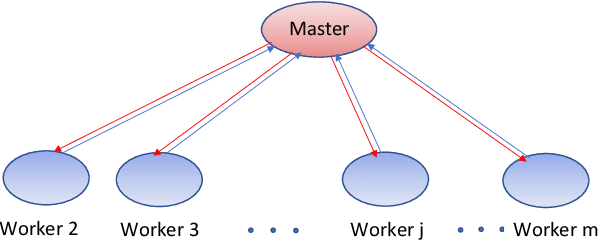
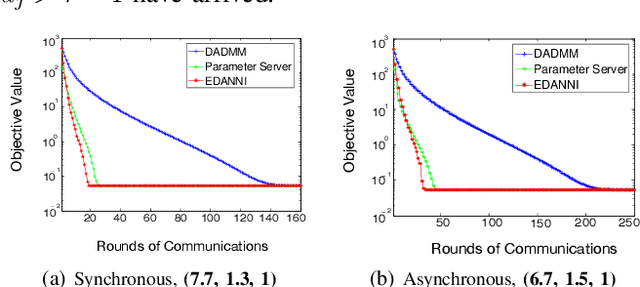
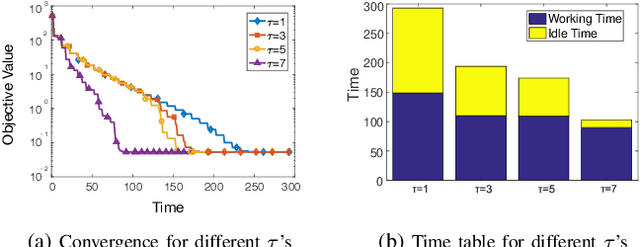
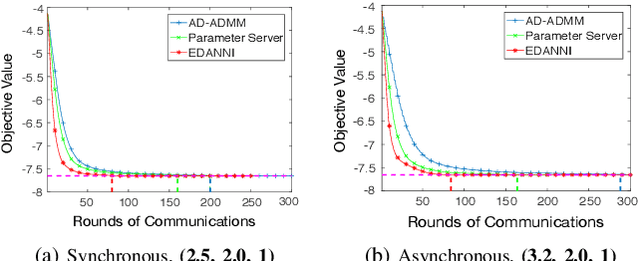
This paper proposes and analyzes a communication-efficient distributed optimization framework for general nonconvex nonsmooth signal processing and machine learning problems under an asynchronous protocol. At each iteration, worker machines compute gradients of a known empirical loss function using their own local data, and a master machine solves a related minimization problem to update the current estimate. We prove that for nonconvex nonsmooth problems, the proposed algorithm converges with a sublinear rate over the number of communication rounds, coinciding with the best theoretical rate that can be achieved for this class of problems. Linear convergence is established without any statistical assumptions of the local data for problems characterized by composite loss functions whose smooth parts are strongly convex. Extensive numerical experiments verify that the performance of the proposed approach indeed improves -- sometimes significantly -- over other state-of-the-art algorithms in terms of total communication efficiency.
NOODL: Provable Online Dictionary Learning and Sparse Coding
Mar 15, 2019



We consider the dictionary learning problem, where the aim is to model the given data as a linear combination of a few columns of a matrix known as a dictionary, where the sparse weights forming the linear combination are known as coefficients. Since the dictionary and coefficients, parameterizing the linear model are unknown, the corresponding optimization is inherently non-convex. This was a major challenge until recently, when provable algorithms for dictionary learning were proposed. Yet, these provide guarantees only on the recovery of the dictionary, without explicit recovery guarantees on the coefficients. Moreover, any estimation error in the dictionary adversely impacts the ability to successfully localize and estimate the coefficients. This potentially limits the utility of existing provable dictionary learning methods in applications where coefficient recovery is of interest. To this end, we develop NOODL: a simple Neurally plausible alternating Optimization-based Online Dictionary Learning algorithm, which recovers both the dictionary and coefficients exactly at a geometric rate, when initialized appropriately. Our algorithm, NOODL, is also scalable and amenable for large scale distributed implementations in neural architectures, by which we mean that it only involves simple linear and non-linear operations. Finally, we corroborate these theoretical results via experimental evaluation of the proposed algorithm with the current state-of-the-art techniques.
TensorMap: Lidar-Based Topological Mapping and Localization via Tensor Decompositions
Feb 26, 2019
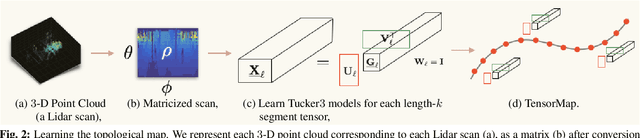


We propose a technique to develop (and localize in) topological maps from light detection and ranging (Lidar) data. Localizing an autonomous vehicle with respect to a reference map in real-time is crucial for its safe operation. Owing to the rich information provided by Lidar sensors, these are emerging as a promising choice for this task. However, since a Lidar outputs a large amount of data every fraction of a second, it is progressively harder to process the information in real-time. Consequently, current systems have migrated towards faster alternatives at the expense of accuracy. To overcome this inherent trade-off between latency and accuracy, we propose a technique to develop topological maps from Lidar data using the orthogonal Tucker3 tensor decomposition. Our experimental evaluations demonstrate that in addition to achieving a high compression ratio as compared to full data, the proposed technique, $\textit{TensorMap}$, also accurately detects the position of the vehicle in a graph-based representation of a map. We also analyze the robustness of the proposed technique to Gaussian and translational noise, thus initiating explorations into potential applications of tensor decompositions in Lidar data analysis.
* 5 pages; Index Terms - Topological maps, Lidar, Localization of Autonomous Vehicles, Orthogonal Tucker Decomposition, and Scan-matching