 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Scene Graphs in Visual Question Answering
Jan 17, 2021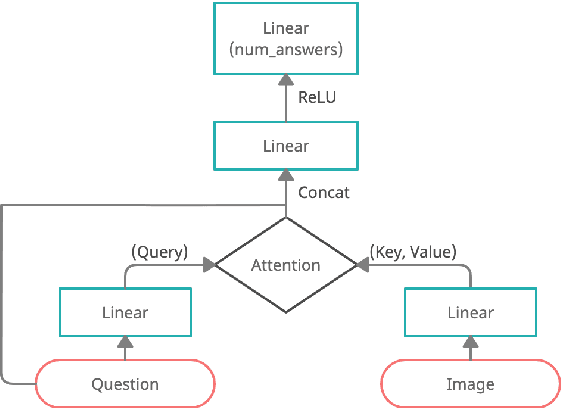
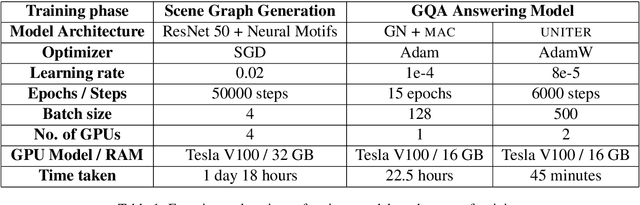
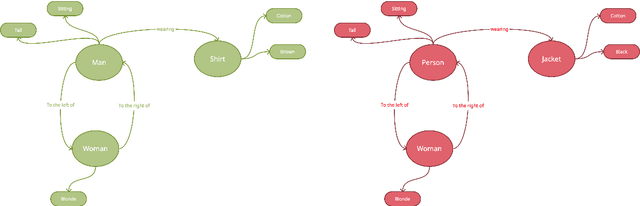
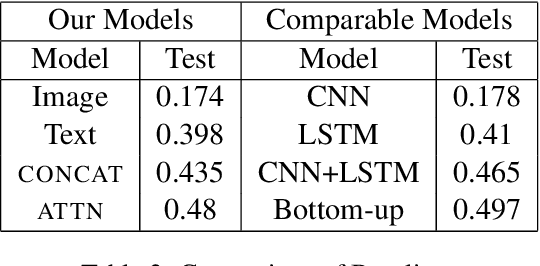
Visual Question Answering (VQA) is of tremendous interest to the research community with important applications such as aiding visually impaired users and image-based search. In this work, we explore the use of scene graphs for solving the VQA task. We conduct experiments on the GQA dataset which presents a challenging set of questions requiring counting, compositionality and advanced reasoning capability, and provides scene graphs for a large number of images. We adopt image + question architectures for use with scene graphs, evaluate various scene graph generation techniques for unseen images, propose a training curriculum to leverage human-annotated and auto-generated scene graphs, and build late fusion architectures to learn from multiple image representations. We present a multi-faceted study into the use of scene graphs for VQA, making this work the first of its kind.