 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Insight Extraction for Contact Center Analytics and Cost-Efficient Deployment
Mar 24, 2025Large Language Models have transformed the Contact Center industry, manifesting in enhanced self-service tools, streamlined administrative processes, and augmented agent productivity. This paper delineates our system that automates call driver generation, which serves as the foundation for tasks such as topic modeling, incoming call classification, trend detection, and FAQ generation, delivering actionable insights for contact center agents and administrators to consume. We present a cost-efficient LLM system design, with 1) a comprehensive evaluation of proprietary, open-weight, and fine-tuned models and 2) cost-efficient strategies, and 3) the corresponding cost analysis when deployed in production environments.
Mitigating Gender Bias in Contextual Word Embeddings
Nov 18, 2024Word embeddings have been shown to produce remarkable results in tackling a vast majority of NLP related tasks. Unfortunately, word embeddings also capture the stereotypical biases that are prevalent in society, affecting the predictive performance of the embeddings when used in downstream tasks. While various techniques have been proposed \cite{bolukbasi2016man, zhao2018learning} and criticized\cite{gonen2019lipstick} for static embeddings, very little work has focused on mitigating bias in contextual embeddings. In this paper, we propose a novel objective function for MLM(Masked-Language Modeling) which largely mitigates the gender bias in contextual embeddings and also preserves the performance for downstream tasks. Since previous works on measuring bias in contextual embeddings lack in normative reasoning, we also propose novel evaluation metrics that are straight-forward and aligned with our motivations in debiasing. We also propose new methods for debiasing static embeddings and provide empirical proof via extensive analysis and experiments, as to why the main source of bias in static embeddings stems from the presence of stereotypical names rather than gendered words themselves. All experiments and embeddings studied are in English, unless otherwise specified.\citep{bender2011achieving}.
Understanding the Role of Scene Graphs in Visual Question Answering
Jan 17, 2021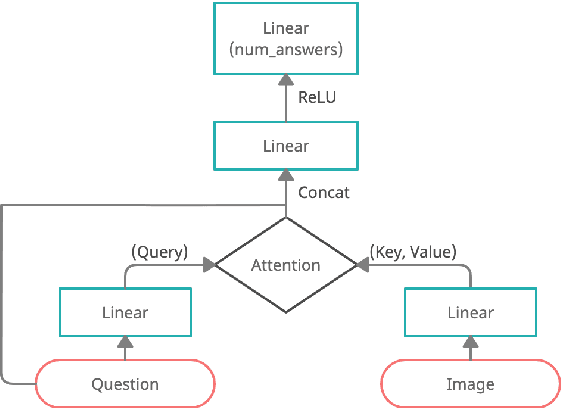
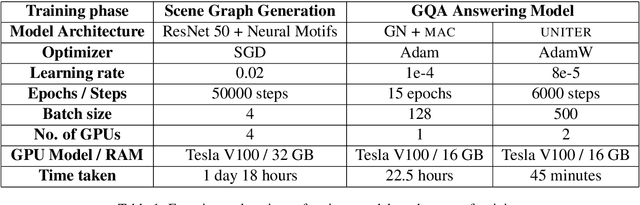
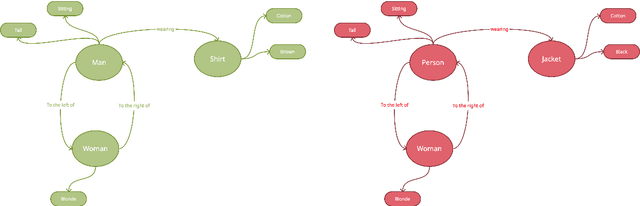
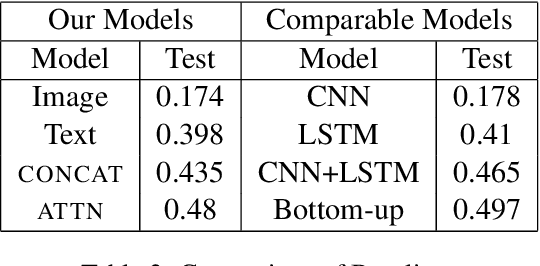
Visual Question Answering (VQA) is of tremendous interest to the research community with important applications such as aiding visually impaired users and image-based search. In this work, we explore the use of scene graphs for solving the VQA task. We conduct experiments on the GQA dataset which presents a challenging set of questions requiring counting, compositionality and advanced reasoning capability, and provides scene graphs for a large number of images. We adopt image + question architectures for use with scene graphs, evaluate various scene graph generation techniques for unseen images, propose a training curriculum to leverage human-annotated and auto-generated scene graphs, and build late fusion architectures to learn from multiple image representations. We present a multi-faceted study into the use of scene graphs for VQA, making this work the first of its kind.