 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Multihop Source Retrieval for Web Question Answering
Jan 07, 2025



This work deals with the challenge of learning and reasoning over multi-modal multi-hop question answering (QA). We propose a graph reasoning network based on the semantic structure of the sentences to learn multi-source reasoning paths and find the supporting facts across both image and text modalities for answering the question. In this paper, we investigate the importance of graph structure for multi-modal multi-hop question answering. Our analysis is centered on WebQA. We construct a strong baseline model, that finds relevant sources using a pairwise classification task. We establish that, with the proper use of feature representations from pre-trained models, graph structure helps in improving multi-modal multi-hop question answering. We point out that both graph structure and adjacency matrix are task-related prior knowledge, and graph structure can be leveraged to improve the retrieval performance for the task. Experiments and visualized analysis demonstrate that message propagation over graph networks or the entire graph structure can replace massive multimodal transformers with token-wise cross-attention. We demonstrated the applicability of our method and show a performance gain of \textbf{4.6$\%$} retrieval F1score over the transformer baselines, despite being a very light model. We further demonstrated the applicability of our model to a large scale retrieval setting.
Multilingual Open QA on the MIA Shared Task
Jan 07, 2025Cross-lingual information retrieval (CLIR) ~\cite{shi2021cross, asai2021one, jiang2020cross} for example, can find relevant text in any language such as English(high resource) or Telugu (low resource) even when the query is posed in a different, possibly low-resource, language. In this work, we aim to develop useful CLIR models for this constrained, yet important, setting where we do not require any kind of additional supervision or labelled data for retrieval task and hence can work effectively for low-resource languages. \par We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot multilingual question generation model, which is a pre-trained language model, to compute the probability of the input question in the target language conditioned on a retrieved passage, which can be possibly in a different language. We evaluate our method in a completely zero shot setting and doesn't require any training. Thus the main advantage of our method is that our approach can be used to re-rank results obtained by any sparse retrieval methods like BM-25. This eliminates the need for obtaining expensive labelled corpus required for the retrieval tasks and hence can be used for low resource languages.
Mitigating Gender Bias in Contextual Word Embeddings
Nov 18, 2024Word embeddings have been shown to produce remarkable results in tackling a vast majority of NLP related tasks. Unfortunately, word embeddings also capture the stereotypical biases that are prevalent in society, affecting the predictive performance of the embeddings when used in downstream tasks. While various techniques have been proposed \cite{bolukbasi2016man, zhao2018learning} and criticized\cite{gonen2019lipstick} for static embeddings, very little work has focused on mitigating bias in contextual embeddings. In this paper, we propose a novel objective function for MLM(Masked-Language Modeling) which largely mitigates the gender bias in contextual embeddings and also preserves the performance for downstream tasks. Since previous works on measuring bias in contextual embeddings lack in normative reasoning, we also propose novel evaluation metrics that are straight-forward and aligned with our motivations in debiasing. We also propose new methods for debiasing static embeddings and provide empirical proof via extensive analysis and experiments, as to why the main source of bias in static embeddings stems from the presence of stereotypical names rather than gendered words themselves. All experiments and embeddings studied are in English, unless otherwise specified.\citep{bender2011achieving}.
Rich-Item Recommendations for Rich-Users via GCNN: Exploiting Dynamic and Static Side Information
Jan 28, 2020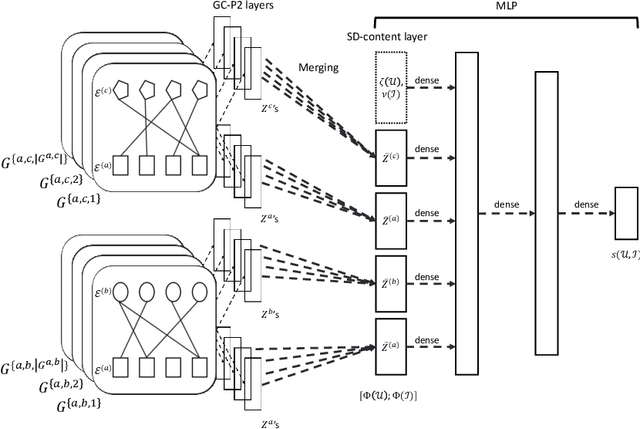
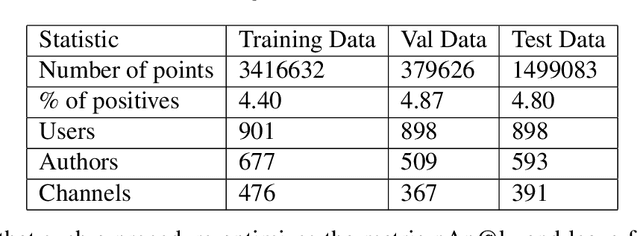
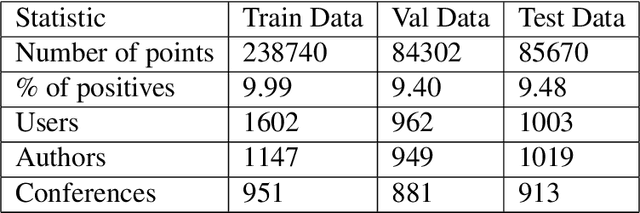
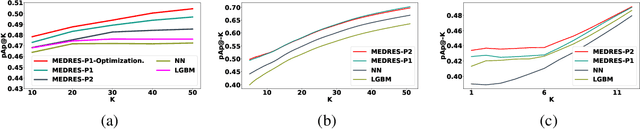
We study the standard problem of recommending relevant items to users; a user is someone who seeks recommendation, and an item is something which should be recommended. In today's modern world, both users and items are 'rich' multi-faceted entities but existing literature, for ease of modeling, views these facets in silos. In this paper, we provide a general formulation of the recommendation problem that captures the complexities of modern systems and encompasses most of the existing recommendation system formulations. In our formulation, each user and item is modeled via a set of static entities and a dynamic component. The relationships between entities are captured by multiple weighted bipartite graphs. To effectively exploit these complex interactions for recommendations, we propose MEDRES -- a multiple graph-CNN based novel deep-learning architecture. In addition, we propose a new metric, pAp@k, that is critical for a variety of classification+ranking scenarios. We also provide an optimization algorithm that directly optimizes the proposed metric and trains MEDRES in an end-to-end framework. We demonstrate the effectiveness of our method on two benchmarks as well as on a message recommendation system deployed in Microsoft Teams where it improves upon the existing production-grade model by 3%.