 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisherSFT: Data-Efficient Supervised Fine-Tuning of Language Models Using Information Gain
May 20, 2025Supervised fine-tuning (SFT) is a standard approach to adapting large language models (LLMs) to new domains. In this work, we improve the statistical efficiency of SFT by selecting an informative subset of training examples. Specifically, for a fixed budget of training examples, which determines the computational cost of fine-tuning, we determine the most informative ones. The key idea in our method is to select examples that maximize information gain, measured by the Hessian of the log-likelihood of the LLM. We approximate it efficiently by linearizing the LLM at the last layer using multinomial logistic regression models. Our approach is computationally efficient, analyzable, and performs well empirically. We demonstrate this on several problems, and back our claims with both quantitative results and an LLM evaluation.
An Efficient Plugin Method for Metric Optimization of Black-Box Models
Mar 03, 2025Many machine learning algorithms and classifiers are available only via API queries as a ``black-box'' -- that is, the downstream user has no ability to change, re-train, or fine-tune the model on a particular target distribution. Indeed, the downstream user may not even have knowledge of the \emph{original} training distribution or performance metric used to construct and optimize the black-box model. We propose a simple and efficient method, Plugin, which \emph{post-processes} arbitrary multiclass predictions from any black-box classifier in order to simultaneously (1) adapt these predictions to a target distribution; and (2) optimize a particular metric of the confusion matrix. Importantly, Plugin is a completely \textit{post-hoc} method which does not rely on feature information, only requires a small amount of probabilistic predictions along with their corresponding true label, and optimizes metrics by querying. We empirically demonstrate that Plugin is both broadly applicable and has performance competitive with related methods on a variety of tabular and language tasks.
Comparing Few to Rank Many: Active Human Preference Learning using Randomized Frank-Wolfe
Dec 27, 2024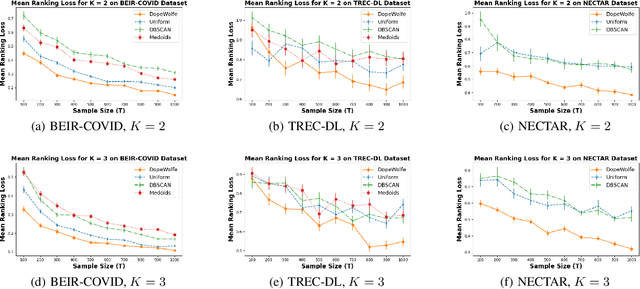

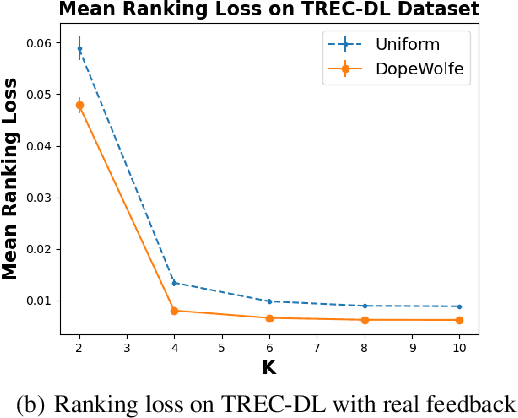
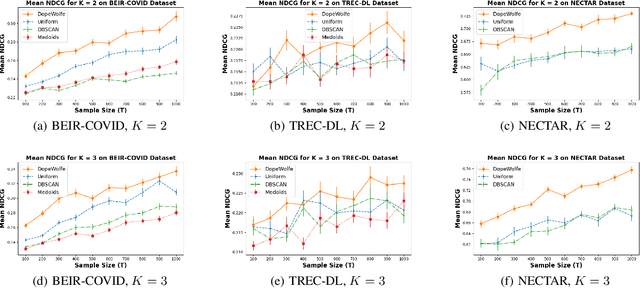
We study learning of human preferences from a limited comparison feedback. This task is ubiquitous in machine learning. Its applications such as reinforcement learning from human feedback, have been transformational. We formulate this problem as learning a Plackett-Luce model over a universe of $N$ choices from $K$-way comparison feedback, where typically $K \ll N$. Our solution is the D-optimal design for the Plackett-Luce objective. The design defines a data logging policy that elicits comparison feedback for a small collection of optimally chosen points from all ${N \choose K}$ feasible subsets. The main algorithmic challenge in this work is that even fast methods for solving D-optimal designs would have $O({N \choose K})$ time complexity. To address this issue, we propose a randomized Frank-Wolfe (FW) algorithm that solves the linear maximization sub-problems in the FW method on randomly chosen variables. We analyze the algorithm, and evaluate it empirically on synthetic and open-source NLP datasets.
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Jul 20, 2024



Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
Context-Aware Clustering using Large Language Models
May 02, 2024Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
ForeSeer: Product Aspect Forecasting Using Temporal Graph Embedding
Oct 07, 2023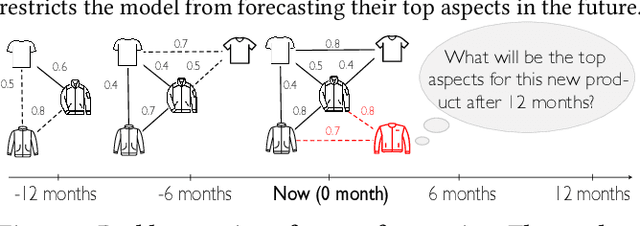
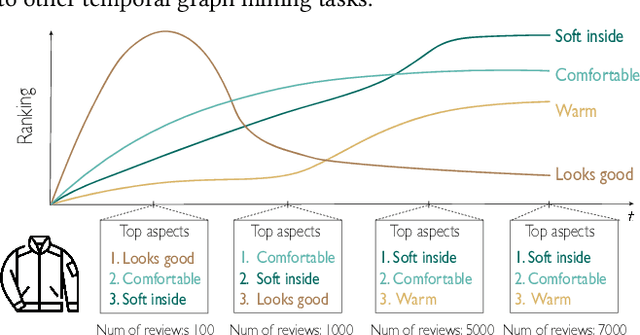
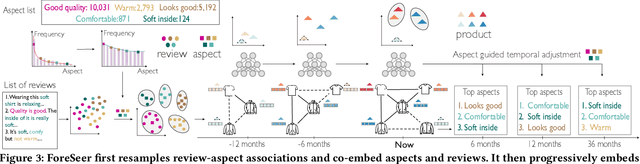
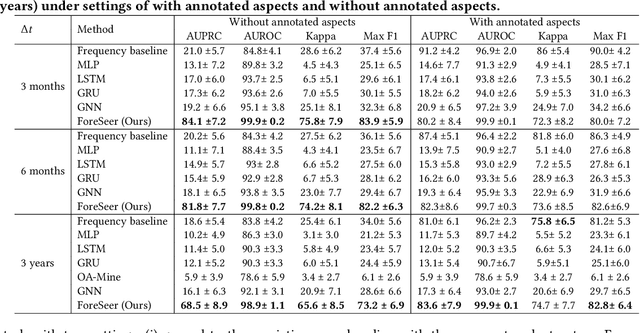
Developing text mining approaches to mine aspects from customer reviews has been well-studied due to its importance in understanding customer needs and product attributes. In contrast, it remains unclear how to predict the future emerging aspects of a new product that currently has little review information. This task, which we named product aspect forecasting, is critical for recommending new products, but also challenging because of the missing reviews. Here, we propose ForeSeer, a novel textual mining and product embedding approach progressively trained on temporal product graphs for this novel product aspect forecasting task. ForeSeer transfers reviews from similar products on a large product graph and exploits these reviews to predict aspects that might emerge in future reviews. A key novelty of our method is to jointly provide review, product, and aspect embeddings that are both time-sensitive and less affected by extremely imbalanced aspect frequencies. We evaluated ForeSeer on a real-world product review system containing 11,536,382 reviews and 11,000 products over 3 years. We observe that ForeSeer substantially outperformed existing approaches with at least 49.1\% AUPRC improvement under the real setting where aspect associations are not given. ForeSeer further improves future link prediction on the product graph and the review aspect association prediction. Collectively, Foreseer offers a novel framework for review forecasting by effectively integrating review text, product network, and temporal information, opening up new avenues for online shopping recommendation and e-commerce applications.
Metric Elicitation; Moving from Theory to Practice
Dec 07, 2022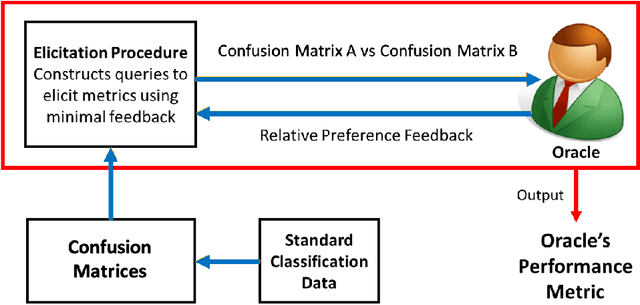
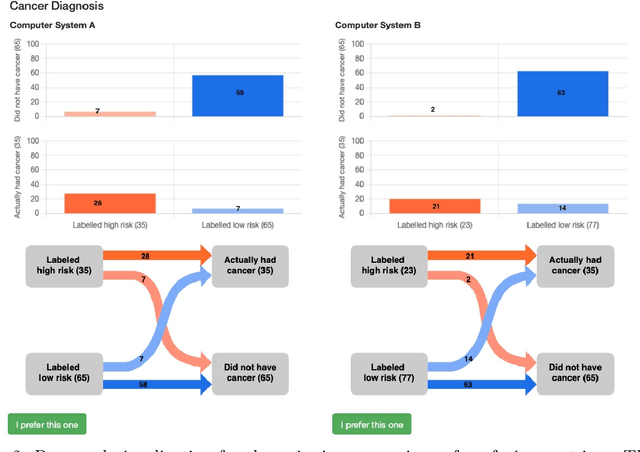
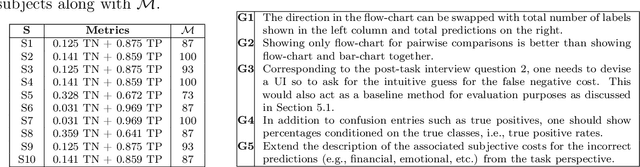
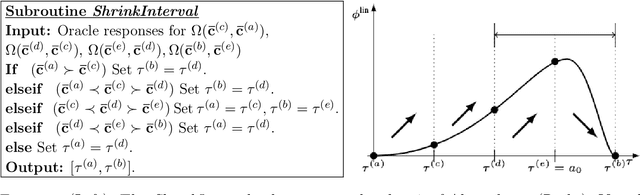
Metric Elicitation (ME) is a framework for eliciting classification metrics that better align with implicit user preferences based on the task and context. The existing ME strategy so far is based on the assumption that users can most easily provide preference feedback over classifier statistics such as confusion matrices. This work examines ME, by providing a first ever implementation of the ME strategy. Specifically, we create a web-based ME interface and conduct a user study that elicits users' preferred metrics in a binary classification setting. We discuss the study findings and present guidelines for future research in this direction.
Classification Performance Metric Elicitation and its Applications
Aug 19, 2022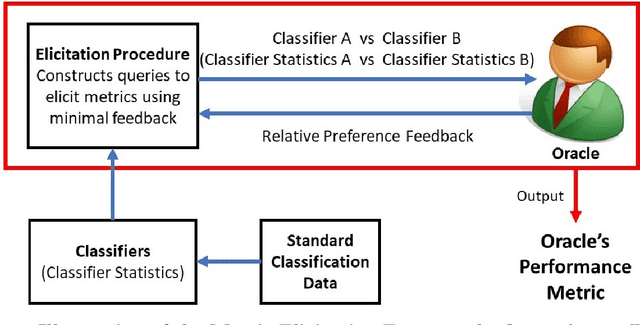



Given a learning problem with real-world tradeoffs, which cost function should the model be trained to optimize? This is the metric selection problem in machine learning. Despite its practical interest, there is limited formal guidance on how to select metrics for machine learning applications. This thesis outlines metric elicitation as a principled framework for selecting the performance metric that best reflects implicit user preferences. Once specified, the evaluation metric can be used to compare and train models. In this manuscript, we formalize the problem of Metric Elicitation and devise novel strategies for eliciting classification performance metrics using pairwise preference feedback over classifiers. Specifically, we provide novel strategies for eliciting linear and linear-fractional metrics for binary and multiclass classification problems, which are then extended to a framework that elicits group-fair performance metrics in the presence of multiple sensitive groups. All the elicitation strategies that we discuss are robust to both finite sample and feedback noise, thus are useful in practice for real-world applications. Using the tools and the geometric characterizations of the feasible confusion statistics sets from the binary, multiclass, and multiclass-multigroup classification setups, we further provide strategies to elicit from a wider range of complex, modern multiclass metrics defined by quadratic functions of confusion statistics by exploiting their local linear structure. From application perspective, we also propose to use the metric elicitation framework in optimizing complex black box metrics that is amenable to deep network training. Lastly, to bring theory closer to practice, we conduct a preliminary real-user study that shows the efficacy of the metric elicitation framework in recovering the users' preferred performance metric in a binary classification setup.
Optimizing Black-box Metrics with Iterative Example Weighting
Feb 18, 2021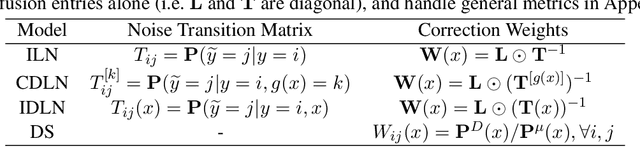
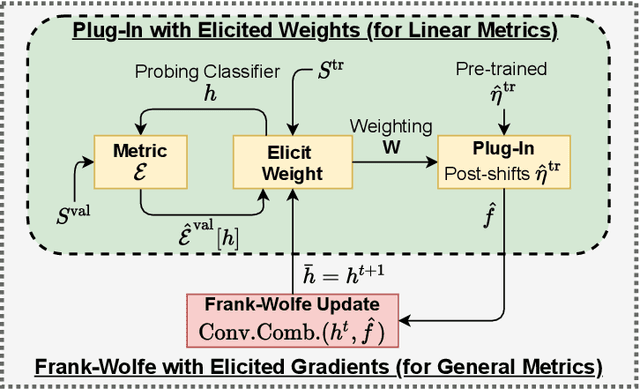
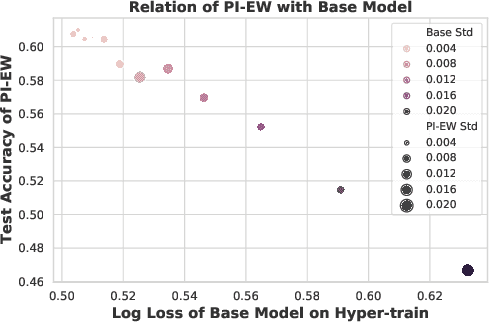
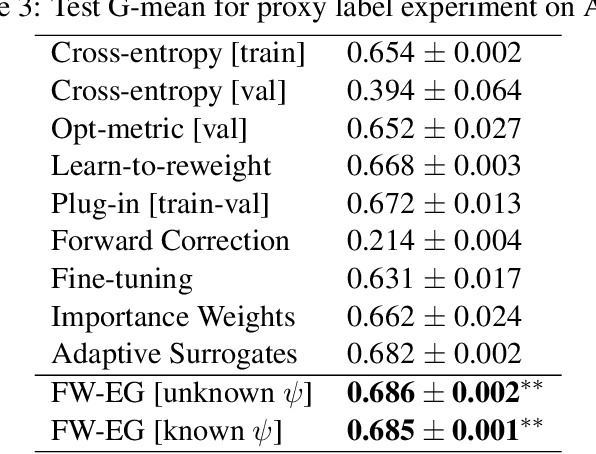
We consider learning to optimize a classification metric defined by a black-box function of the confusion matrix. Such black-box learning settings are ubiquitous, for example, when the learner only has query access to the metric of interest, or in noisy-label and domain adaptation applications where the learner must evaluate the metric via performance evaluation using a small validation sample. Our approach is to adaptively learn example weights on the training dataset such that the resulting weighted objective best approximates the metric on the validation sample. We show how to model and estimate the example weights and use them to iteratively post-shift a pre-trained class probability estimator to construct a classifier. We also analyze the resulting procedure's statistical properties. Experiments on various label noise, domain shift, and fair classification setups confirm that our proposal is better than the individual state-of-the-art baselines for each application.
Quadratic Metric Elicitation with Application to Fairness
Nov 03, 2020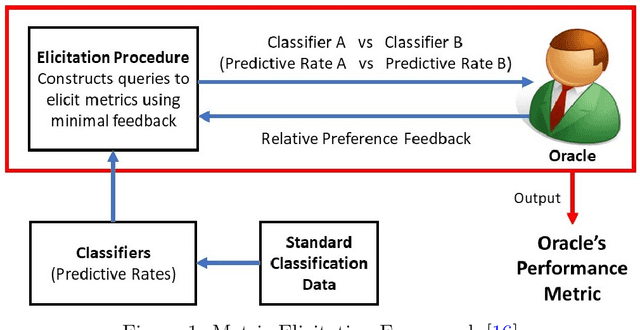
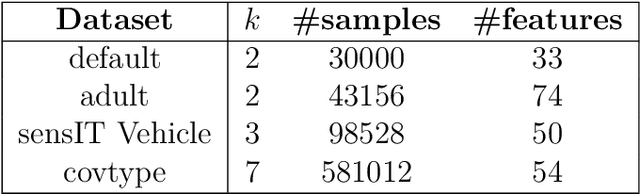
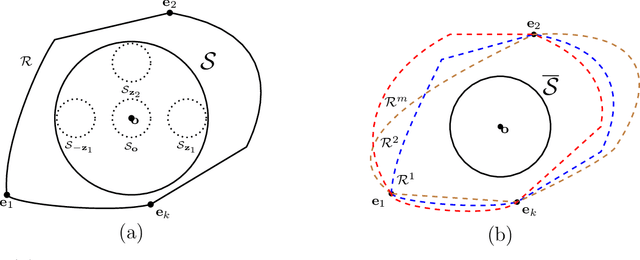
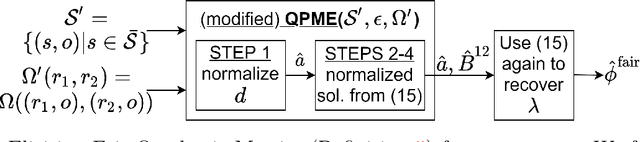
Metric elicitation is a recent framework for eliciting performance metrics that best reflect implicit user preferences. This framework enables a practitioner to adjust the performance metrics based on the application, context, and population at hand. However, available elicitation strategies have been limited to linear (or fractional-linear) functions of predictive rates. In this paper, we develop an approach to elicit from a wider range of complex multiclass metrics defined by quadratic functions of rates by exploiting their local linear structure. We apply this strategy to elicit quadratic metrics for group-based fairness, and also discuss how it can be generalized to higher-order polynomials. Our elicitation strategies require only relative preference feedback and are robust to both feedback and finite sample noise.