 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Plugin Method for Metric Optimization of Black-Box Models
Mar 03, 2025Many machine learning algorithms and classifiers are available only via API queries as a ``black-box'' -- that is, the downstream user has no ability to change, re-train, or fine-tune the model on a particular target distribution. Indeed, the downstream user may not even have knowledge of the \emph{original} training distribution or performance metric used to construct and optimize the black-box model. We propose a simple and efficient method, Plugin, which \emph{post-processes} arbitrary multiclass predictions from any black-box classifier in order to simultaneously (1) adapt these predictions to a target distribution; and (2) optimize a particular metric of the confusion matrix. Importantly, Plugin is a completely \textit{post-hoc} method which does not rely on feature information, only requires a small amount of probabilistic predictions along with their corresponding true label, and optimizes metrics by querying. We empirically demonstrate that Plugin is both broadly applicable and has performance competitive with related methods on a variety of tabular and language tasks.
Unleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
Learn-to-Race Challenge 2022: Benchmarking Safe Learning and Cross-domain Generalisation in Autonomous Racing
May 10, 2022
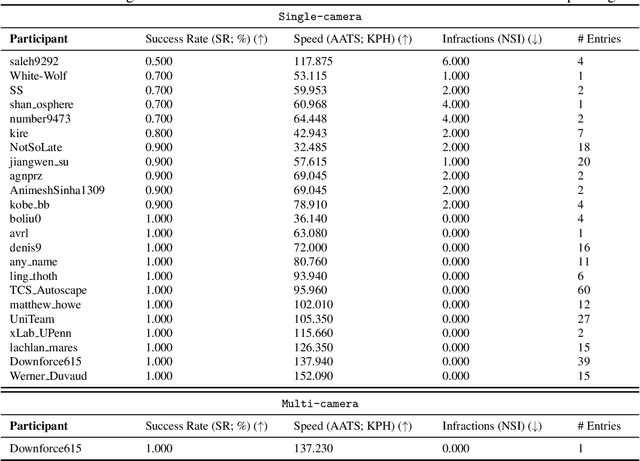

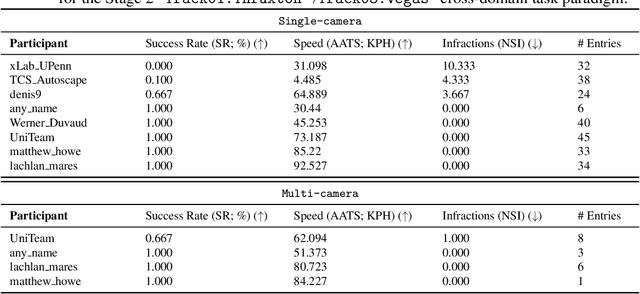
We present the results of our autonomous racing virtual challenge, based on the newly-released Learn-to-Race (L2R) simulation framework, which seeks to encourage interdisciplinary research in autonomous driving and to help advance the state of the art on a realistic benchmark. Analogous to racing being used to test cutting-edge vehicles, we envision autonomous racing to serve as a particularly challenging proving ground for autonomous agents as: (i) they need to make sub-second, safety-critical decisions in a complex, fast-changing environment; and (ii) both perception and control must be robust to distribution shifts, novel road features, and unseen obstacles. Thus, the main goal of the challenge is to evaluate the joint safety, performance, and generalisation capabilities of reinforcement learning agents on multi-modal perception, through a two-stage process. In the first stage of the challenge, we evaluate an autonomous agent's ability to drive as fast as possible, while adhering to safety constraints. In the second stage, we additionally require the agent to adapt to an unseen racetrack through safe exploration. In this paper, we describe the new L2R Task 2.0 benchmark, with refined metrics and baseline approaches. We also provide an overview of deployment, evaluation, and rankings for the inaugural instance of the L2R Autonomous Racing Virtual Challenge (supported by Carnegie Mellon University, Arrival Ltd., AICrowd, Amazon Web Services, and Honda Research), which officially used the new L2R Task 2.0 benchmark and received over 20,100 views, 437 active participants, 46 teams, and 733 model submissions -- from 88+ unique institutions, in 58+ different countries. Finally, we release leaderboard results from the challenge and provide description of the two top-ranking approaches in cross-domain model transfer, across multiple sensor configurations and simulated races.
Distributed Multi-Agent Deep Reinforcement Learning Framework for Whole-building HVAC Control
Oct 26, 2021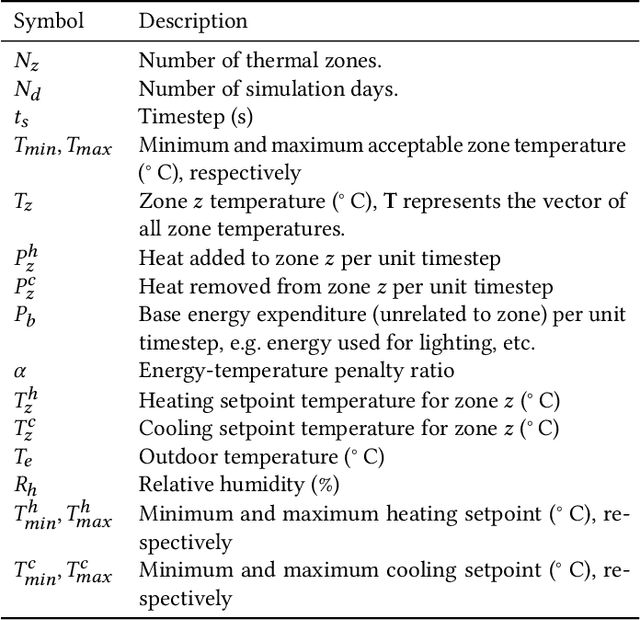
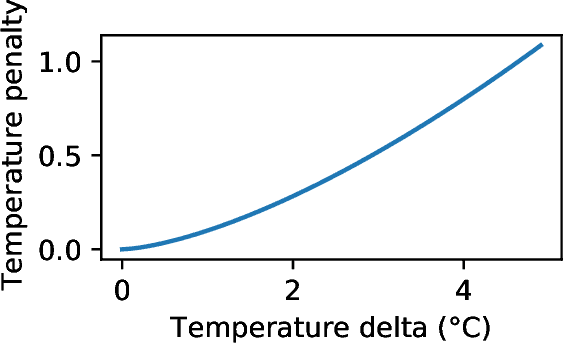
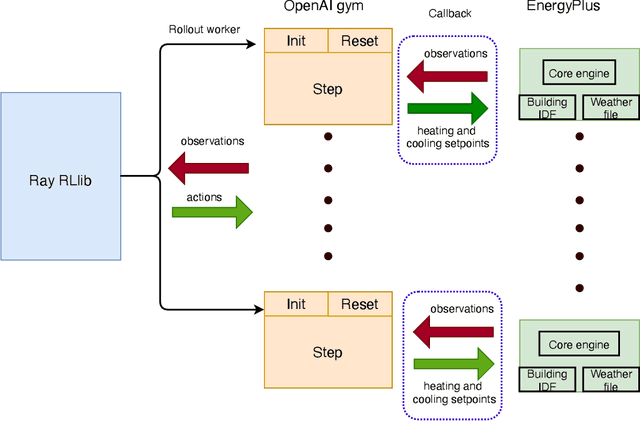
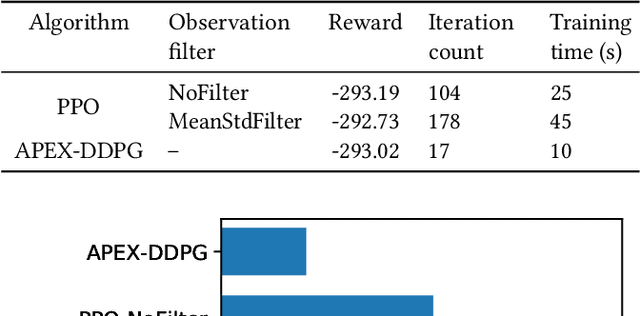
It is estimated that about 40%-50% of total electricity consumption in commercial buildings can be attributed to Heating, Ventilation, and Air Conditioning (HVAC) systems. Minimizing the energy cost while considering the thermal comfort of the occupants is very challenging due to unknown and complex relationships between various HVAC controls and thermal dynamics inside a building. To this end, we present a multi-agent, distributed deep reinforcement learning (DRL) framework based on Energy Plus simulation environment for optimizing HVAC in commercial buildings. This framework learns the complex thermal dynamics in the building and takes advantage of the differential effect of cooling and heating systems in the building to reduce energy costs, while maintaining the thermal comfort of the occupants. With adaptive penalty, the RL algorithm can be prioritized for energy savings or maintaining thermal comfort. Using DRL, we achieve more than 75\% savings in energy consumption. The distributed DRL framework can be scaled to multiple GPUs and CPUs of heterogeneous types.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
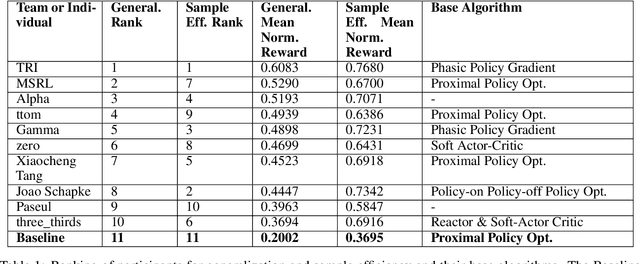
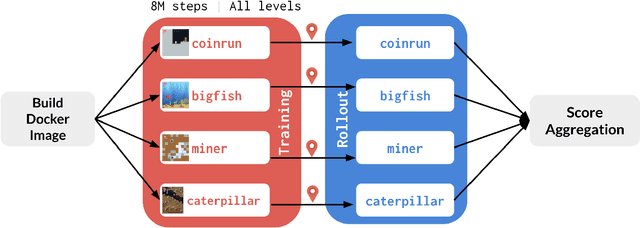
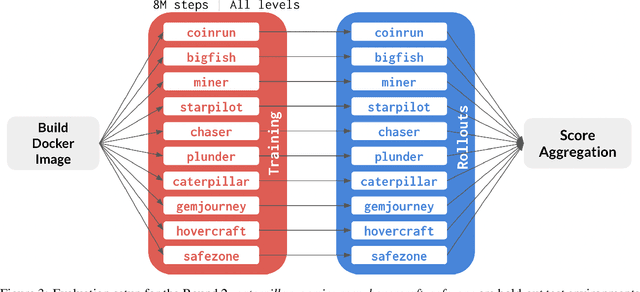
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
REPAINT: Knowledge Transfer in Deep Actor-Critic Reinforcement Learning
Nov 24, 2020
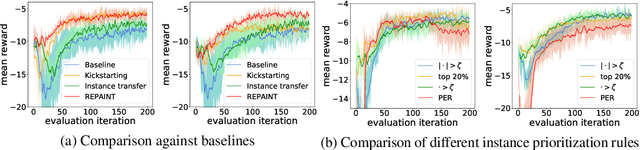
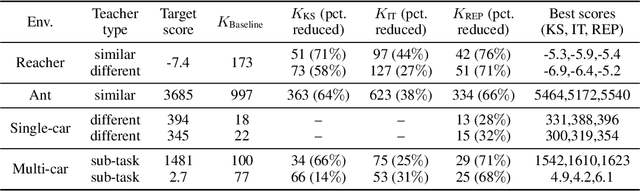
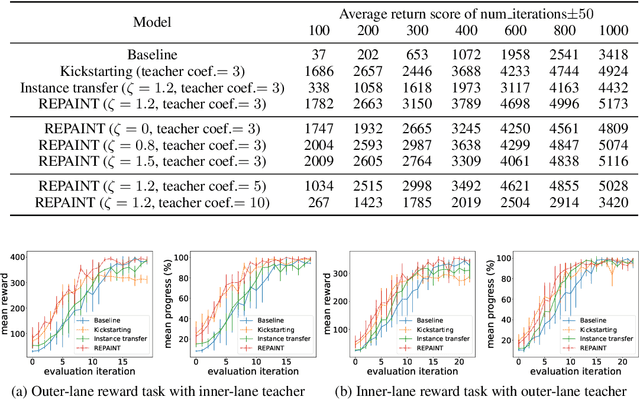
Accelerating the learning processes for complex tasks by leveraging previously learned tasks has been one of the most challenging problems in reinforcement learning, especially when the similarity between source and target tasks is low or unknown. In this work, we propose a REPresentation-And-INstance Transfer algorithm (REPAINT) for deep actor-critic reinforcement learning paradigm. In representation transfer, we adopt a kickstarted training method using a pre-trained teacher policy by introducing an auxiliary cross-entropy loss. In instance transfer, we develop a sampling approach, i.e., advantage-based experience replay, on transitions collected following the teacher policy, where only the samples with high advantage estimates are retained for policy update. We consider both learning an unseen target task by transferring from previously learned teacher tasks and learning a partially unseen task composed of multiple sub-tasks by transferring from a pre-learned teacher sub-task. In several benchmark experiments, REPAINT significantly reduces the total training time and improves the asymptotic performance compared to training with no prior knowledge and other baselines.
Zero-Shot Reinforcement Learning with Deep Attention Convolutional Neural Networks
Jan 02, 2020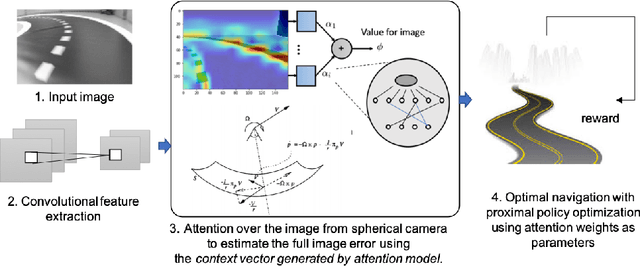
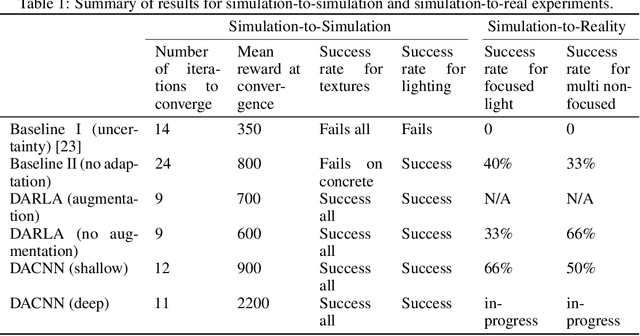
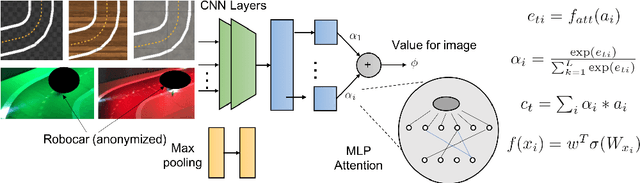

Simulation-to-simulation and simulation-to-real world transfer of neural network models have been a difficult problem. To close the reality gap, prior methods to simulation-to-real world transfer focused on domain adaptation, decoupling perception and dynamics and solving each problem separately, and randomization of agent parameters and environment conditions to expose the learning agent to a variety of conditions. While these methods provide acceptable performance, the computational complexity required to capture a large variation of parameters for comprehensive scenarios on a given task such as autonomous driving or robotic manipulation is high. Our key contribution is to theoretically prove and empirically demonstrate that a deep attention convolutional neural network (DACNN) with specific visual sensor configuration performs as well as training on a dataset with high domain and parameter variation at lower computational complexity. Specifically, the attention network weights are learned through policy optimization to focus on local dependencies that lead to optimal actions, and does not require tuning in real-world for generalization. Our new architecture adapts perception with respect to the control objective, resulting in zero-shot learning without pre-training a perception network. To measure the impact of our new deep network architecture on domain adaptation, we consider autonomous driving as a use case. We perform an extensive set of experiments in simulation-to-simulation and simulation-to-real scenarios to compare our approach to several baselines including the current state-of-art models.
SAVEHR: Self Attention Vector Representations for EHR based Personalized Chronic Disease Onset Prediction and Interpretability
Nov 13, 2019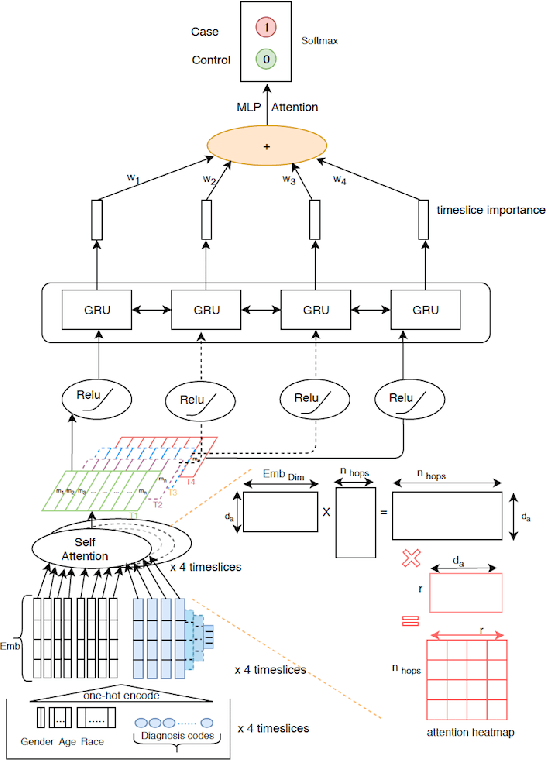
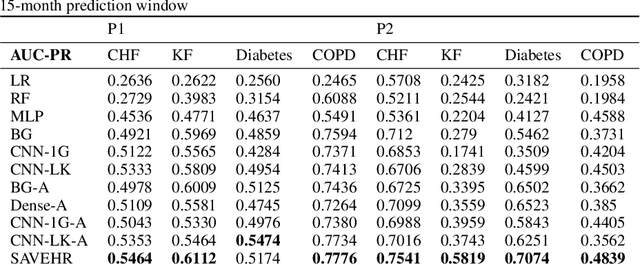

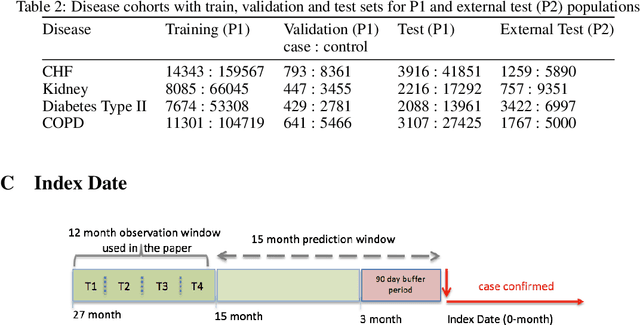
Chronic disease progression is emerging as an important area of investment for healthcare providers. As the quantity and richness of available clinical data continue to increase along with advances in machine learning, there is great potential to advance our approaches to caring for patients. An ideal approach to this problem should generate good performance on at least three axes namely, a) perform across many clinical conditions without requiring deep clinical expertise or extensive data scientist effort, b) generalization across populations, and c) be explainable (model interpretability). We present SAVEHR, a self-attention based architecture on heterogeneous structured EHR data that achieves $>$ 0.51 AUC-PR and $>$ 0.87 AUC-ROC gains on predicting the onset of four clinical conditions (CHF, Kidney Failure, Diabetes and COPD) 15-months in advance, and transfers with high performance onto a new population. We demonstrate that SAVEHR model performs superior to ten baselines on all three axes stated formerly.
DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning
Nov 05, 2019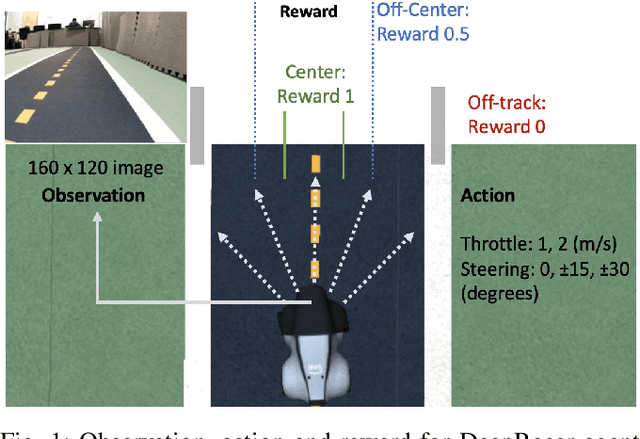



DeepRacer is a platform for end-to-end experimentation with RL and can be used to systematically investigate the key challenges in developing intelligent control systems. Using the platform, we demonstrate how a 1/18th scale car can learn to drive autonomously using RL with a monocular camera. It is trained in simulation with no additional tuning in physical world and demonstrates: 1) formulation and solution of a robust reinforcement learning algorithm, 2) narrowing the reality gap through joint perception and dynamics, 3) distributed on-demand compute architecture for training optimal policies, and 4) a robust evaluation method to identify when to stop training. It is the first successful large-scale deployment of deep reinforcement learning on a robotic control agent that uses only raw camera images as observations and a model-free learning method to perform robust path planning. We open source our code and video demo on GitHub: https://git.io/fjxoJ.