 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Training Improves Zero-Shot Classification of Semi-structured Documents
Oct 11, 2022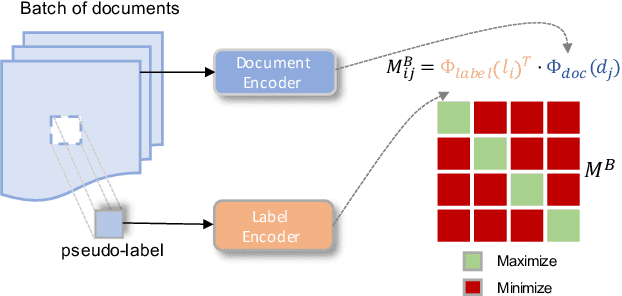


We investigate semi-structured document classification in a zero-shot setting. Classification of semi-structured documents is more challenging than that of standard unstructured documents, as positional, layout, and style information play a vital role in interpreting such documents. The standard classification setting where categories are fixed during both training and testing falls short in dynamic environments where new document categories could potentially emerge. We focus exclusively on the zero-shot setting where inference is done on new unseen classes. To address this task, we propose a matching-based approach that relies on a pairwise contrastive objective for both pretraining and fine-tuning. Our results show a significant boost in Macro F$_1$ from the proposed pretraining step in both supervised and unsupervised zero-shot settings.
Label Semantics for Few Shot Named Entity Recognition
Mar 16, 2022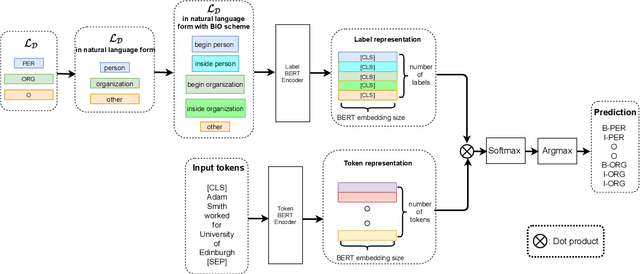
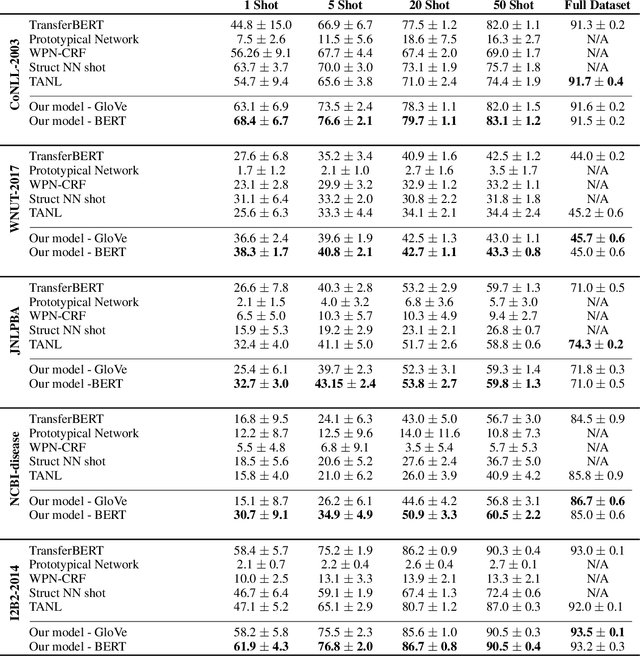
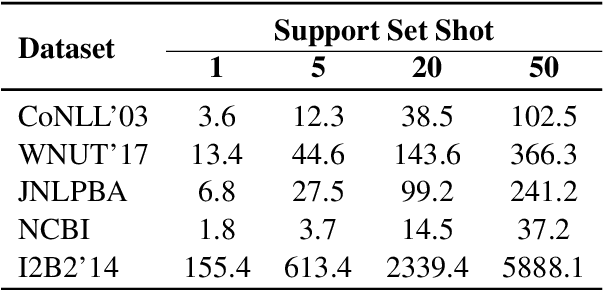
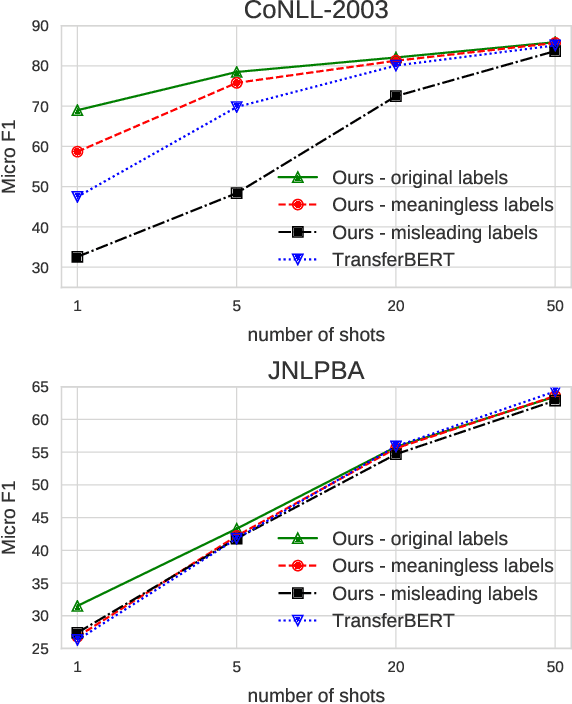
We study the problem of few shot learning for named entity recognition. Specifically, we leverage the semantic information in the names of the labels as a way of giving the model additional signal and enriched priors. We propose a neural architecture that consists of two BERT encoders, one to encode the document and its tokens and another one to encode each of the labels in natural language format. Our model learns to match the representations of named entities computed by the first encoder with label representations computed by the second encoder. The label semantics signal is shown to support improved state-of-the-art results in multiple few shot NER benchmarks and on-par performance in standard benchmarks. Our model is especially effective in low resource settings.
REPAINT: Knowledge Transfer in Deep Actor-Critic Reinforcement Learning
Nov 24, 2020
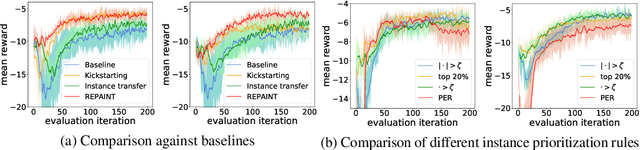
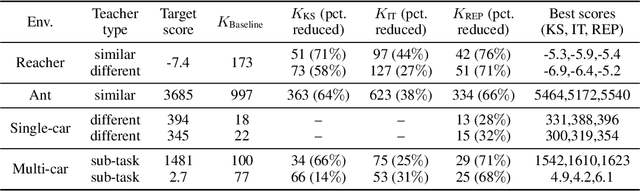
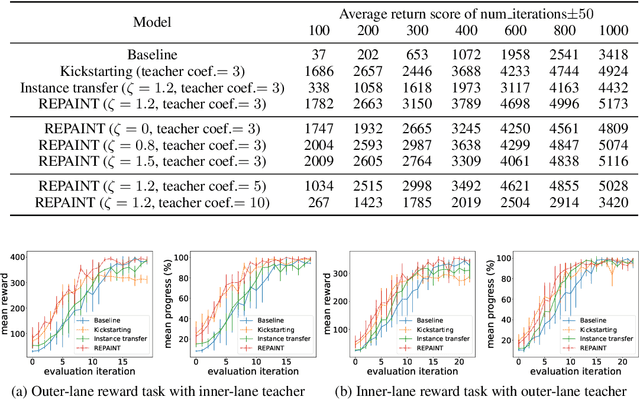
Accelerating the learning processes for complex tasks by leveraging previously learned tasks has been one of the most challenging problems in reinforcement learning, especially when the similarity between source and target tasks is low or unknown. In this work, we propose a REPresentation-And-INstance Transfer algorithm (REPAINT) for deep actor-critic reinforcement learning paradigm. In representation transfer, we adopt a kickstarted training method using a pre-trained teacher policy by introducing an auxiliary cross-entropy loss. In instance transfer, we develop a sampling approach, i.e., advantage-based experience replay, on transitions collected following the teacher policy, where only the samples with high advantage estimates are retained for policy update. We consider both learning an unseen target task by transferring from previously learned teacher tasks and learning a partially unseen task composed of multiple sub-tasks by transferring from a pre-learned teacher sub-task. In several benchmark experiments, REPAINT significantly reduces the total training time and improves the asymptotic performance compared to training with no prior knowledge and other baselines.
Zero-Shot Reinforcement Learning with Deep Attention Convolutional Neural Networks
Jan 02, 2020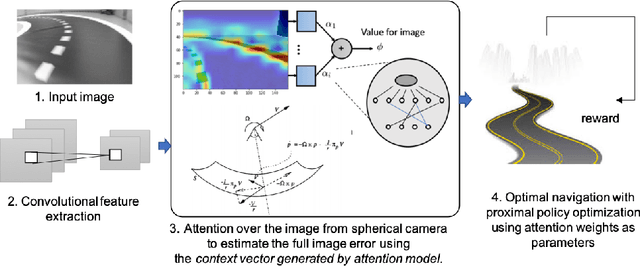
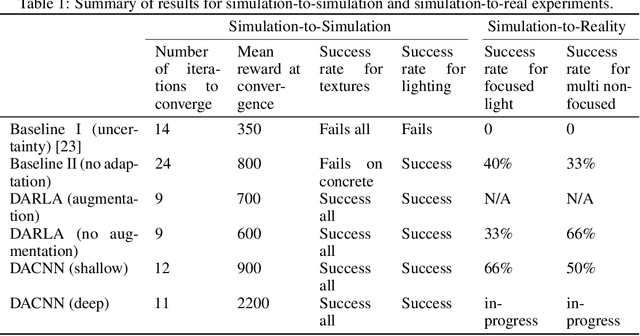
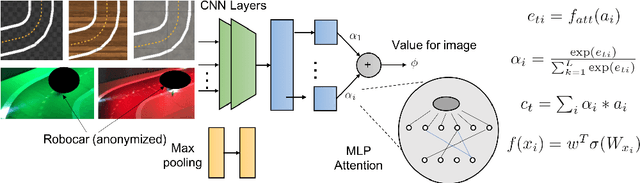

Simulation-to-simulation and simulation-to-real world transfer of neural network models have been a difficult problem. To close the reality gap, prior methods to simulation-to-real world transfer focused on domain adaptation, decoupling perception and dynamics and solving each problem separately, and randomization of agent parameters and environment conditions to expose the learning agent to a variety of conditions. While these methods provide acceptable performance, the computational complexity required to capture a large variation of parameters for comprehensive scenarios on a given task such as autonomous driving or robotic manipulation is high. Our key contribution is to theoretically prove and empirically demonstrate that a deep attention convolutional neural network (DACNN) with specific visual sensor configuration performs as well as training on a dataset with high domain and parameter variation at lower computational complexity. Specifically, the attention network weights are learned through policy optimization to focus on local dependencies that lead to optimal actions, and does not require tuning in real-world for generalization. Our new architecture adapts perception with respect to the control objective, resulting in zero-shot learning without pre-training a perception network. To measure the impact of our new deep network architecture on domain adaptation, we consider autonomous driving as a use case. We perform an extensive set of experiments in simulation-to-simulation and simulation-to-real scenarios to compare our approach to several baselines including the current state-of-art models.
SAVEHR: Self Attention Vector Representations for EHR based Personalized Chronic Disease Onset Prediction and Interpretability
Nov 13, 2019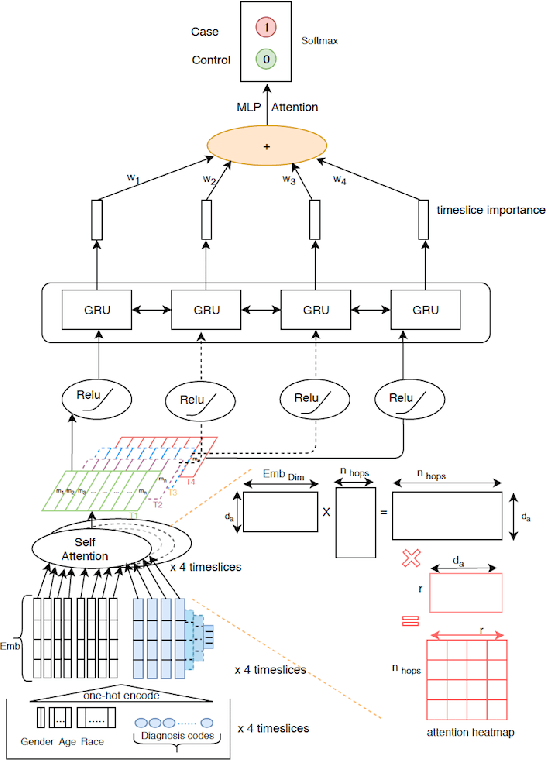
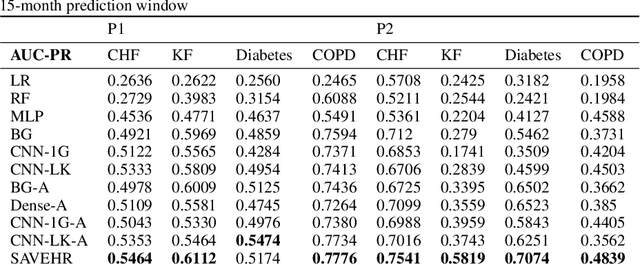

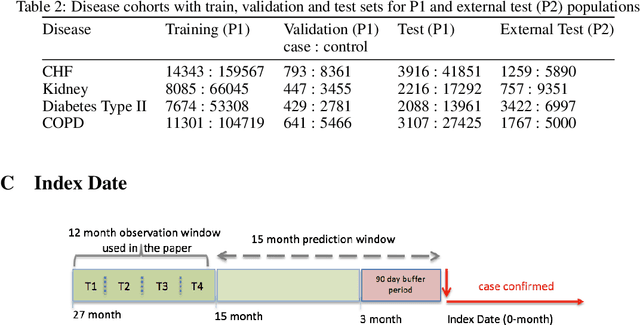
Chronic disease progression is emerging as an important area of investment for healthcare providers. As the quantity and richness of available clinical data continue to increase along with advances in machine learning, there is great potential to advance our approaches to caring for patients. An ideal approach to this problem should generate good performance on at least three axes namely, a) perform across many clinical conditions without requiring deep clinical expertise or extensive data scientist effort, b) generalization across populations, and c) be explainable (model interpretability). We present SAVEHR, a self-attention based architecture on heterogeneous structured EHR data that achieves $>$ 0.51 AUC-PR and $>$ 0.87 AUC-ROC gains on predicting the onset of four clinical conditions (CHF, Kidney Failure, Diabetes and COPD) 15-months in advance, and transfers with high performance onto a new population. We demonstrate that SAVEHR model performs superior to ten baselines on all three axes stated formerly.
DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning
Nov 05, 2019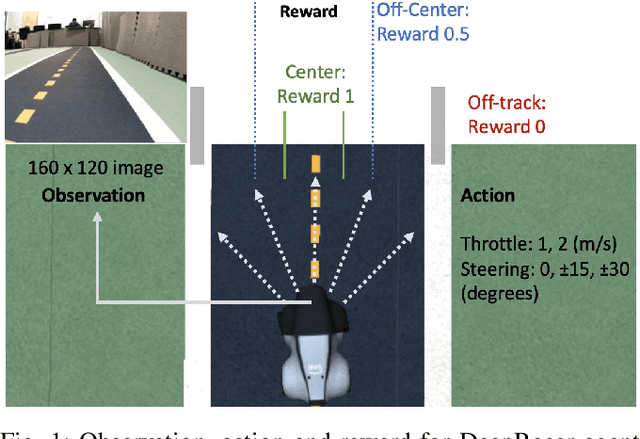



DeepRacer is a platform for end-to-end experimentation with RL and can be used to systematically investigate the key challenges in developing intelligent control systems. Using the platform, we demonstrate how a 1/18th scale car can learn to drive autonomously using RL with a monocular camera. It is trained in simulation with no additional tuning in physical world and demonstrates: 1) formulation and solution of a robust reinforcement learning algorithm, 2) narrowing the reality gap through joint perception and dynamics, 3) distributed on-demand compute architecture for training optimal policies, and 4) a robust evaluation method to identify when to stop training. It is the first successful large-scale deployment of deep reinforcement learning on a robotic control agent that uses only raw camera images as observations and a model-free learning method to perform robust path planning. We open source our code and video demo on GitHub: https://git.io/fjxoJ.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
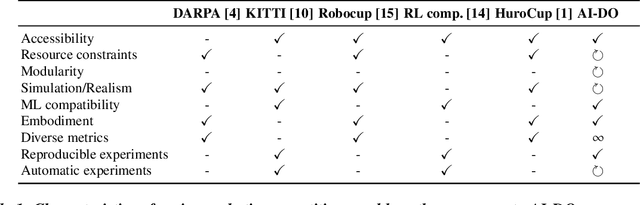
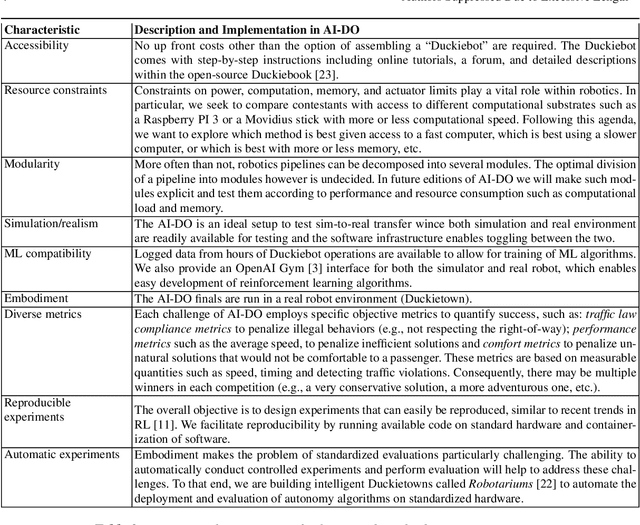

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
Effectiveness of LSTMs in Predicting Congestive Heart Failure Onset
Feb 13, 2019
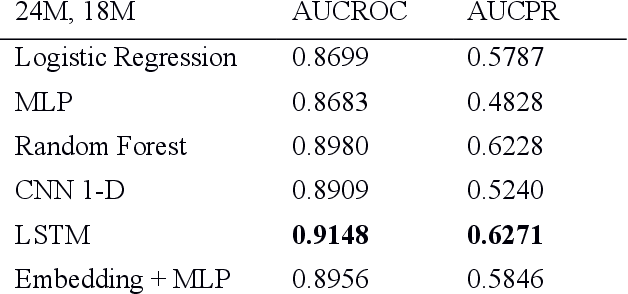
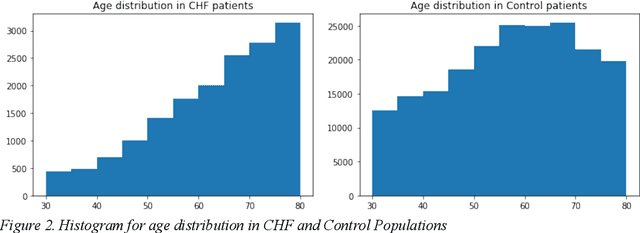
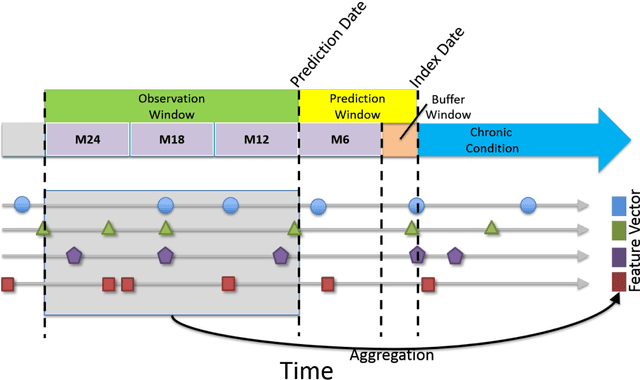
In this paper we present a Recurrent neural networks (RNN) based architecture that achieves an AUCROC of 0.9147 for predicting the onset of Congestive Heart Failure (CHF) 15 months in advance using a 12-month observation window on a large cohort of 216,394 patients. We believe this to be the largest study in CHF onset prediction with respect to the number of CHF case patients in the cohort and the test set (3,332 CHF patients) on which the AUC metrics are reported. We explore the extent to which LSTM (Long Short Term Memory) based model, a variant of RNNs, can accurately predict the onset of CHF when compared to known linear baselines like Logistic Regression, Random Forests and deep learning based models such as Multi-Layer Perceptron and Convolutional Neural Networks. We utilize demographics, medical diagnosis and procedure data from 21,405 CHF and 194,989 control patients to as our features. We describe our feature embedding strategy for medical diagnosis codes that accommodates the sparse, irregular, longitudinal, and high-dimensional characteristics of EHR data. We empirically show that LSTMs can capture the longitudinal aspects of EHR data better than the proposed baselines. As an attempt to interpret the model, we present a temporal data analysis-based technique on false positives to attribute feature importance. A model capable of predicting the onset of congestive heart failure months in the future with this level of accuracy and precision can support efforts of practitioners to implement risk factor reduction strategies and researchers to begin to systematically evaluate interventions to potentially delay or avert development of the disease with high mortality, morbidity and significant costs.