 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing scientific exploration of the deep sea through shared autonomy in remote manipulation
Sep 15, 2023Shared autonomy enables novice remote users to conduct deep-ocean science operations with robotic manipulators.
Accessible Interfaces for the Development and Deployment of Robotic Platforms
May 16, 2023Accessibility is one of the most important features in the design of robots and their interfaces. This thesis proposes methods that improve the accessibility of robots for three different target audiences: consumers, researchers, and learners. In order for humans and robots to work together effectively, they both must be able to communicate with each other. We tackle the problem of generating route instructions that are readily understandable by novice humans for the navigation of a priori unknown indoor environments. We then move on to the related problem of enabling robots to understand natural language utterances in the context of learning to operate articulated objects (e.g., fridges, drawers) by leveraging kinematic models. Next, we turn our focus to the development of accessible and reproducible robotic platforms for scientific research. We propose a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained "by design" from the beginning of the research and development process. We then propose a framework called SHARC (SHared Autonomy for Remote Collaboration), to improve accessibility for underwater robotic intervention operations. SHARC allows multiple remote scientists to efficiently plan and execute high-level sampling procedures using an underwater manipulator while deferring low-level control to the robot. Lastly, we developed the first hardware-based MOOC in AI and robotics. This course allows learners to study autonomy hands-on by making real robots make their own decisions and accomplish broadly defined tasks. We design a new robotic platform from the ground up to support this new learning experience. A fully browser-based interface, based on leading tools and technologies for code development, testing, validation, and deployment serves to maximize the accessibility of these educational resources.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
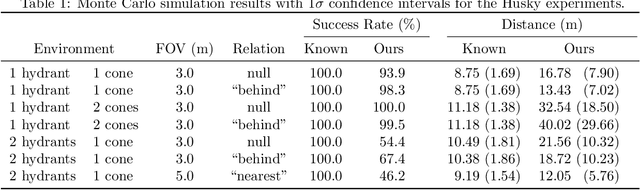

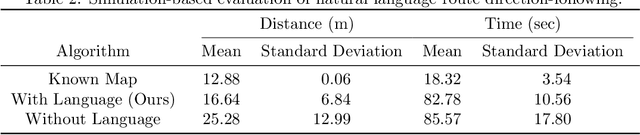
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
Sep 09, 2020
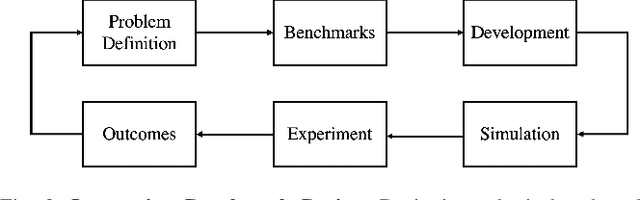
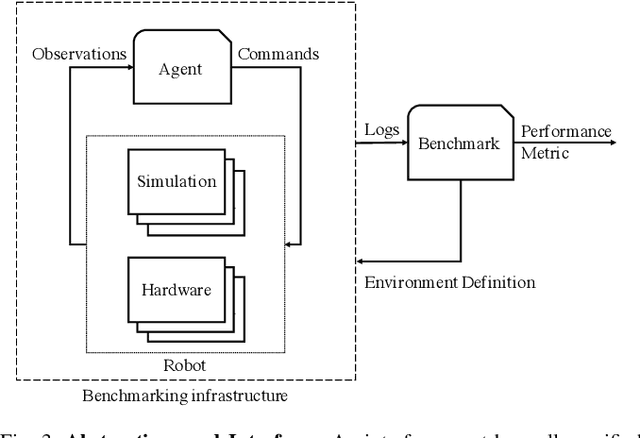
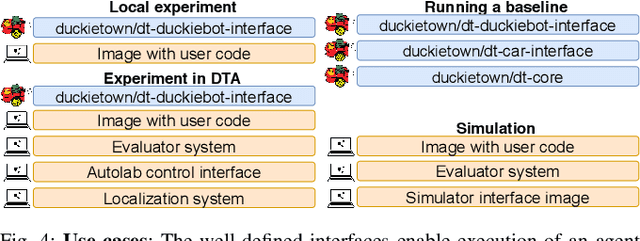
As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible. Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others. In this paper, we describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained "by design" from the beginning of the research/development processes. We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet. One of the central components of this setup is the Duckietown Autolab, a remotely accessible standardized setup that is itself also relatively low-cost and reproducible. When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs.
DIODE: A Dense Indoor and Outdoor DEpth Dataset
Aug 29, 2019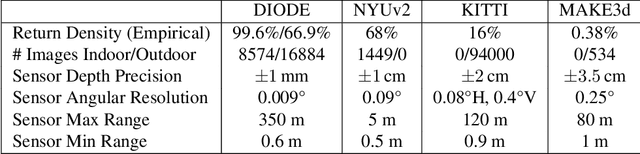
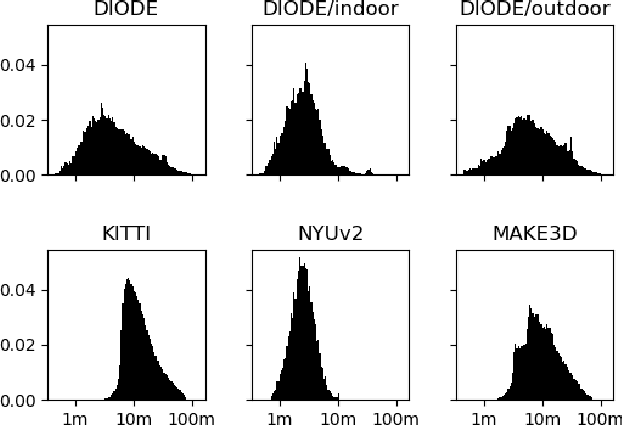
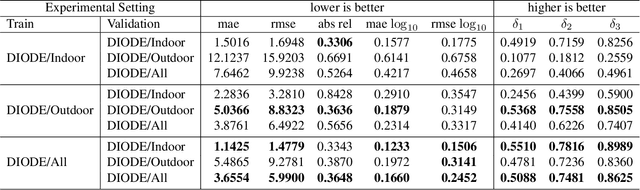
We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult. The dataset is available for download at http://diode-dataset.org
Inferring Compact Representations for Efficient Natural Language Understanding of Robot Instructions
Mar 21, 2019
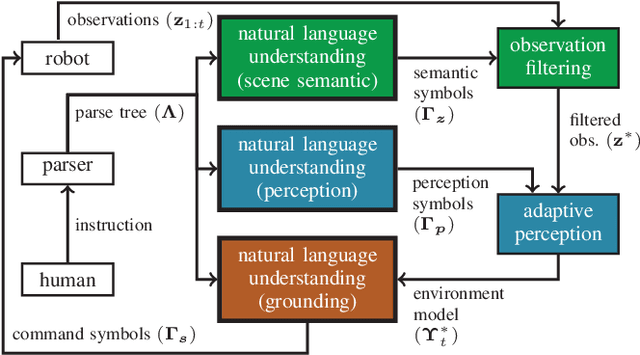


The speed and accuracy with which robots are able to interpret natural language is fundamental to realizing effective human-robot interaction. A great deal of attention has been paid to developing models and approximate inference algorithms that improve the efficiency of language understanding. However, existing methods still attempt to reason over a representation of the environment that is flat and unnecessarily detailed, which limits scalability. An open problem is then to develop methods capable of producing the most compact environment model sufficient for accurate and efficient natural language understanding. We propose a model that leverages environment-related information encoded within instructions to identify the subset of observations and perceptual classifiers necessary to perceive a succinct, instruction-specific environment representation. The framework uses three probabilistic graphical models trained from a corpus of annotated instructions to infer salient scene semantics, perceptual classifiers, and grounded symbols. Experimental results on two robots operating in different environments demonstrate that by exploiting the content and the structure of the instructions, our method learns compact environment representations that significantly improve the efficiency of natural language symbol grounding.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
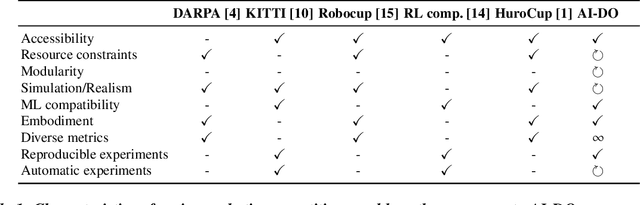
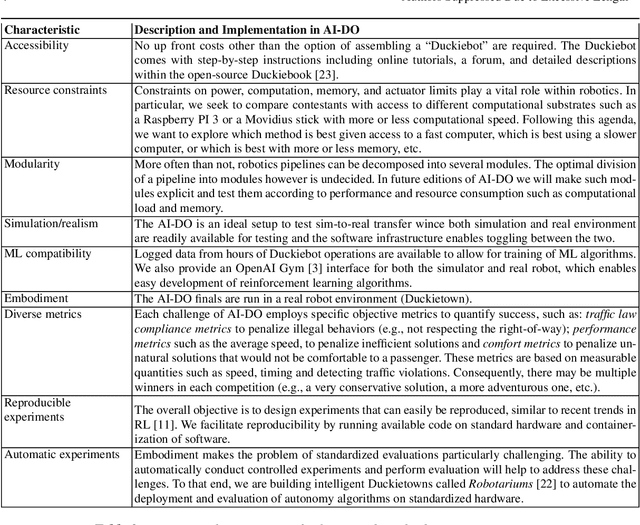

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
Navigational Instruction Generation as Inverse Reinforcement Learning with Neural Machine Translation
Oct 11, 2016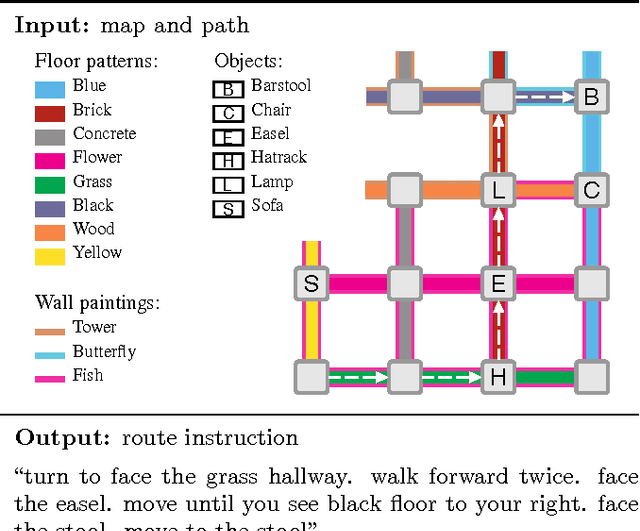



Modern robotics applications that involve human-robot interaction require robots to be able to communicate with humans seamlessly and effectively. Natural language provides a flexible and efficient medium through which robots can exchange information with their human partners. Significant advancements have been made in developing robots capable of interpreting free-form instructions, but less attention has been devoted to endowing robots with the ability to generate natural language. We propose a navigational guide model that enables robots to generate natural language instructions that allow humans to navigate a priori unknown environments. We first decide which information to share with the user according to their preferences, using a policy trained from human demonstrations via inverse reinforcement learning. We then "translate" this information into a natural language instruction using a neural sequence-to-sequence model that learns to generate free-form instructions from natural language corpora. We evaluate our method on a benchmark route instruction dataset and achieve a BLEU score of 72.18% when compared to human-generated reference instructions. We additionally conduct navigation experiments with human participants that demonstrate that our method generates instructions that people follow as accurately and easily as those produced by humans.