 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Assessing the Usefulness of Proxy Domains for Developing and Evaluating Embodied Agents
Oct 07, 2021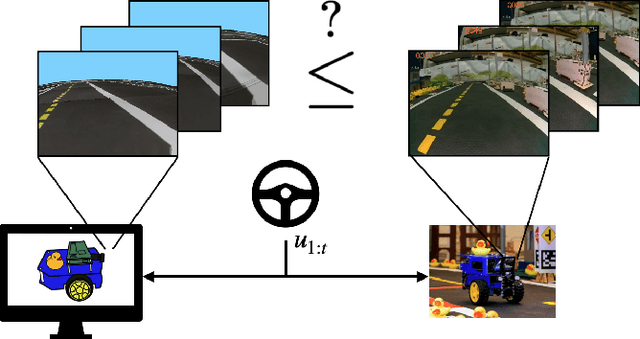
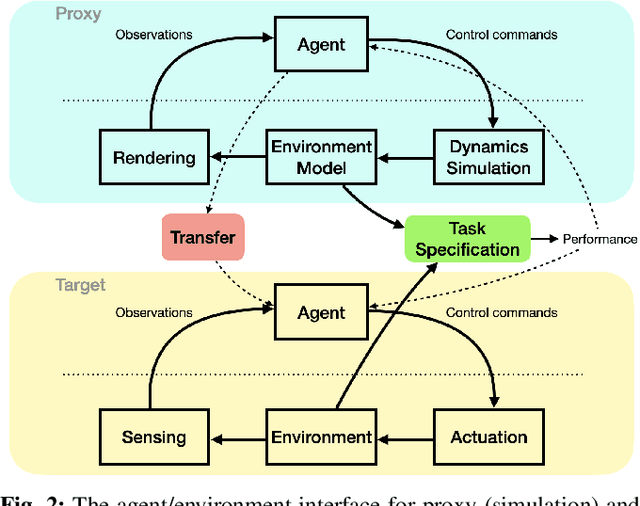

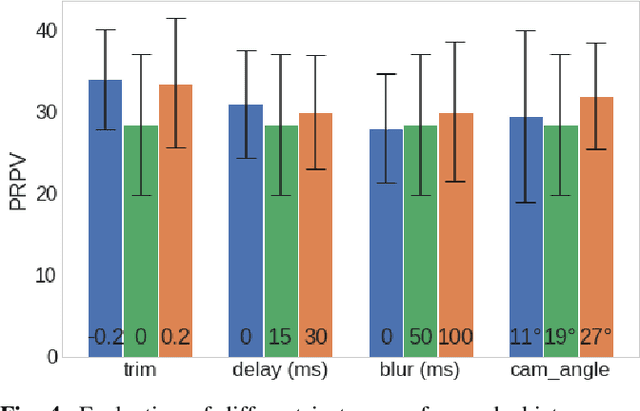
In many situations it is either impossible or impractical to develop and evaluate agents entirely on the target domain on which they will be deployed. This is particularly true in robotics, where doing experiments on hardware is much more arduous than in simulation. This has become arguably more so in the case of learning-based agents. To this end, considerable recent effort has been devoted to developing increasingly realistic and higher fidelity simulators. However, we lack any principled way to evaluate how good a "proxy domain" is, specifically in terms of how useful it is in helping us achieve our end objective of building an agent that performs well in the target domain. In this work, we investigate methods to address this need. We begin by clearly separating two uses of proxy domains that are often conflated: 1) their ability to be a faithful predictor of agent performance and 2) their ability to be a useful tool for learning. In this paper, we attempt to clarify the role of proxy domains and establish new proxy usefulness (PU) metrics to compare the usefulness of different proxy domains. We propose the relative predictive PU to assess the predictive ability of a proxy domain and the learning PU to quantify the usefulness of a proxy as a tool to generate learning data. Furthermore, we argue that the value of a proxy is conditioned on the task that it is being used to help solve. We demonstrate how these new metrics can be used to optimize parameters of the proxy domain for which obtaining ground truth via system identification is not trivial.
Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
Sep 09, 2020
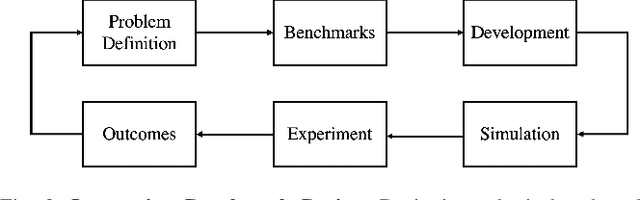
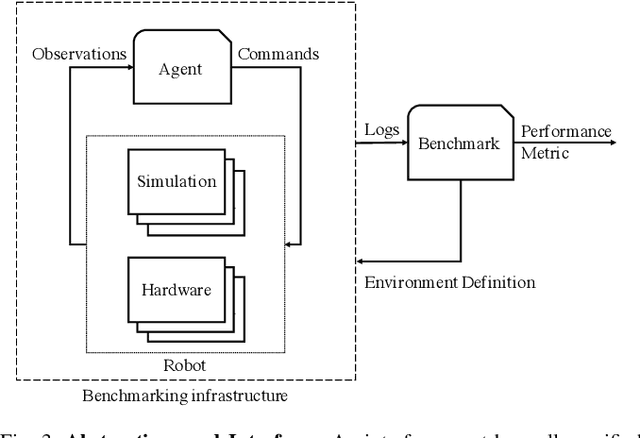
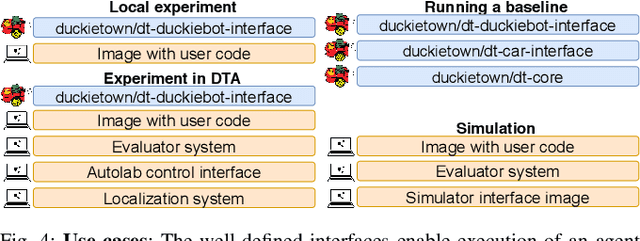
As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible. Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others. In this paper, we describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained "by design" from the beginning of the research/development processes. We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet. One of the central components of this setup is the Duckietown Autolab, a remotely accessible standardized setup that is itself also relatively low-cost and reproducible. When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs.