 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion of Interest focused MRI to Synthetic CT Translation using Regression and Classification Multi-task Network
Mar 30, 2022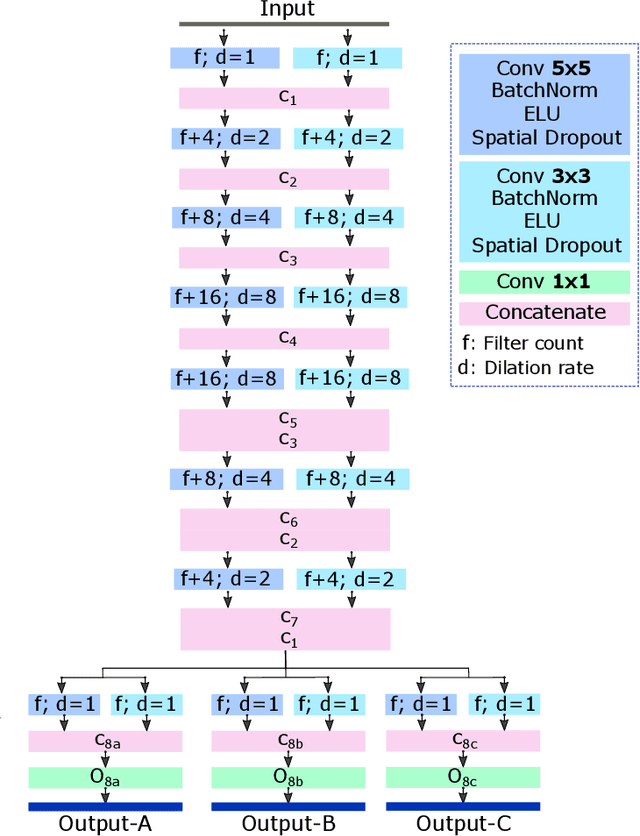
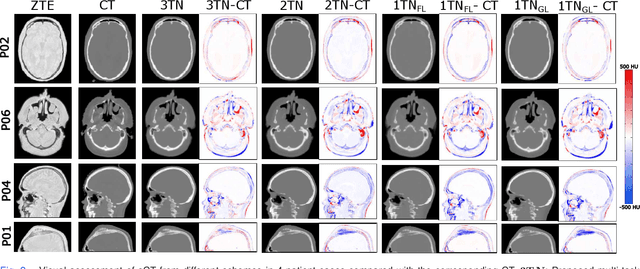
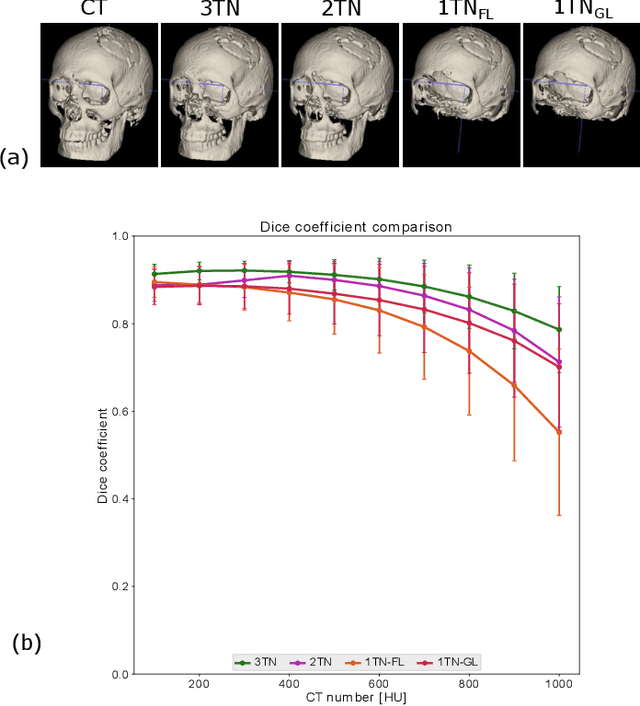
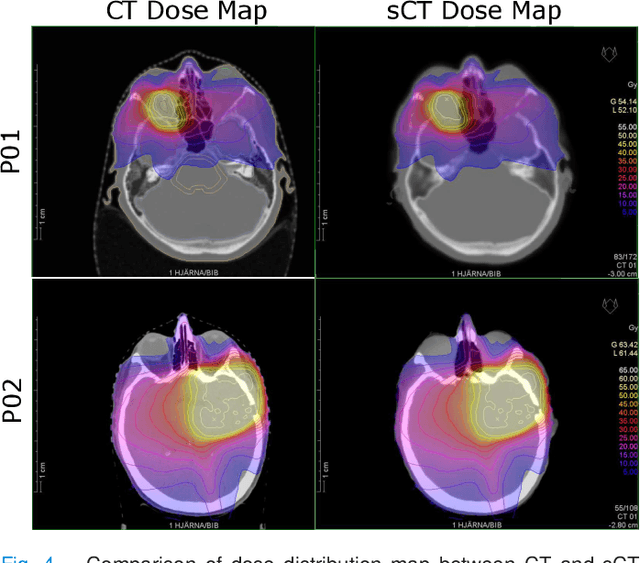
In this work, we present a method for synthetic CT (sCT) generation from zero-echo-time (ZTE) MRI aimed at structural and quantitative accuracies of the image, with a particular focus on the accurate bone density value prediction. We propose a loss function that favors a spatially sparse region in the image. We harness the ability of a multi-task network to produce correlated outputs as a framework to enable localisation of region of interest (RoI) via classification, emphasize regression of values within RoI and still retain the overall accuracy via global regression. The network is optimized by a composite loss function that combines a dedicated loss from each task. We demonstrate how the multi-task network with RoI focused loss offers an advantage over other configurations of the network to achieve higher accuracy of performance. This is relevant to sCT where failure to accurately estimate high Hounsfield Unit values of bone could lead to impaired accuracy in clinical applications. We compare the dose calculation maps from the proposed sCT and the real CT in a radiation therapy treatment planning setup.
A User's Guide to Calibrating Robotics Simulators
Nov 17, 2020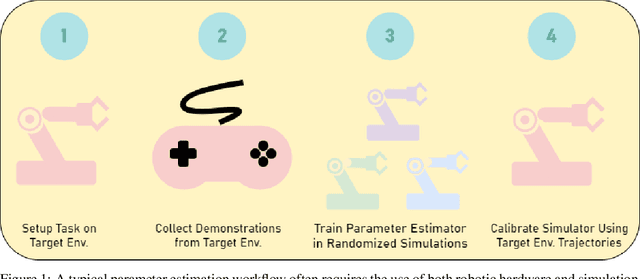



Simulators are a critical component of modern robotics research. Strategies for both perception and decision making can be studied in simulation first before deployed to real world systems, saving on time and costs. Despite significant progress on the development of sim-to-real algorithms, the analysis of different methods is still conducted in an ad-hoc manner, without a consistent set of tests and metrics for comparison. This paper fills this gap and proposes a set of benchmarks and a framework for the study of various algorithms aimed to transfer models and policies learnt in simulation to the real world. We conduct experiments on a wide range of well known simulated environments to characterize and offer insights into the performance of different algorithms. Our analysis can be useful for practitioners working in this area and can help make informed choices about the behavior and main properties of sim-to-real algorithms. We open-source the benchmark, training data, and trained models, which can be found at https://github.com/NVlabs/sim-parameter-estimation.
Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
Sep 09, 2020
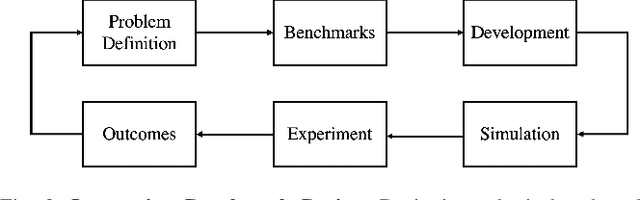
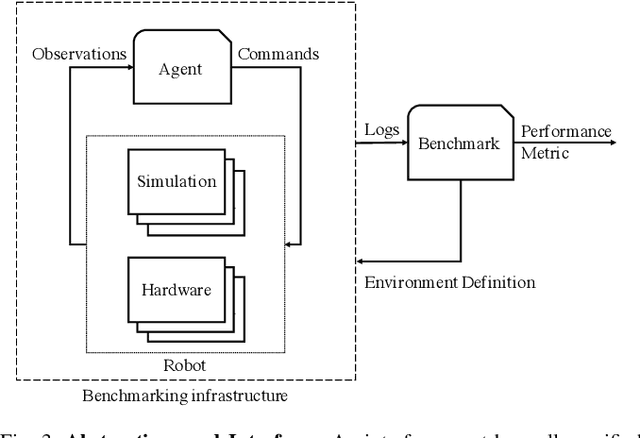
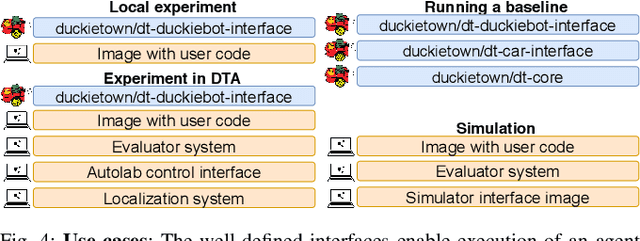
As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible. Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others. In this paper, we describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained "by design" from the beginning of the research/development processes. We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet. One of the central components of this setup is the Duckietown Autolab, a remotely accessible standardized setup that is itself also relatively low-cost and reproducible. When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs.
Curriculum in Gradient-Based Meta-Reinforcement Learning
Feb 19, 2020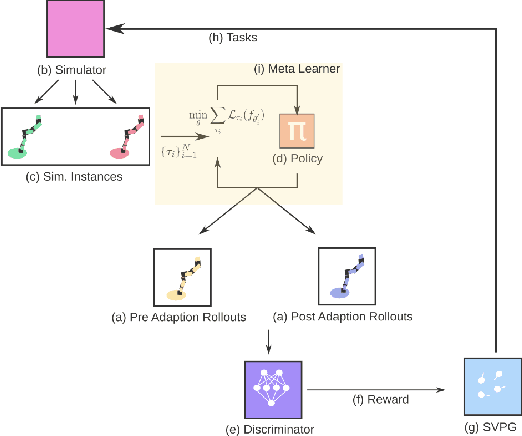


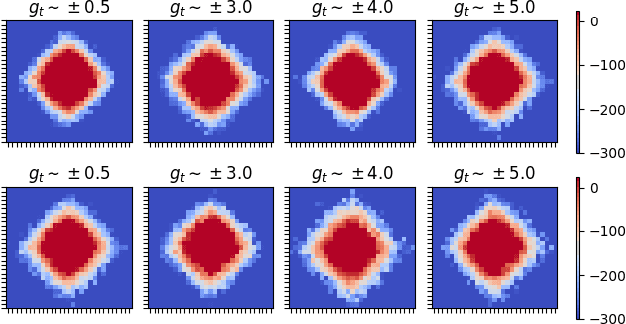
Gradient-based meta-learners such as Model-Agnostic Meta-Learning (MAML) have shown strong few-shot performance in supervised and reinforcement learning settings. However, specifically in the case of meta-reinforcement learning (meta-RL), we can show that gradient-based meta-learners are sensitive to task distributions. With the wrong curriculum, agents suffer the effects of meta-overfitting, shallow adaptation, and adaptation instability. In this work, we begin by highlighting intriguing failure cases of gradient-based meta-RL and show that task distributions can wildly affect algorithmic outputs, stability, and performance. To address this problem, we leverage insights from recent literature on domain randomization and propose meta Active Domain Randomization (meta-ADR), which learns a curriculum of tasks for gradient-based meta-RL in a similar as ADR does for sim2real transfer. We show that this approach induces more stable policies on a variety of simulated locomotion and navigation tasks. We assess in- and out-of-distribution generalization and find that the learned task distributions, even in an unstructured task space, greatly improve the adaptation performance of MAML. Finally, we motivate the need for better benchmarking in meta-RL that prioritizes \textit{generalization} over single-task adaption performance.
Generating Automatic Curricula via Self-Supervised Active Domain Randomization
Feb 18, 2020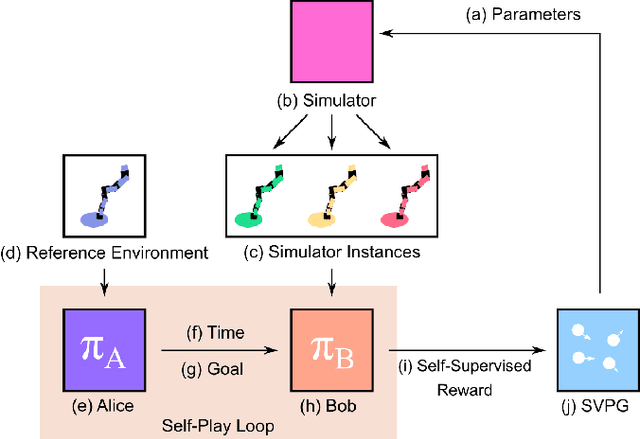

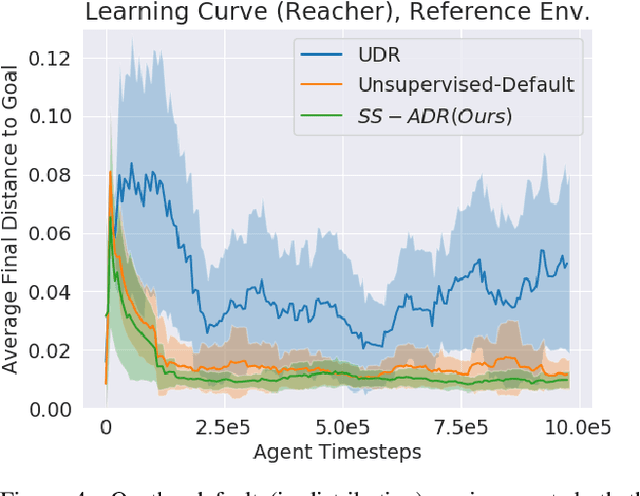
Goal-directed Reinforcement Learning (RL) traditionally considers an agent interacting with an environment, prescribing a real-valued reward to an agent proportional to the completion of some goal. Goal-directed RL has seen large gains in sample efficiency, due to the ease of reusing or generating new experience by proposing goals. In this work, we build on the framework of self-play, allowing an agent to interact with itself in order to make progress on some unknown task. We use Active Domain Randomization and self-play to create a novel, coupled environment-goal curriculum, where agents learn through progressively more difficult tasks and environment variations. Our method, Self-Supervised Active Domain Randomization (SS-ADR), generates a growing curriculum, encouraging the agent to try tasks that are just outside of its current capabilities, while building a domain-randomization curriculum that enables state-of-the-art results on various sim2real transfer tasks. Our results show that a curriculum of co-evolving the environment difficulty along with the difficulty of goals set in each environment provides practical benefits in the goal-directed tasks tested.
Active Domain Randomization
Apr 09, 2019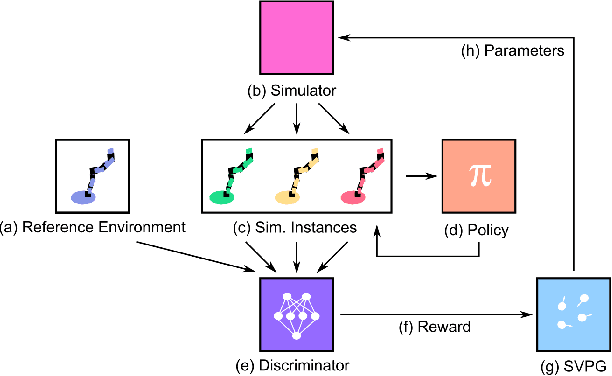

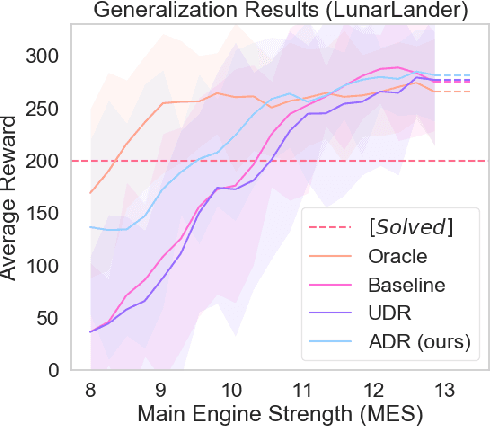
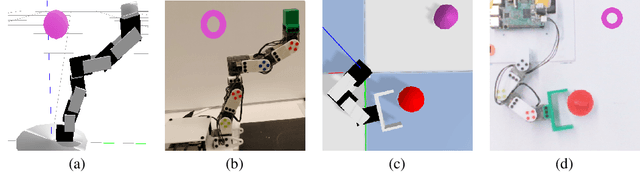
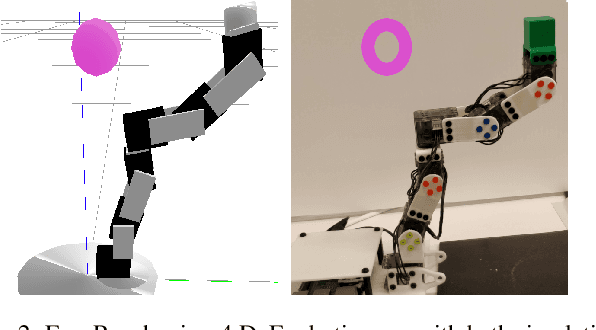
Domain randomization is a popular technique for improving domain transfer, often used in a zero-shot setting when the target domain is unknown or cannot easily be used for training. In this work, we empirically examine the effects of domain randomization on agent generalization. Our experiments show that domain randomization may lead to suboptimal, high-variance policies, which we attribute to the uniform sampling of environment parameters. We propose Active Domain Randomization, a novel algorithm that learns a parameter sampling strategy. Our method looks for the most informative environment variations within the given randomization ranges by leveraging the discrepancies of policy rollouts in randomized and reference environment instances. We find that training more frequently on these instances leads to better overall agent generalization. In addition, when domain randomization and policy transfer fail, Active Domain Randomization offers more insight into the deficiencies of both the chosen parameter ranges and the learned policy, allowing for more focused debugging. Our experiments across various physics-based simulated and a real-robot task show that this enhancement leads to more robust, consistent policies.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
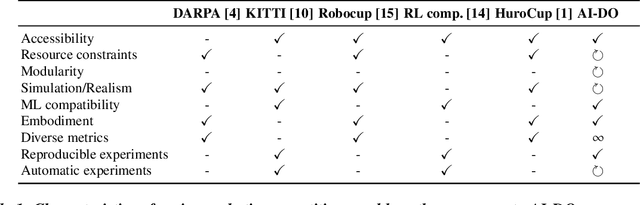
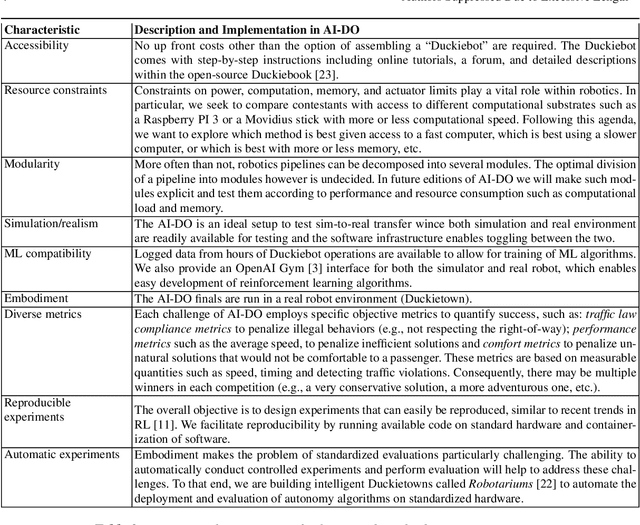

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
A Scalable, Flexible Augmentation of the Student Education Process
Oct 17, 2018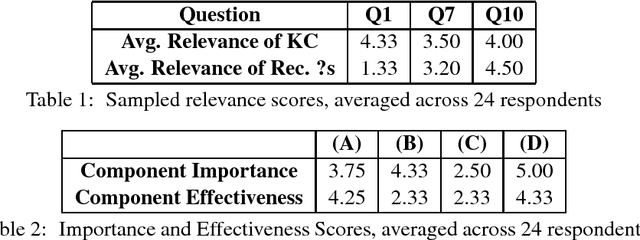
We present a novel intelligent tutoring system which builds upon well-established hypotheses in educational psychology and incorporates them inside of a scalable software architecture. Specifically, we build upon the known benefits of knowledge vocalization, parallel learning, and immediate feedback in the context of student learning. We show that open-source data combined with state-of-the-art techniques in deep learning and natural language processing can apply the benefits of these three factors at scale, while still operating at the granularity of individual student needs and recommendations. Additionally, we allow teachers to retain full control of the outputs of the algorithms, and provide student statistics to help better guide classroom discussions towards topics that would benefit from more in-person review and coverage. Our experiments and pilot programs show promising results, and cement our hypothesis that the system is flexible enough to serve a wide variety of purposes in both classroom and classroom-free settings.