 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the effect of representations on task complexity
Dec 19, 2019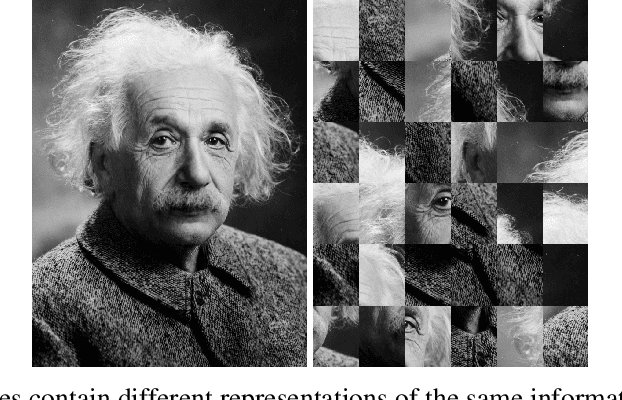
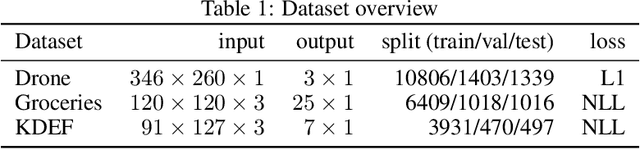
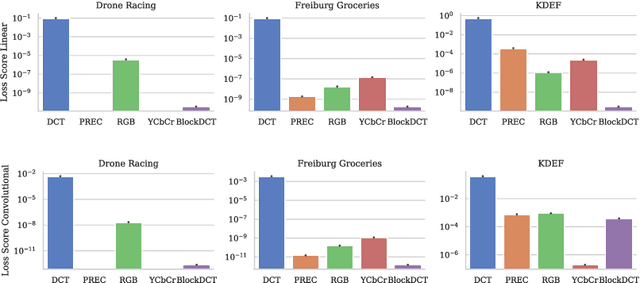

We examine the influence of input data representations on learning complexity. For learning, we posit that each model implicitly uses a candidate model distribution for unexplained variations in the data, its noise model. If the model distribution is not well aligned to the true distribution, then even relevant variations will be treated as noise. Crucially however, the alignment of model and true distribution can be changed, albeit implicitly, by changing data representations. "Better" representations can better align the model to the true distribution, making it easier to approximate the input-output relationship in the data without discarding useful data variations. To quantify this alignment effect of data representations on the difficulty of a learning task, we make use of an existing task complexity score and show its connection to the representation-dependent information coding length of the input. Empirically we extract the necessary statistics from a linear regression approximation and show that these are sufficient to predict relative learning performance outcomes of different data representations and neural network types obtained when utilizing an extensive neural network architecture search. We conclude that to ensure better learning outcomes, representations may need to be tailored to both task and model to align with the implicit distribution of model and task.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
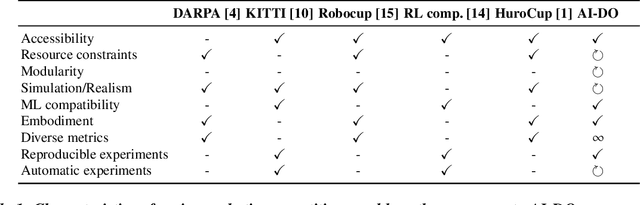

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
Inspiring Computer Vision System Solutions
Jul 22, 2017

The "digital Michelangelo project" was a seminal computer vision project in the early 2000's that pushed the capabilities of acquisition systems and involved multiple people from diverse fields, many of whom are now leaders in industry and academia. Reviewing this project with modern eyes provides us with the opportunity to reflect on several issues, relevant now as then to the field of computer vision and research in general, that go beyond the technical aspects of the work. This article was written in the context of a reading group competition at the week-long International Computer Vision Summer School 2017 (ICVSS) on Sicily, Italy. To deepen the participants understanding of computer vision and to foster a sense of community, various reading groups were tasked to highlight important lessons which may be learned from provided literature, going beyond the contents of the paper. This report is the winning entry of this guided discourse (Fig. 1). The authors closely examined the origins, fruits and most importantly lessons about research in general which may be distilled from the "digital Michelangelo project". Discussions leading to this report were held within the group as well as with Hao Li, the group mentor.