 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt
May 08, 2025Artificial Intelligence (AI) systems are increasingly placed in positions where their decisions have real consequences, e.g., moderating online spaces, conducting research, and advising on policy. Ensuring they operate in a safe and ethically acceptable fashion is thus critical. However, most solutions have been a form of one-size-fits-all "alignment". We are worried that such systems, which overlook enduring moral diversity, will spark resistance, erode trust, and destabilize our institutions. This paper traces the underlying problem to an often-unstated Axiom of Rational Convergence: the idea that under ideal conditions, rational agents will converge in the limit of conversation on a single ethics. Treating that premise as both optional and doubtful, we propose what we call the appropriateness framework: an alternative approach grounded in conflict theory, cultural evolution, multi-agent systems, and institutional economics. The appropriateness framework treats persistent disagreement as the normal case and designs for it by applying four principles: (1) contextual grounding, (2) community customization, (3) continual adaptation, and (4) polycentric governance. We argue here that adopting these design principles is a good way to shift the main alignment metaphor from moral unification to a more productive metaphor of conflict management, and that taking this step is both desirable and urgent.
A theory of appropriateness with applications to generative artificial intelligence
Dec 26, 2024

What is appropriateness? Humans navigate a multi-scale mosaic of interlocking notions of what is appropriate for different situations. We act one way with our friends, another with our family, and yet another in the office. Likewise for AI, appropriate behavior for a comedy-writing assistant is not the same as appropriate behavior for a customer-service representative. What determines which actions are appropriate in which contexts? And what causes these standards to change over time? Since all judgments of AI appropriateness are ultimately made by humans, we need to understand how appropriateness guides human decision making in order to properly evaluate AI decision making and improve it. This paper presents a theory of appropriateness: how it functions in human society, how it may be implemented in the brain, and what it means for responsible deployment of generative AI technology.
Soft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024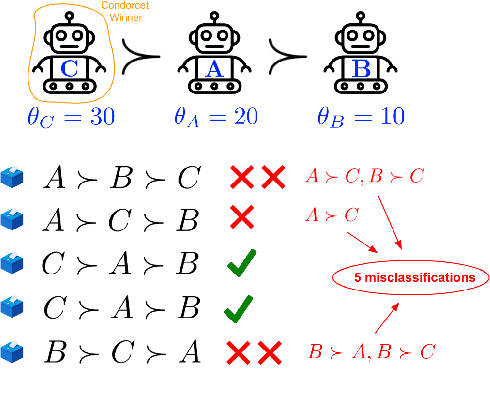
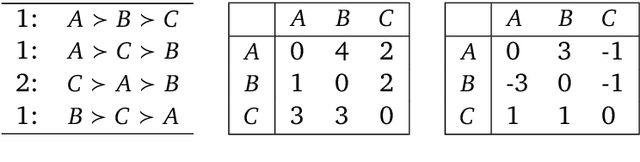
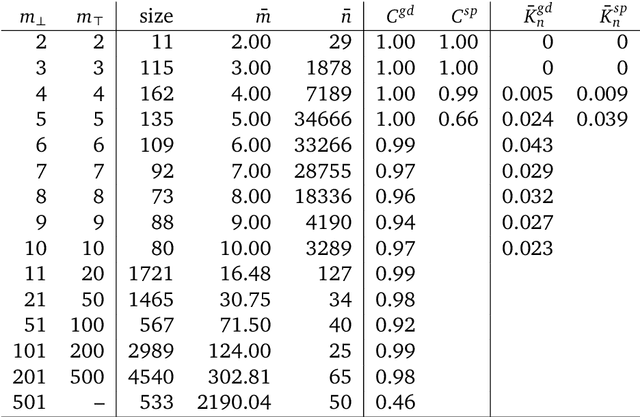
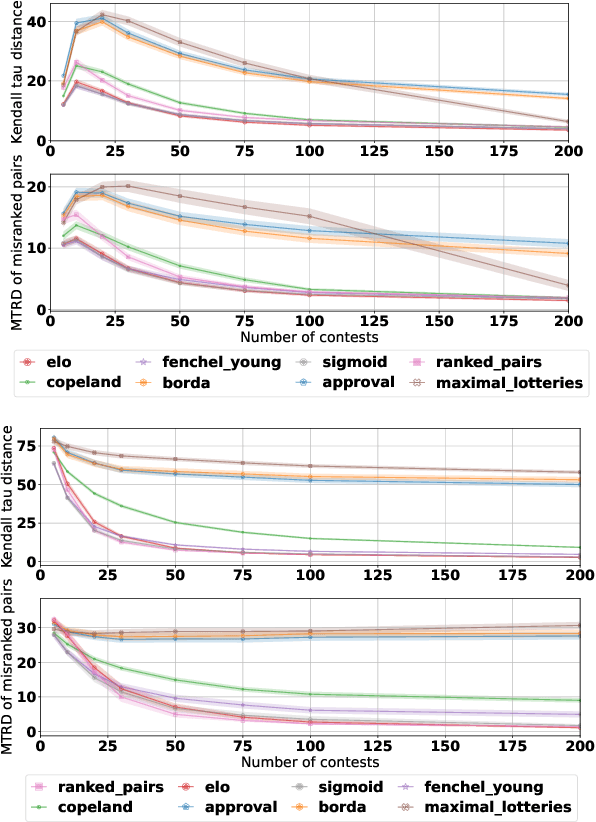
A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
Rethinking Teacher-Student Curriculum Learning through the Cooperative Mechanics of Experience
Apr 03, 2024Teacher-Student Curriculum Learning (TSCL) is a curriculum learning framework that draws inspiration from human cultural transmission and learning. It involves a teacher algorithm shaping the learning process of a learner algorithm by exposing it to controlled experiences. Despite its success, understanding the conditions under which TSCL is effective remains challenging. In this paper, we propose a data-centric perspective to analyze the underlying mechanics of the teacher-student interactions in TSCL. We leverage cooperative game theory to describe how the composition of the set of experiences presented by the teacher to the learner, as well as their order, influences the performance of the curriculum that is found by TSCL approaches. To do so, we demonstrate that for every TSCL problem, there exists an equivalent cooperative game, and several key components of the TSCL framework can be reinterpreted using game-theoretic principles. Through experiments covering supervised learning, reinforcement learning, and classical games, we estimate the cooperative values of experiences and use value-proportional curriculum mechanisms to construct curricula, even in cases where TSCL struggles. The framework and experimental setup we present in this work represent a novel foundation for a deeper exploration of TSCL, shedding light on its underlying mechanisms and providing insights into its broader applicability in machine learning.
Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineering beyond Reward Maximization
Oct 10, 2021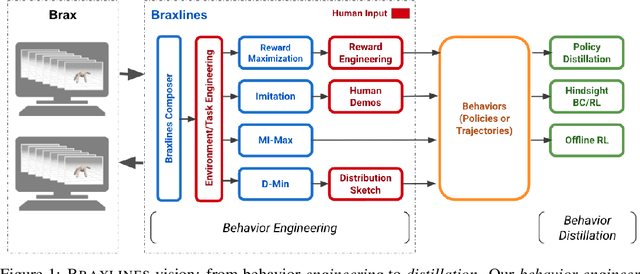



The goal of continuous control is to synthesize desired behaviors. In reinforcement learning (RL)-driven approaches, this is often accomplished through careful task reward engineering for efficient exploration and running an off-the-shelf RL algorithm. While reward maximization is at the core of RL, reward engineering is not the only -- sometimes nor the easiest -- way for specifying complex behaviors. In this paper, we introduce \braxlines, a toolkit for fast and interactive RL-driven behavior generation beyond simple reward maximization that includes Composer, a programmatic API for generating continuous control environments, and set of stable and well-tested baselines for two families of algorithms -- mutual information maximization (MiMax) and divergence minimization (DMin) -- supporting unsupervised skill learning and distribution sketching as other modes of behavior specification. In addition, we discuss how to standardize metrics for evaluating these algorithms, which can no longer rely on simple reward maximization. Our implementations build on a hardware-accelerated Brax simulator in Jax with minimal modifications, enabling behavior synthesis within minutes of training. We hope Braxlines can serve as an interactive toolkit for rapid creation and testing of environments and behaviors, empowering explosions of future benchmark designs and new modes of RL-driven behavior generation and their algorithmic research.
Active Domain Randomization
Apr 09, 2019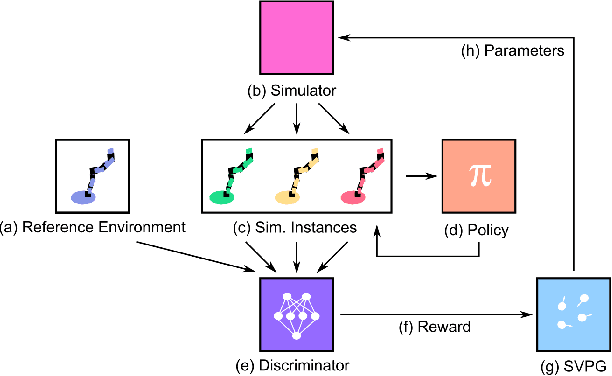

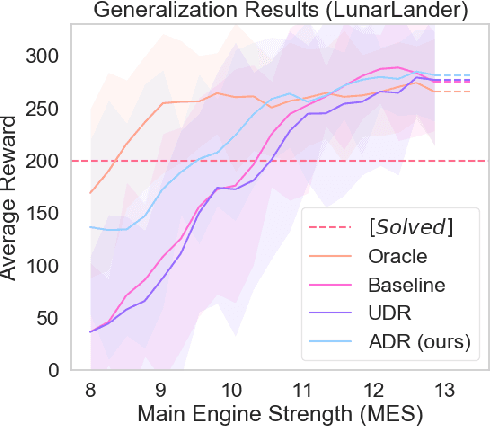
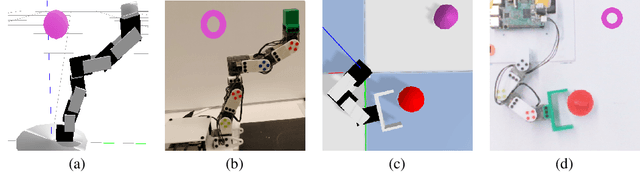
Domain randomization is a popular technique for improving domain transfer, often used in a zero-shot setting when the target domain is unknown or cannot easily be used for training. In this work, we empirically examine the effects of domain randomization on agent generalization. Our experiments show that domain randomization may lead to suboptimal, high-variance policies, which we attribute to the uniform sampling of environment parameters. We propose Active Domain Randomization, a novel algorithm that learns a parameter sampling strategy. Our method looks for the most informative environment variations within the given randomization ranges by leveraging the discrepancies of policy rollouts in randomized and reference environment instances. We find that training more frequently on these instances leads to better overall agent generalization. In addition, when domain randomization and policy transfer fail, Active Domain Randomization offers more insight into the deficiencies of both the chosen parameter ranges and the learned policy, allowing for more focused debugging. Our experiments across various physics-based simulated and a real-robot task show that this enhancement leads to more robust, consistent policies.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
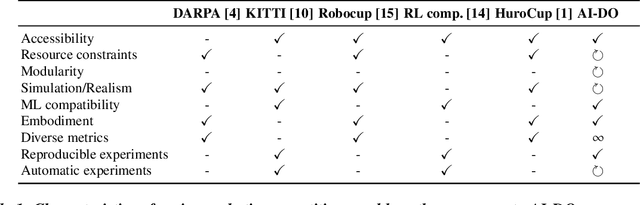
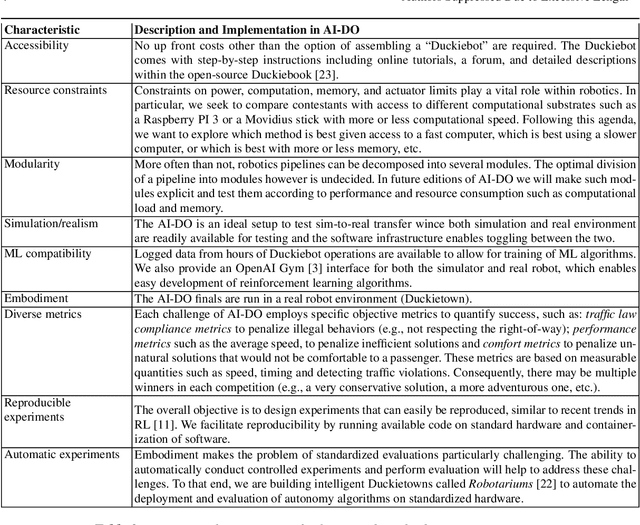

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.