 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Properties of Score-matching Diffusion Models for Intrinsically Low-dimensional Data
Mar 04, 2026Despite the remarkable empirical success of score-based diffusion models, their statistical guarantees remain underdeveloped. Existing analyses often provide pessimistic convergence rates that do not reflect the intrinsic low-dimensional structure common in real data, such as that arising in natural images. In this work, we study the statistical convergence of score-based diffusion models for learning an unknown distribution $μ$ from finitely many samples. Under mild regularity conditions on the forward diffusion process and the data distribution, we derive finite-sample error bounds on the learned generative distribution, measured in the Wasserstein-$p$ distance. Unlike prior results, our guarantees hold for all $p \ge 1$ and require only a finite-moment assumption on $μ$, without compact-support, manifold, or smooth-density conditions. Specifically, given $n$ i.i.d.\ samples from $μ$ with finite $q$-th moment and appropriately chosen network architectures, hyperparameters, and discretization schemes, we show that the expected Wasserstein-$p$ error between the learned distribution $\hatμ$ and $μ$ scales as $\mathbb{E}\, \mathbb{W}_p(\hatμ,μ) = \widetilde{O}\!\left(n^{-1 / d^\ast_{p,q}(μ)}\right),$ where $d^\ast_{p,q}(μ)$ is the $(p,q)$-Wasserstein dimension of $μ$. Our results demonstrate that diffusion models naturally adapt to the intrinsic geometry of data and mitigate the curse of dimensionality, since the convergence rate depends on $d^\ast_{p,q}(μ)$ rather than the ambient dimension. Moreover, our theory conceptually bridges the analysis of diffusion models with that of GANs and the sharp minimax rates established in optimal transport. The proposed $(p,q)$-Wasserstein dimension also extends classical Wasserstein dimension notions to distributions with unbounded support, which may be of independent theoretical interest.
Control Variate Score Matching for Diffusion Models
Dec 23, 2025Diffusion models offer a robust framework for sampling from unnormalized probability densities, which requires accurately estimating the score of the noise-perturbed target distribution. While the standard Denoising Score Identity (DSI) relies on data samples, access to the target energy function enables an alternative formulation via the Target Score Identity (TSI). However, these estimators face a fundamental variance trade-off: DSI exhibits high variance in low-noise regimes, whereas TSI suffers from high variance at high noise levels. In this work, we reconcile these approaches by unifying both estimators within the principled framework of control variates. We introduce the Control Variate Score Identity (CVSI), deriving an optimal, time-dependent control coefficient that theoretically guarantees variance minimization across the entire noise spectrum. We demonstrate that CVSI serves as a robust, low-variance plug-in estimator that significantly enhances sample efficiency in both data-free sampler learning and inference-time diffusion sampling.
Building Bridges between Regression, Clustering, and Classification
Feb 05, 2025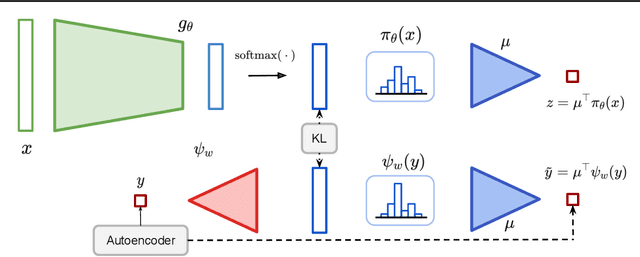
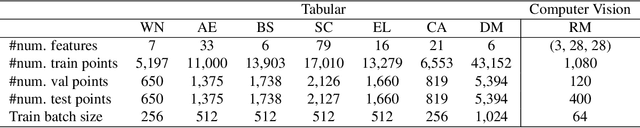
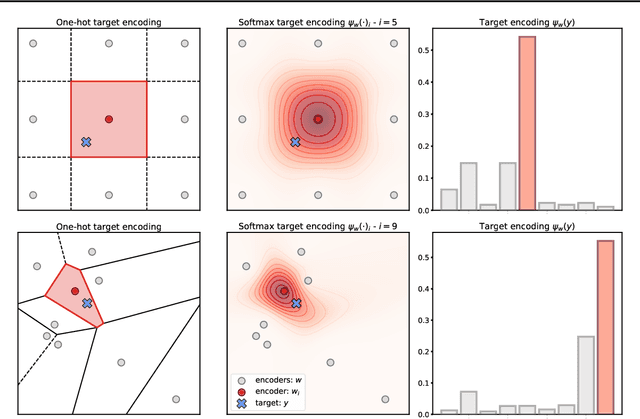
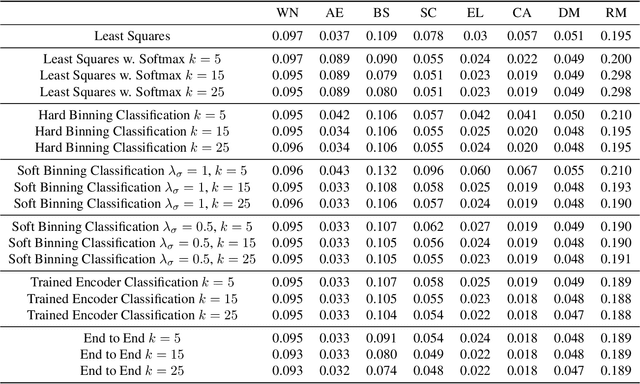
Regression, the task of predicting a continuous scalar target y based on some features x is one of the most fundamental tasks in machine learning and statistics. It has been observed and theoretically analyzed that the classical approach, meansquared error minimization, can lead to suboptimal results when training neural networks. In this work, we propose a new method to improve the training of these models on regression tasks, with continuous scalar targets. Our method is based on casting this task in a different fashion, using a target encoder, and a prediction decoder, inspired by approaches in classification and clustering. We showcase the performance of our method on a wide range of real-world datasets.
Soft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024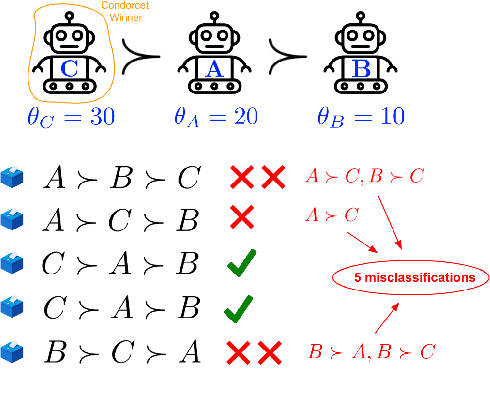
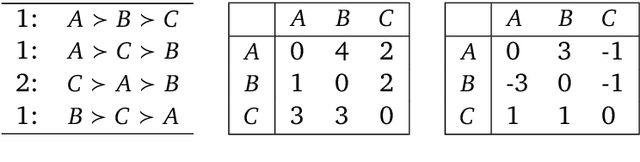
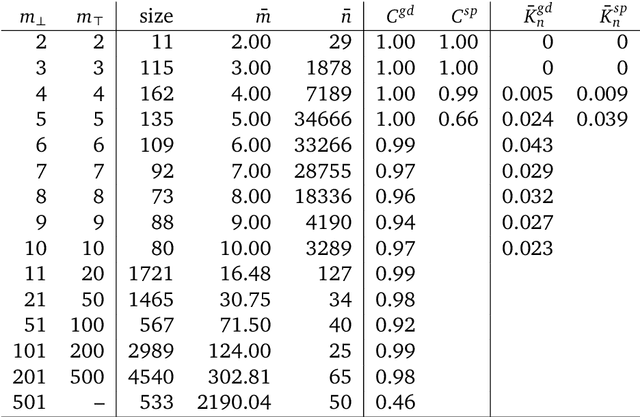
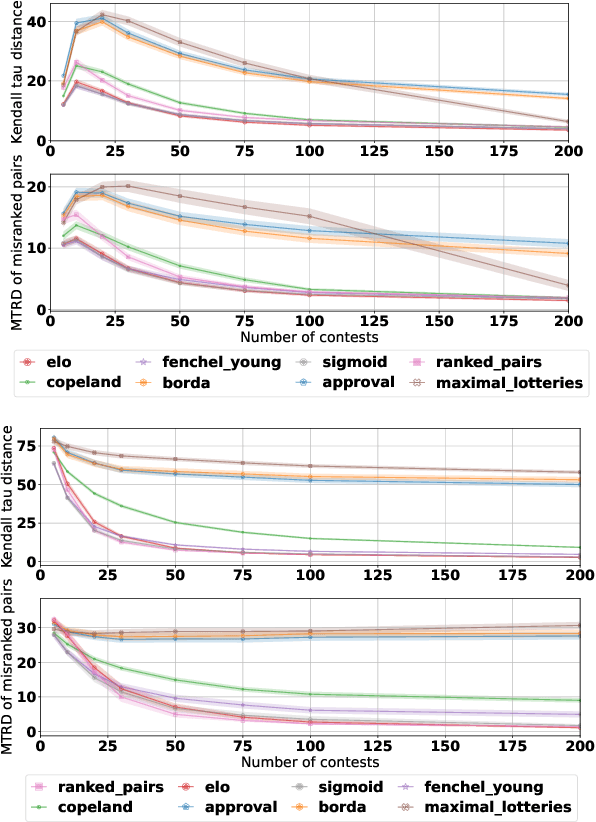
A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
Implicit Diffusion: Efficient Optimization through Stochastic Sampling
Feb 08, 2024



We present a new algorithm to optimize distributions defined implicitly by parameterized stochastic diffusions. Doing so allows us to modify the outcome distribution of sampling processes by optimizing over their parameters. We introduce a general framework for first-order optimization of these processes, that performs jointly, in a single loop, optimization and sampling steps. This approach is inspired by recent advances in bilevel optimization and automatic implicit differentiation, leveraging the point of view of sampling as optimization over the space of probability distributions. We provide theoretical guarantees on the performance of our method, as well as experimental results demonstrating its effectiveness in real-world settings.
Decoding-time Realignment of Language Models
Feb 05, 2024Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. This process, however, is resource-intensive, especially for large models. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models. It also enhances the efficiency of hyperparameter tuning by enabling the identification of effective regularization strengths using a validation dataset.
Differentiable Clustering with Perturbed Spanning Forests
May 25, 2023We introduce a differentiable clustering method based on minimum-weight spanning forests, a variant of spanning trees with several connected components. Our method relies on stochastic perturbations of solutions of linear programs, for smoothing and efficient gradient computations. This allows us to include clustering in end-to-end trainable pipelines. We show that our method performs well even in difficult settings, such as datasets with high noise and challenging geometries. We also formulate an ad hoc loss to efficiently learn from partial clustering data using this operation. We demonstrate its performance on several real world datasets for supervised and semi-supervised tasks.
Mirror Sinkhorn: Fast Online Optimization on Transport Polytopes
Nov 18, 2022Optimal transport has arisen as an important tool in machine learning, allowing to capture geometric properties of the data. It is formulated as a linear program on transport polytopes. The problem of convex optimization on this set includes both OT and multiple related ones, such as point cloud registration. We present in this work an optimization algorithm that utilizes Sinkhorn matrix scaling and mirror descent to minimize convex objectives on this domain. This algorithm can be run online and is both adaptive and robust to noise. A mathematical analysis of the convergence rate of the algorithm for minimising convex functions is provided, as well as experiments that illustrate its performance on synthetic data and real-world data.
Regression as Classification: Influence of Task Formulation on Neural Network Features
Nov 10, 2022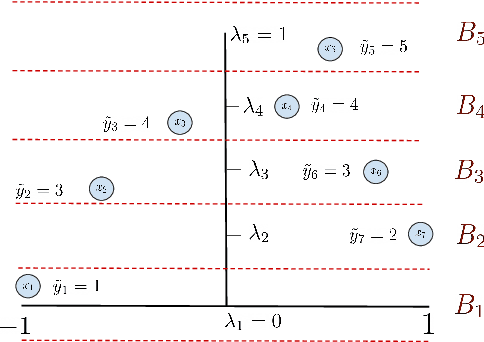
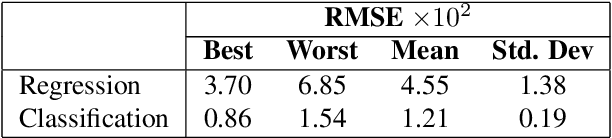
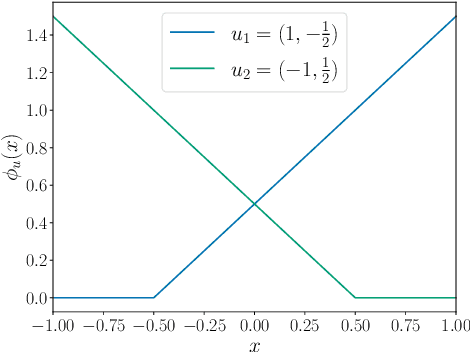
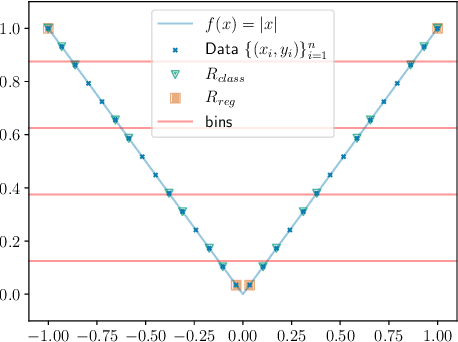
Neural networks can be trained to solve regression problems by using gradient-based methods to minimize the square loss. However, practitioners often prefer to reformulate regression as a classification problem, observing that training on the cross entropy loss results in better performance. By focusing on two-layer ReLU networks, which can be fully characterized by measures over their feature space, we explore how the implicit bias induced by gradient-based optimization could partly explain the above phenomenon. We provide theoretical evidence that the regression formulation yields a measure whose support can differ greatly from that for classification, in the case of one-dimensional data. Our proposed optimal supports correspond directly to the features learned by the input layer of the network. The different nature of these supports sheds light on possible optimization difficulties the square loss could encounter during training, and we present empirical results illustrating this phenomenon.
Fast Stochastic Composite Minimization and an Accelerated Frank-Wolfe Algorithm under Parallelization
May 25, 2022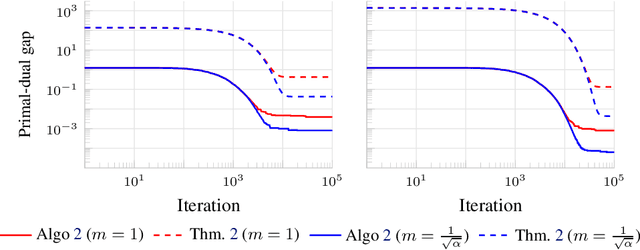
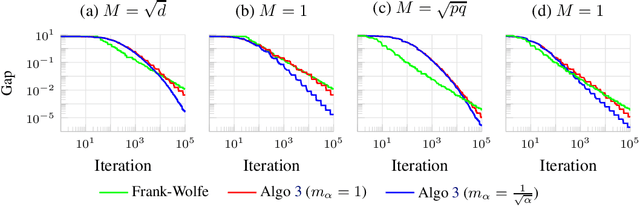
We consider the problem of minimizing the sum of two convex functions. One of those functions has Lipschitz-continuous gradients, and can be accessed via stochastic oracles, whereas the other is "simple". We provide a Bregman-type algorithm with accelerated convergence in function values to a ball containing the minimum. The radius of this ball depends on problem-dependent constants, including the variance of the stochastic oracle. We further show that this algorithmic setup naturally leads to a variant of Frank-Wolfe achieving acceleration under parallelization. More precisely, when minimizing a smooth convex function on a bounded domain, we show that one can achieve an $\epsilon$ primal-dual gap (in expectation) in $\tilde{O}(1/ \sqrt{\epsilon})$ iterations, by only accessing gradients of the original function and a linear maximization oracle with $O(1/\sqrt{\epsilon})$ computing units in parallel. We illustrate this fast convergence on synthetic numerical experiments.