 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Clustering with Perturbed Spanning Forests
May 25, 2023We introduce a differentiable clustering method based on minimum-weight spanning forests, a variant of spanning trees with several connected components. Our method relies on stochastic perturbations of solutions of linear programs, for smoothing and efficient gradient computations. This allows us to include clustering in end-to-end trainable pipelines. We show that our method performs well even in difficult settings, such as datasets with high noise and challenging geometries. We also formulate an ad hoc loss to efficiently learn from partial clustering data using this operation. We demonstrate its performance on several real world datasets for supervised and semi-supervised tasks.
Fast and Memory-Efficient Significant Pattern Mining via Permutation Testing
Feb 15, 2015



We present a novel algorithm, Westfall-Young light, for detecting patterns, such as itemsets and subgraphs, which are statistically significantly enriched in one of two classes. Our method corrects rigorously for multiple hypothesis testing and correlations between patterns through the Westfall-Young permutation procedure, which empirically estimates the null distribution of pattern frequencies in each class via permutations. In our experiments, Westfall-Young light dramatically outperforms the current state-of-the-art approach in terms of both runtime and memory efficiency on popular real-world benchmark datasets for pattern mining. The key to this efficiency is that unlike all existing methods, our algorithm neither needs to solve the underlying frequent itemset mining problem anew for each permutation nor needs to store the occurrence list of all frequent patterns. Westfall-Young light opens the door to significant pattern mining on large datasets that previously led to prohibitive runtime or memory costs.
Significant Subgraph Mining with Multiple Testing Correction
Jan 30, 2015
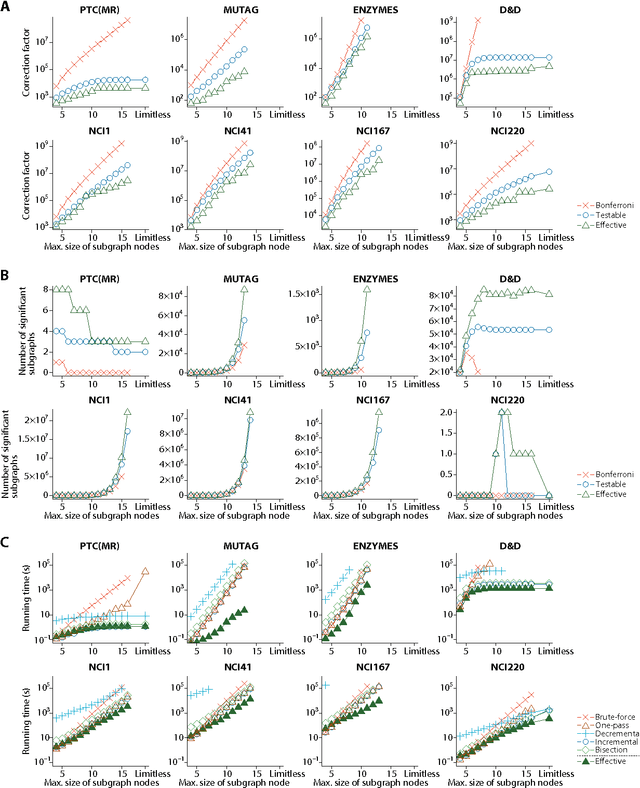
The problem of finding itemsets that are statistically significantly enriched in a class of transactions is complicated by the need to correct for multiple hypothesis testing. Pruning untestable hypotheses was recently proposed as a strategy for this task of significant itemset mining. It was shown to lead to greater statistical power, the discovery of more truly significant itemsets, than the standard Bonferroni correction on real-world datasets. An open question, however, is whether this strategy of excluding untestable hypotheses also leads to greater statistical power in subgraph mining, in which the number of hypotheses is much larger than in itemset mining. Here we answer this question by an empirical investigation on eight popular graph benchmark datasets. We propose a new efficient search strategy, which always returns the same solution as the state-of-the-art approach and is approximately two orders of magnitude faster. Moreover, we exploit the dependence between subgraphs by considering the effective number of tests and thereby further increase the statistical power.