 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Concept Hierarchies from Text Corpora via Hyperbolic Embeddings
Feb 03, 2019

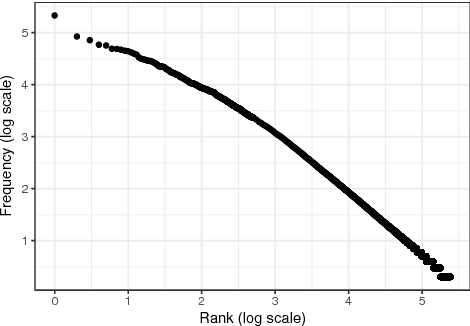
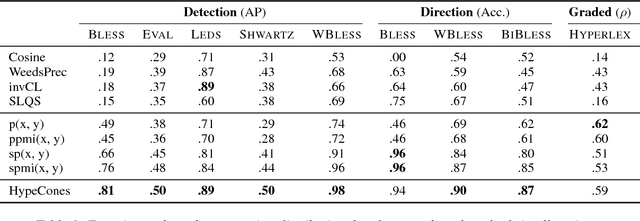
We consider the task of inferring is-a relationships from large text corpora. For this purpose, we propose a new method combining hyperbolic embeddings and Hearst patterns. This approach allows us to set appropriate constraints for inferring concept hierarchies from distributional contexts while also being able to predict missing is-a relationships and to correct wrong extractions. Moreover -- and in contrast with other methods -- the hierarchical nature of hyperbolic space allows us to learn highly efficient representations and to improve the taxonomic consistency of the inferred hierarchies. Experimentally, we show that our approach achieves state-of-the-art performance on several commonly-used benchmarks.
Searching for significant patterns in stratified data
Aug 24, 2015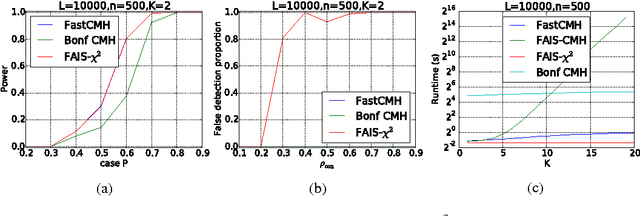
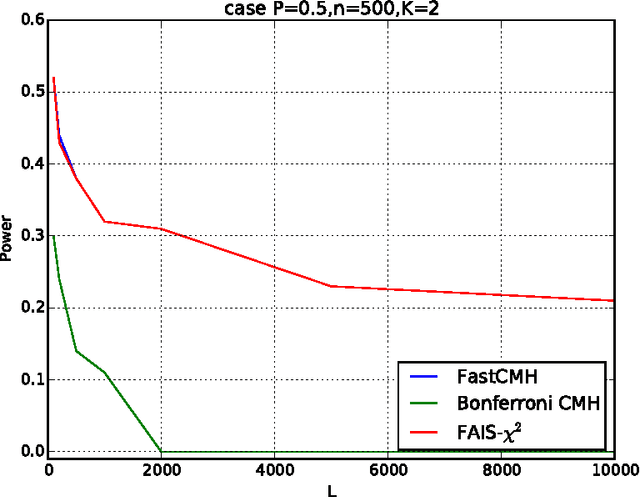
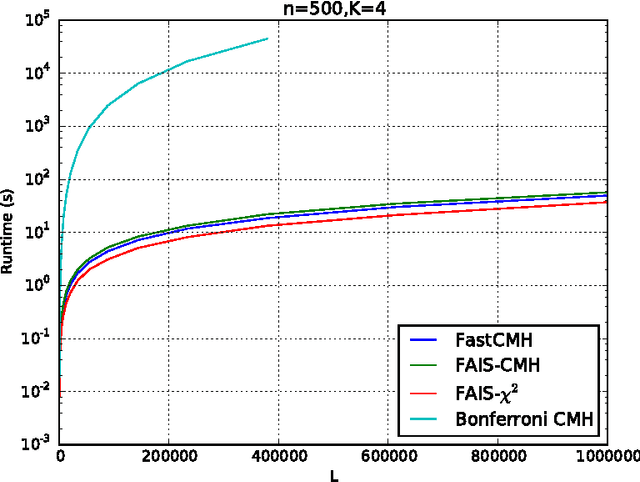
Significant pattern mining, the problem of finding itemsets that are significantly enriched in one class of objects, is statistically challenging, as the large space of candidate patterns leads to an enormous multiple testing problem. Recently, the concept of testability was proposed as one approach to correct for multiple testing in pattern mining while retaining statistical power. Still, these strategies based on testability do not allow one to condition the test of significance on the observed covariates, which severely limits its utility in biomedical applications. Here we propose a strategy and an efficient algorithm to perform significant pattern mining in the presence of categorical covariates with K states.
Fast and Memory-Efficient Significant Pattern Mining via Permutation Testing
Feb 15, 2015



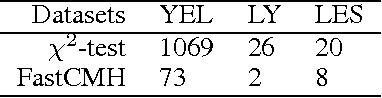
We present a novel algorithm, Westfall-Young light, for detecting patterns, such as itemsets and subgraphs, which are statistically significantly enriched in one of two classes. Our method corrects rigorously for multiple hypothesis testing and correlations between patterns through the Westfall-Young permutation procedure, which empirically estimates the null distribution of pattern frequencies in each class via permutations. In our experiments, Westfall-Young light dramatically outperforms the current state-of-the-art approach in terms of both runtime and memory efficiency on popular real-world benchmark datasets for pattern mining. The key to this efficiency is that unlike all existing methods, our algorithm neither needs to solve the underlying frequent itemset mining problem anew for each permutation nor needs to store the occurrence list of all frequent patterns. Westfall-Young light opens the door to significant pattern mining on large datasets that previously led to prohibitive runtime or memory costs.