 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Significant Combinations of Continuous Features
May 22, 2017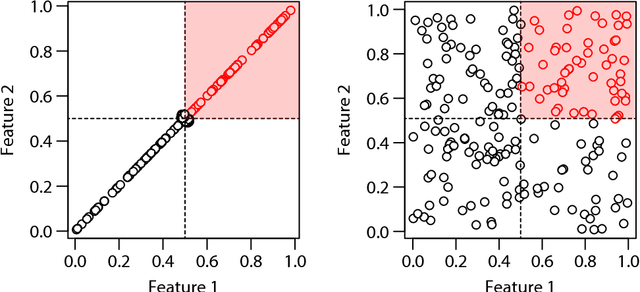

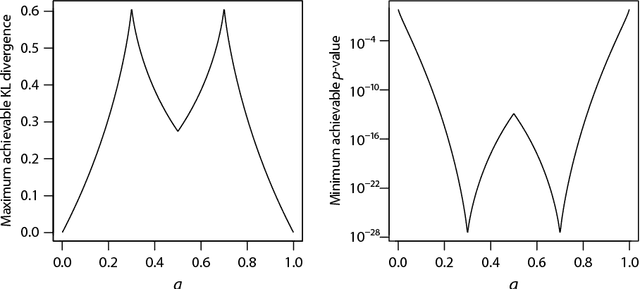
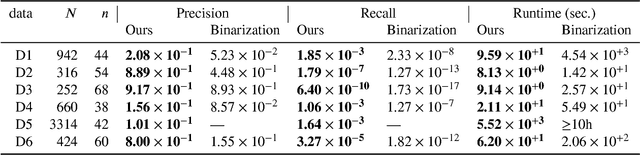
We present an efficient feature selection method that can find all multiplicative combinations of continuous features that are statistically significantly associated with the class variable, while rigorously correcting for multiple testing. The key to overcome the combinatorial explosion in the number of candidates is to derive a lower bound on the $p$-value for each feature combination, which enables us to massively prune combinations that can never be significant and gain more statistical power. While this problem has been addressed for binary features in the past, we here present the first solution for continuous features. In our experiments, our novel approach detects true feature combinations with higher precision and recall than competing methods that require a prior binarization of the data.
Fast and Memory-Efficient Significant Pattern Mining via Permutation Testing
Feb 15, 2015



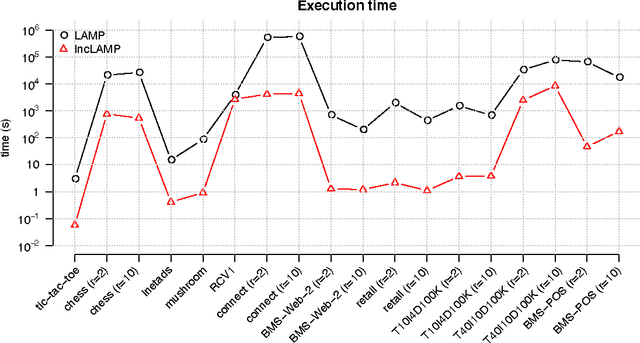
We present a novel algorithm, Westfall-Young light, for detecting patterns, such as itemsets and subgraphs, which are statistically significantly enriched in one of two classes. Our method corrects rigorously for multiple hypothesis testing and correlations between patterns through the Westfall-Young permutation procedure, which empirically estimates the null distribution of pattern frequencies in each class via permutations. In our experiments, Westfall-Young light dramatically outperforms the current state-of-the-art approach in terms of both runtime and memory efficiency on popular real-world benchmark datasets for pattern mining. The key to this efficiency is that unlike all existing methods, our algorithm neither needs to solve the underlying frequent itemset mining problem anew for each permutation nor needs to store the occurrence list of all frequent patterns. Westfall-Young light opens the door to significant pattern mining on large datasets that previously led to prohibitive runtime or memory costs.
Significant Subgraph Mining with Multiple Testing Correction
Jan 30, 2015
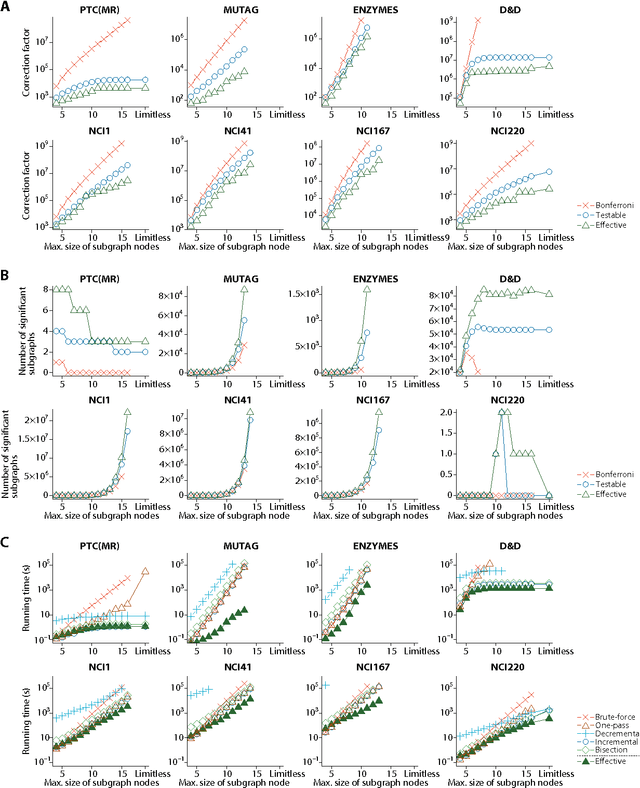
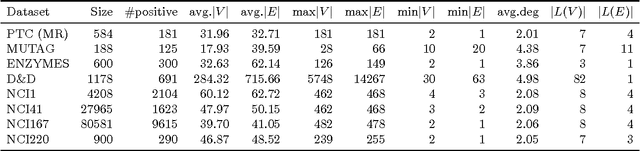
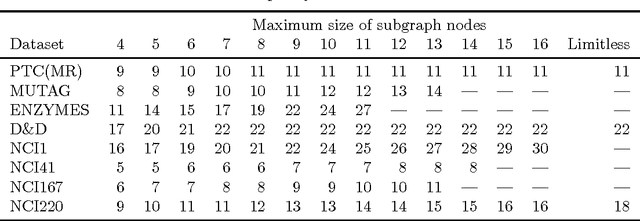
The problem of finding itemsets that are statistically significantly enriched in a class of transactions is complicated by the need to correct for multiple hypothesis testing. Pruning untestable hypotheses was recently proposed as a strategy for this task of significant itemset mining. It was shown to lead to greater statistical power, the discovery of more truly significant itemsets, than the standard Bonferroni correction on real-world datasets. An open question, however, is whether this strategy of excluding untestable hypotheses also leads to greater statistical power in subgraph mining, in which the number of hypotheses is much larger than in itemset mining. Here we answer this question by an empirical investigation on eight popular graph benchmark datasets. We propose a new efficient search strategy, which always returns the same solution as the state-of-the-art approach and is approximately two orders of magnitude faster. Moreover, we exploit the dependence between subgraphs by considering the effective number of tests and thereby further increase the statistical power.
Identifying Higher-order Combinations of Binary Features
Jul 04, 2014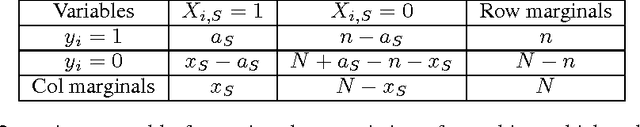
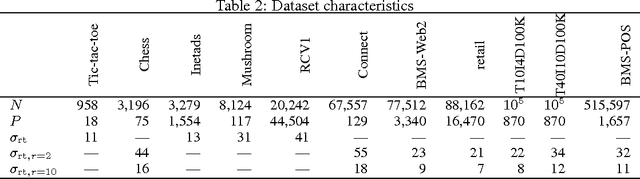
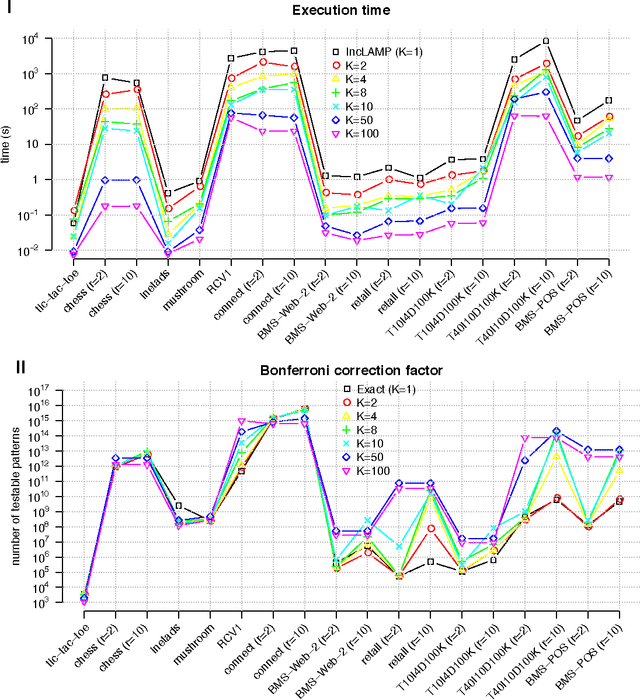
Finding statistically significant interactions between binary variables is computationally and statistically challenging in high-dimensional settings, due to the combinatorial explosion in the number of hypotheses. Terada et al. recently showed how to elegantly address this multiple testing problem by excluding non-testable hypotheses. Still, it remains unclear how their approach scales to large datasets. We here proposed strategies to speed up the approach by Terada et al. and evaluate them thoroughly in 11 real-world benchmark datasets. We observe that one approach, incremental search with early stopping, is orders of magnitude faster than the current state-of-the-art approach.
Efficient network-guided multi-locus association mapping with graph cuts
Apr 18, 2013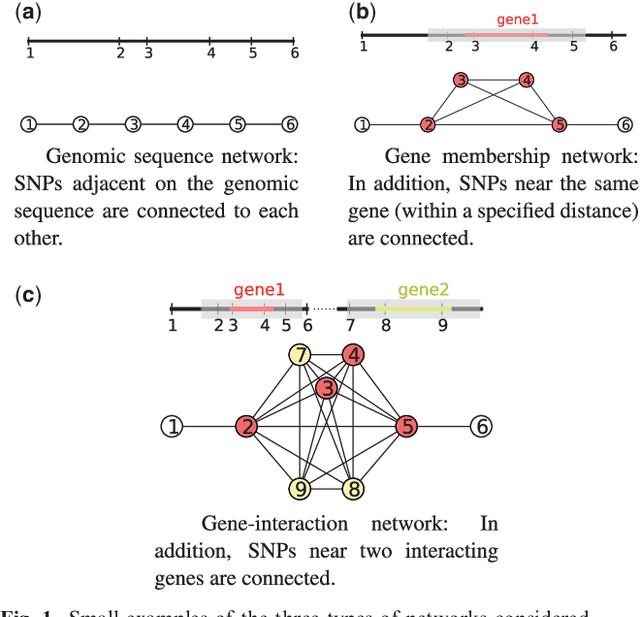
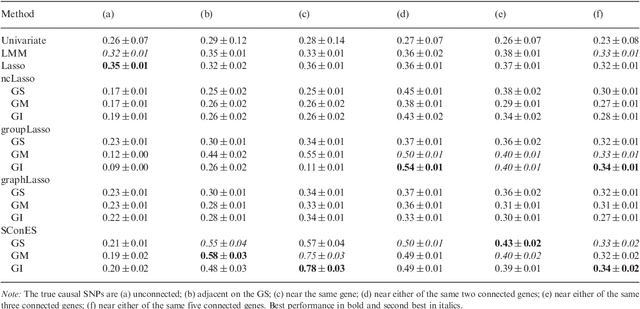
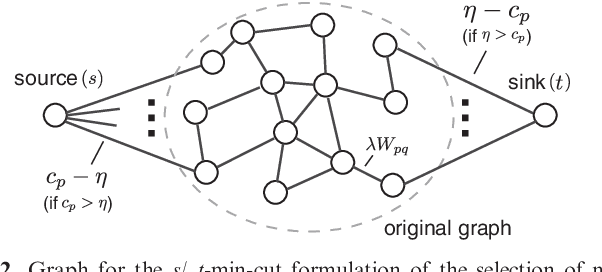

As an increasing number of genome-wide association studies reveal the limitations of attempting to explain phenotypic heritability by single genetic loci, there is growing interest for associating complex phenotypes with sets of genetic loci. While several methods for multi-locus mapping have been proposed, it is often unclear how to relate the detected loci to the growing knowledge about gene pathways and networks. The few methods that take biological pathways or networks into account are either restricted to investigating a limited number of predetermined sets of loci, or do not scale to genome-wide settings. We present SConES, a new efficient method to discover sets of genetic loci that are maximally associated with a phenotype, while being connected in an underlying network. Our approach is based on a minimum cut reformulation of the problem of selecting features under sparsity and connectivity constraints that can be solved exactly and rapidly. SConES outperforms state-of-the-art competitors in terms of runtime, scales to hundreds of thousands of genetic loci, and exhibits higher power in detecting causal SNPs in simulation studies than existing methods. On flowering time phenotypes and genotypes from Arabidopsis thaliana, SConES detects loci that enable accurate phenotype prediction and that are supported by the literature. Matlab code for SConES is available at http://webdav.tuebingen.mpg.de/u/karsten/Forschung/scones/
Bayesian two-sample tests
Jun 22, 2009In this paper, we present two classes of Bayesian approaches to the two-sample problem. Our first class of methods extends the Bayesian t-test to include all parametric models in the exponential family and their conjugate priors. Our second class of methods uses Dirichlet process mixtures (DPM) of such conjugate-exponential distributions as flexible nonparametric priors over the unknown distributions.
Graph Kernels
Jul 01, 2008


We present a unified framework to study graph kernels, special cases of which include the random walk graph kernel \citep{GaeFlaWro03,BorOngSchVisetal05}, marginalized graph kernel \citep{KasTsuIno03,KasTsuIno04,MahUedAkuPeretal04}, and geometric kernel on graphs \citep{Gaertner02}. Through extensions of linear algebra to Reproducing Kernel Hilbert Spaces (RKHS) and reduction to a Sylvester equation, we construct an algorithm that improves the time complexity of kernel computation from $O(n^6)$ to $O(n^3)$. When the graphs are sparse, conjugate gradient solvers or fixed-point iterations bring our algorithm into the sub-cubic domain. Experiments on graphs from bioinformatics and other application domains show that it is often more than a thousand times faster than previous approaches. We then explore connections between diffusion kernels \citep{KonLaf02}, regularization on graphs \citep{SmoKon03}, and graph kernels, and use these connections to propose new graph kernels. Finally, we show that rational kernels \citep{CorHafMoh02,CorHafMoh03,CorHafMoh04} when specialized to graphs reduce to the random walk graph kernel.
* http://jmlr.csail.mit.edu/papers/v11/vishwanathan10a.html