Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Higher-order Combinations of Binary Features
Paper and Code
Jul 04, 2014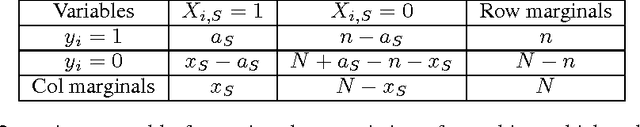
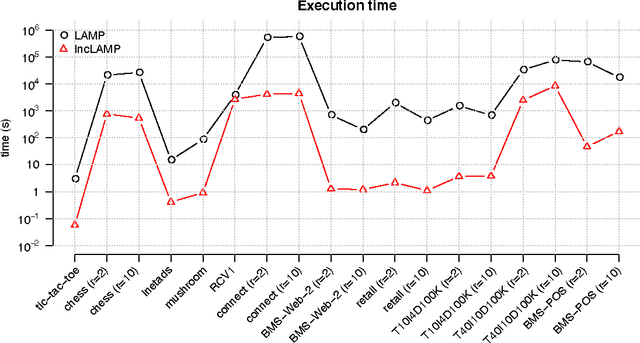
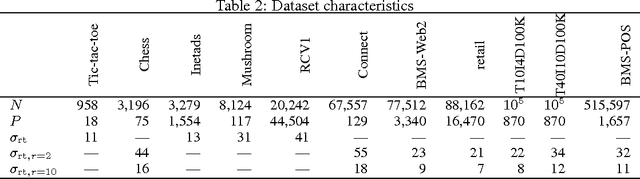
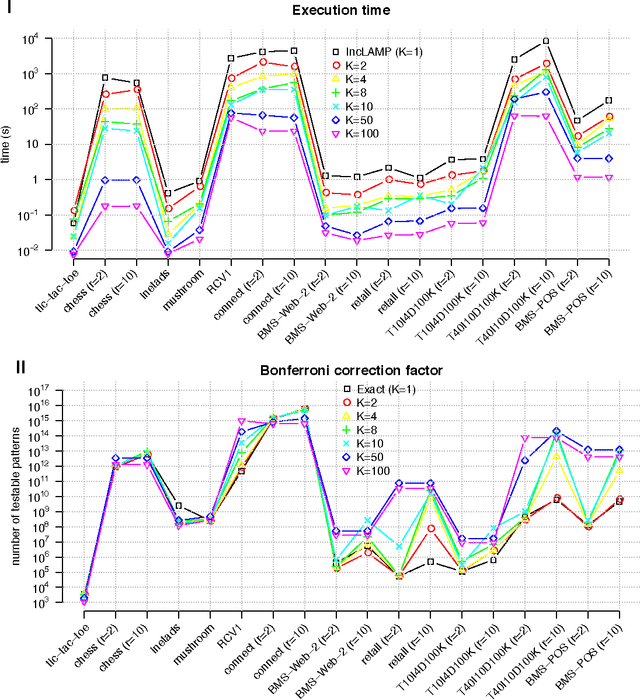
Finding statistically significant interactions between binary variables is computationally and statistically challenging in high-dimensional settings, due to the combinatorial explosion in the number of hypotheses. Terada et al. recently showed how to elegantly address this multiple testing problem by excluding non-testable hypotheses. Still, it remains unclear how their approach scales to large datasets. We here proposed strategies to speed up the approach by Terada et al. and evaluate them thoroughly in 11 real-world benchmark datasets. We observe that one approach, incremental search with early stopping, is orders of magnitude faster than the current state-of-the-art approach.
View paper on