 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Spectral Learning of Embedded Latent Transfer Operators for Stochastic Dynamical Systems
Jun 12, 2026We propose a spectral learning method for stochastic nonlinear dynamical systems represented with embedded latent transfer operators in deep feature spaces. We instantiate the method as Deep Spectral Encoder (DSE), an operator-based latent state-space model in which a time-invariant neural encoder implements learnable nonlinear feature maps from observations, and these features define Markovian latent states whose temporal evolution and observation mapping are described by the transfer and observation operators, respectively. Functional canonical correlation analysis in a learnable Galerkin-projected feature space provides state coordinates from past and future observations, and the two linear operators are estimated on the state coordinates as ridge-regularized closed-form solutions that coincide with Galerkin projections of the associated covariance operators. On this representation, we generalize sequential Bayesian filtering and Koopman spectral mode decomposition in feature space. Experiments on several scenarios show stable and superior performance with sequential Bayesian filtering and dynamic mode decomposition baselines even under noise and partial observability.
Structured Noise Adaptation for Sequential Bayesian Filtering with Embedded Latent Transfer Operators
Jun 12, 2026Kalman filters based on the Embedded Latent Transfer Operators (ELTO) emerge as novel statistical tools for sequential state estimation. However, a critical limitation stems from their use of simplified noise models, which fail to dynamically adapt to non-stationary processes. To address this limitation, we introduce an ELTO-based Bayesian filtering approach with a new structured parameterization for the filter's noise model. This parameterization enables structured noise adaptation, which couples the data-driven learning of an optimal time-invariant noise model with dynamic parameter adaptation that responds to changes in dynamics within non-stationary processes. Empirical results show that our structured noise adaptation improves the filter's dynamic state estimation performance in noisy, time-varying environments.
Data-driven sparse identification of governing PDEs via knockoff filters and multi-criteria trade-offs
May 26, 2026We propose KO-PDE-IDENT, a data-driven framework for identifying parsimonious partial differential equations (PDEs) with false discovery rate (FDR) control. PDE discovery from noisy observations is often hindered by extreme multicollinearity among candidate terms, which causes typical sparse-regression methods to select spurious terms. To address this problem, KO-PDE-IDENT initially mines a support set of potential candidate terms via model-X knockoff filters with finite-sample FDR control, then refines and ranks the surviving PDE alternatives. The framework integrates three components. First, knockoff feature statistics are constructed by coupling $\ell_{0}$-constrained adaptive best-subset selection with SHapley Additive exPlanations (SHAP), yielding an effective and computationally efficient difference statistic. Second, a recursive feature elimination (RFE) procedure removes terms whose marginal contributions are dispensable and assesses statistical necessity through knockoff-perturbed hypothesis testing. Third, the final model selection is formulated as a multi-criteria decision-making (MCDM) problem, where the optimal governing equation is the alternative that best balances a wide range of criteria such as predictive accuracy, model complexity and coefficient uncertainty. We validate KO-PDE-IDENT on five canonical PDEs under severe noise corruption. Empirical results show that our framework can exactly recover the true PDE structure, eliminating false discoveries while retaining all true underlying terms, with low coefficient estimation error.
Physics-inspired transformer quantum states via latent imaginary-time evolution
Feb 03, 2026Neural quantum states (NQS) are powerful ansätze in the variational Monte Carlo framework, yet their architectures are often treated as black boxes. We propose a physically transparent framework in which NQS are treated as neural approximations to latent imaginary-time evolution. This viewpoint suggests that standard Transformer-based NQS (TQS) architectures correspond to physically unmotivated effective Hamiltonians dependent on imaginary time in a latent space. Building on this interpretation, we introduce physics-inspired transformer quantum states (PITQS), which enforce a static effective Hamiltonian by sharing weights across layers and improve propagation accuracy via Trotter-Suzuki decompositions without increasing the number of variational parameters. For the frustrated $J_1$-$J_2$ Heisenberg model, our ansätze achieve accuracies comparable to or exceeding state-of-the-art TQS while using substantially fewer variational parameters. This study demonstrates that reinterpreting the deep network structure as a latent cooling process enables a more physically grounded, systematic, and compact design, thereby bridging the gap between black-box expressivity and physically transparent construction.
Dualformer: Time-Frequency Dual Domain Learning for Long-term Time Series Forecasting
Jan 22, 2026Transformer-based models, despite their promise for long-term time series forecasting (LTSF), suffer from an inherent low-pass filtering effect that limits their effectiveness. This issue arises due to undifferentiated propagation of frequency components across layers, causing a progressive attenuation of high-frequency information crucial for capturing fine-grained temporal variations. To address this limitation, we propose Dualformer, a principled dual-domain framework that rethinks frequency modeling from a layer-wise perspective. Dualformer introduces three key components: (1) a dual-branch architecture that concurrently models complementary temporal patterns in both time and frequency domains; (2) a hierarchical frequency sampling module that allocates distinct frequency bands to different layers, preserving high-frequency details in lower layers while modeling low-frequency trends in deeper layers; and (3) a periodicity-aware weighting mechanism that dynamically balances contributions from the dual branches based on the harmonic energy ratio of inputs, supported theoretically by a derived lower bound. This design enables structured frequency modeling and adaptive integration of time-frequency features, effectively preserving high-frequency information and enhancing generalization. Extensive experiments conducted on eight widely used benchmarks demonstrate Dualformer's robustness and superior performance, particularly on heterogeneous or weakly periodic data. Our code is publicly available at https://github.com/Akira-221/Dualformer.
Explorative Curriculum Learning for Strongly Correlated Electron Systems
May 01, 2025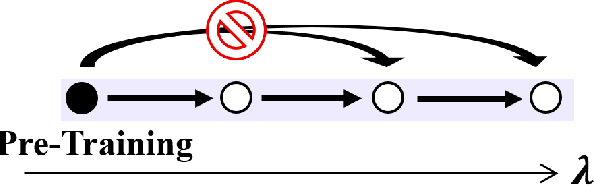
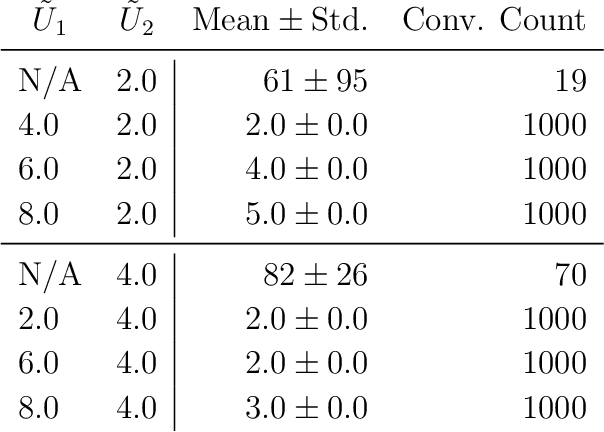
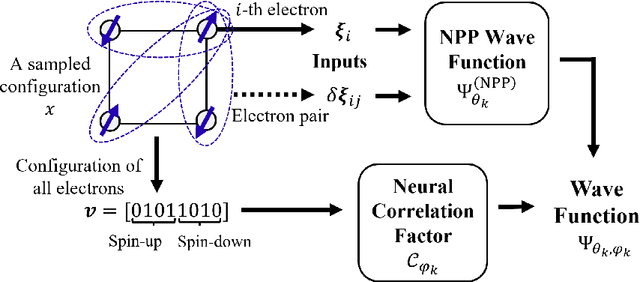
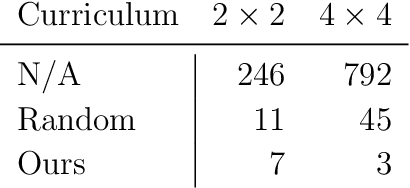
Recent advances in neural network quantum states (NQS) have enabled high-accuracy predictions for complex quantum many-body systems such as strongly correlated electron systems. However, the computational cost remains prohibitive, making exploration of the diverse parameters of interaction strengths and other physical parameters inefficient. While transfer learning has been proposed to mitigate this challenge, achieving generalization to large-scale systems and diverse parameter regimes remains difficult. To address this limitation, we propose a novel curriculum learning framework based on transfer learning for NQS. This facilitates efficient and stable exploration across a vast parameter space of quantum many-body systems. In addition, by interpreting NQS transfer learning through a perturbative lens, we demonstrate how prior physical knowledge can be flexibly incorporated into the curriculum learning process. We also propose Pairing-Net, an architecture to practically implement this strategy for strongly correlated electron systems, and empirically verify its effectiveness. Our results show an approximately 200-fold speedup in computation and a marked improvement in optimization stability compared to conventional methods.
Learning Stochastic Nonlinear Dynamics with Embedded Latent Transfer Operators
Jan 08, 2025



We consider an operator-based latent Markov representation of a stochastic nonlinear dynamical system, where the stochastic evolution of the latent state embedded in a reproducing kernel Hilbert space is described with the corresponding transfer operator, and develop a spectral method to learn this representation based on the theory of stochastic realization. The embedding may be learned simultaneously using reproducing kernels, for example, constructed with feed-forward neural networks. We also address the generalization of sequential state-estimation (Kalman filtering) in stochastic nonlinear systems, and of operator-based eigen-mode decomposition of dynamics, for the representation. Several examples with synthetic and real-world data are shown to illustrate the empirical characteristics of our methods, and to investigate the performance of our model in sequential state-estimation and mode decomposition.
Change-Point Detection in Industrial Data Streams based on Online Dynamic Mode Decomposition with Control
Jul 08, 2024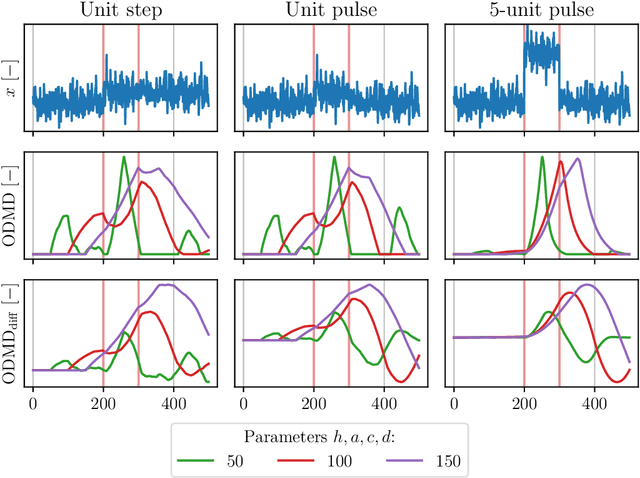

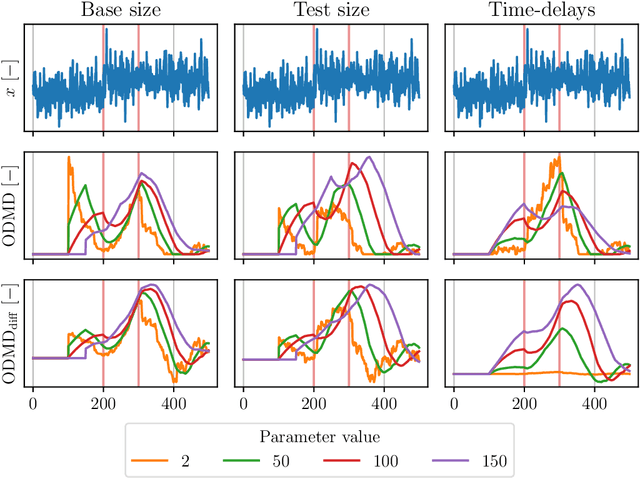
We propose a novel change-point detection method based on online Dynamic Mode Decomposition with control (ODMDwC). Leveraging ODMDwC's ability to find and track linear approximation of a non-linear system while incorporating control effects, the proposed method dynamically adapts to its changing behavior due to aging and seasonality. This approach enables the detection of changes in spatial, temporal, and spectral patterns, providing a robust solution that preserves correspondence between the score and the extent of change in the system dynamics. We formulate a truncated version of ODMDwC and utilize higher-order time-delay embeddings to mitigate noise and extract broad-band features. Our method addresses the challenges faced in industrial settings where safety-critical systems generate non-uniform data streams while requiring timely and accurate change-point detection to protect profit and life. Our results demonstrate that this method yields intuitive and improved detection results compared to the Singular-Value-Decomposition-based method. We validate our approach using synthetic and real-world data, showing its competitiveness to other approaches on complex systems' benchmark datasets. Provided guidelines for hyperparameters selection enhance our method's practical applicability.
SiT: Symmetry-Invariant Transformers for Generalisation in Reinforcement Learning
Jun 21, 2024



An open challenge in reinforcement learning (RL) is the effective deployment of a trained policy to new or slightly different situations as well as semantically-similar environments. We introduce Symmetry-Invariant Transformer (SiT), a scalable vision transformer (ViT) that leverages both local and global data patterns in a self-supervised manner to improve generalisation. Central to our approach is Graph Symmetric Attention, which refines the traditional self-attention mechanism to preserve graph symmetries, resulting in invariant and equivariant latent representations. We showcase SiT's superior generalization over ViTs on MiniGrid and Procgen RL benchmarks, and its sample efficiency on Atari 100k and CIFAR10.
The Disappearance of Timestep Embedding in Modern Time-Dependent Neural Networks
May 23, 2024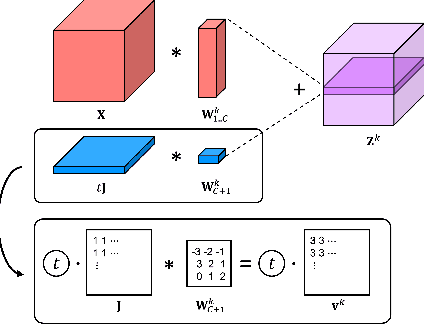
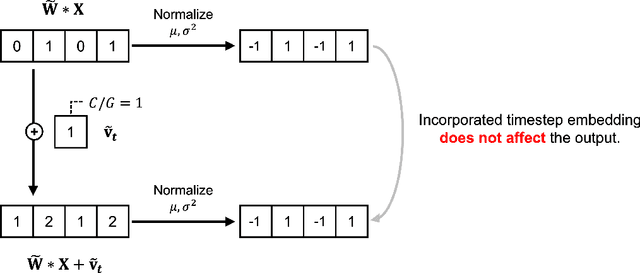
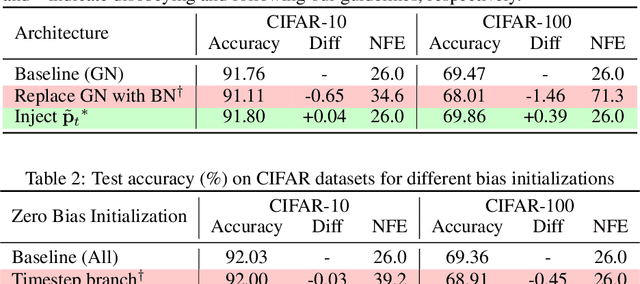
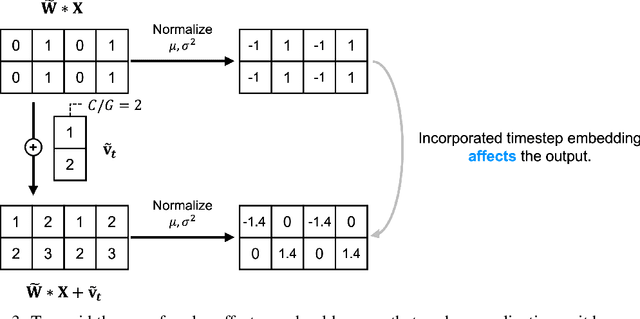
Dynamical systems are often time-varying, whose modeling requires a function that evolves with respect to time. Recent studies such as the neural ordinary differential equation proposed a time-dependent neural network, which provides a neural network varying with respect to time. However, we claim that the architectural choice to build a time-dependent neural network significantly affects its time-awareness but still lacks sufficient validation in its current states. In this study, we conduct an in-depth analysis of the architecture of modern time-dependent neural networks. Here, we report a vulnerability of vanishing timestep embedding, which disables the time-awareness of a time-dependent neural network. Furthermore, we find that this vulnerability can also be observed in diffusion models because they employ a similar architecture that incorporates timestep embedding to discriminate between different timesteps during a diffusion process. Our analysis provides a detailed description of this phenomenon as well as several solutions to address the root cause. Through experiments on neural ordinary differential equations and diffusion models, we observed that ensuring alive time-awareness via proposed solutions boosted their performance, which implies that their current implementations lack sufficient time-dependency.