 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiT: Symmetry-Invariant Transformers for Generalisation in Reinforcement Learning
Jun 21, 2024



An open challenge in reinforcement learning (RL) is the effective deployment of a trained policy to new or slightly different situations as well as semantically-similar environments. We introduce Symmetry-Invariant Transformer (SiT), a scalable vision transformer (ViT) that leverages both local and global data patterns in a self-supervised manner to improve generalisation. Central to our approach is Graph Symmetric Attention, which refines the traditional self-attention mechanism to preserve graph symmetries, resulting in invariant and equivariant latent representations. We showcase SiT's superior generalization over ViTs on MiniGrid and Procgen RL benchmarks, and its sample efficiency on Atari 100k and CIFAR10.
Koopman Q-learning: Offline Reinforcement Learning via Symmetries of Dynamics
Nov 02, 2021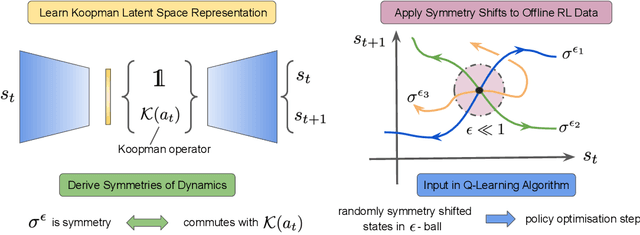
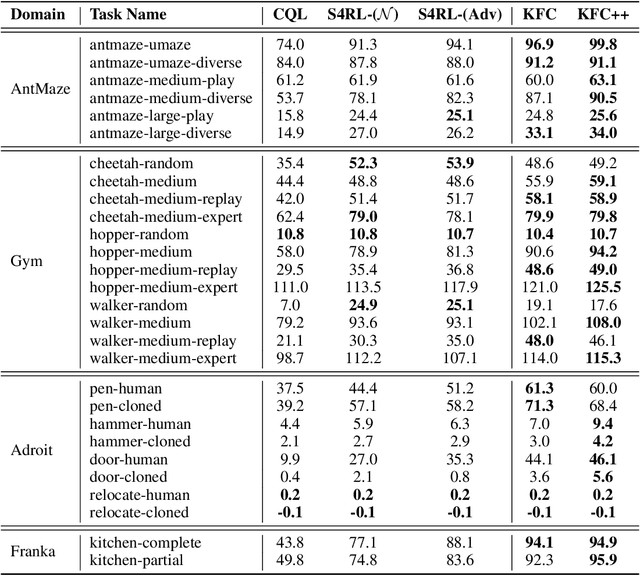
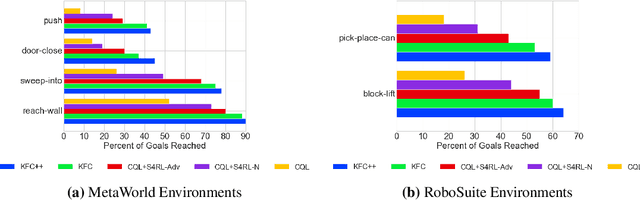
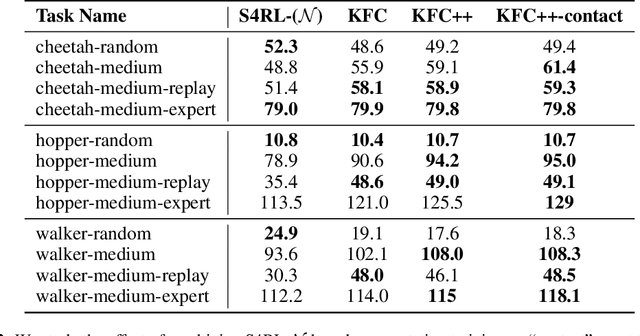
Offline reinforcement learning leverages large datasets to train policies without interactions with the environment. The learned policies may then be deployed in real-world settings where interactions are costly or dangerous. Current algorithms over-fit to the training dataset and as a consequence perform poorly when deployed to out-of-distribution generalizations of the environment. We aim to address these limitations by learning a Koopman latent representation which allows us to infer symmetries of the system's underlying dynamic. The latter is then utilized to extend the otherwise static offline dataset during training; this constitutes a novel data augmentation framework which reflects the system's dynamic and is thus to be interpreted as an exploration of the environments phase space. To obtain the symmetries we employ Koopman theory in which nonlinear dynamics are represented in terms of a linear operator acting on the space of measurement functions of the system and thus symmetries of the dynamics may be inferred directly. We provide novel theoretical results on the existence and nature of symmetries relevant for control systems such as reinforcement learning settings. Moreover, we empirically evaluate our method on several benchmark offline reinforcement learning tasks and datasets including D4RL, Metaworld and Robosuite and find that by using our framework we consistently improve the state-of-the-art for Q-learning methods.
A Quadratic Actor Network for Model-Free Reinforcement Learning
Mar 11, 2021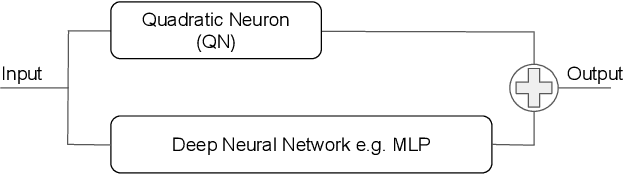
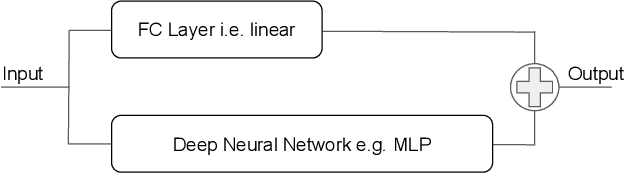
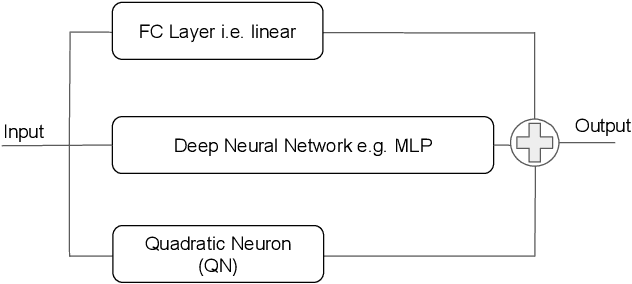
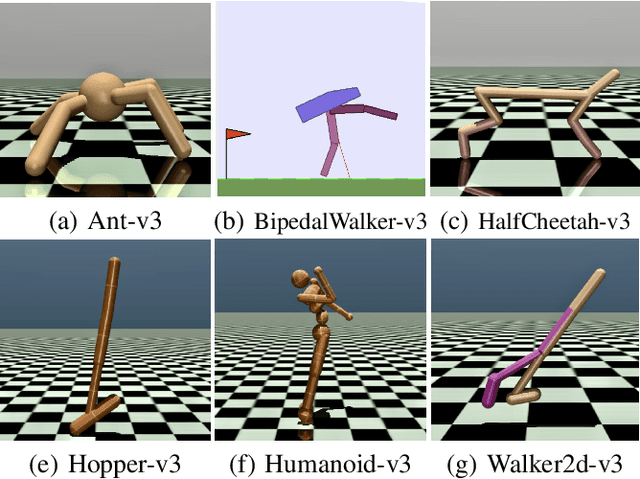
In this work we discuss the incorporation of quadratic neurons into policy networks in the context of model-free actor-critic reinforcement learning. Quadratic neurons admit an explicit quadratic function approximation in contrast to conventional approaches where the the non-linearity is induced by the activation functions. We perform empiric experiments on several MuJoCo continuous control tasks and find that when quadratic neurons are added to MLP policy networks those outperform the baseline MLP whilst admitting a smaller number of parameters. The top returned reward is in average increased by $5.8\%$ while being about $21\%$ more sample efficient. Moreover, it can maintain its advantage against added action and observation noise.
Temporally Folded Convolutional Neural Networks for Sequence Forecasting
Jan 10, 2020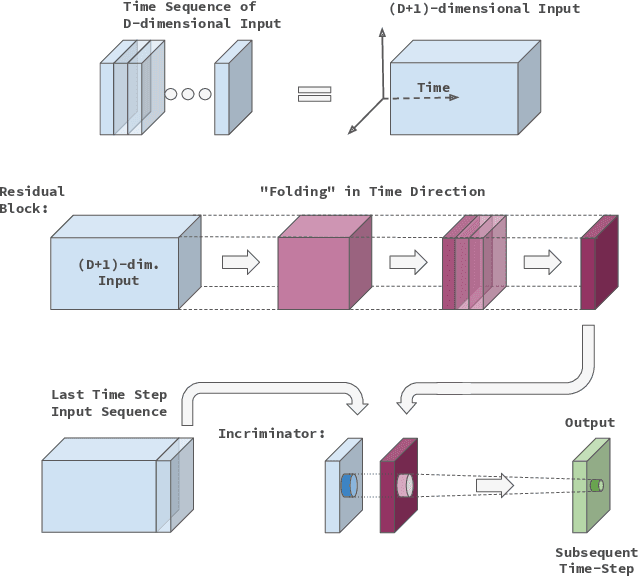
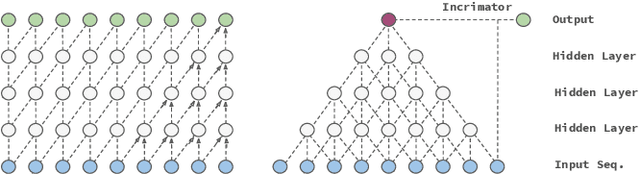
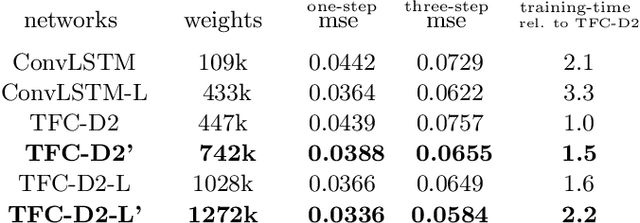

In this work we propose a novel approach to utilize convolutional neural networks for time series forecasting. The time direction of the sequential data with spatial dimensions $D=1,2$ is considered democratically as the input of a spatiotemporal $(D+1)$-dimensional convolutional neural network. Latter then reduces the data stream from $D +1 \to D$ dimensions followed by an incriminator cell which uses this information to forecast the subsequent time step. We empirically compare this strategy to convolutional LSTM's and LSTM's on their performance on the sequential MNIST and the JSB chorals dataset, respectively. We conclude that temporally folded convolutional neural networks (TFC's) may outperform the conventional recurrent strategies.