 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Δ$-Networks for Efficient Model Patching
Mar 26, 2023Models pre-trained on large-scale datasets are often finetuned to support newer tasks and datasets that arrive over time. This process necessitates storing copies of the model over time for each task that the pre-trained model is finetuned to. Building on top of recent model patching work, we propose $\Delta$-Patching for finetuning neural network models in an efficient manner, without the need to store model copies. We propose a simple and lightweight method called $\Delta$-Networks to achieve this objective. Our comprehensive experiments across setting and architecture variants show that $\Delta$-Networks outperform earlier model patching work while only requiring a fraction of parameters to be trained. We also show that this approach can be used for other problem settings such as transfer learning and zero-shot domain adaptation, as well as other tasks such as detection and segmentation.
Offline Policy Optimization in RL with Variance Regularizaton
Dec 29, 2022



Learning policies from fixed offline datasets is a key challenge to scale up reinforcement learning (RL) algorithms towards practical applications. This is often because off-policy RL algorithms suffer from distributional shift, due to mismatch between dataset and the target policy, leading to high variance and over-estimation of value functions. In this work, we propose variance regularization for offline RL algorithms, using stationary distribution corrections. We show that by using Fenchel duality, we can avoid double sampling issues for computing the gradient of the variance regularizer. The proposed algorithm for offline variance regularization (OVAR) can be used to augment any existing offline policy optimization algorithms. We show that the regularizer leads to a lower bound to the offline policy optimization objective, which can help avoid over-estimation errors, and explains the benefits of our approach across a range of continuous control domains when compared to existing state-of-the-art algorithms.
SparsePose: Sparse-View Camera Pose Regression and Refinement
Nov 29, 2022Camera pose estimation is a key step in standard 3D reconstruction pipelines that operate on a dense set of images of a single object or scene. However, methods for pose estimation often fail when only a few images are available because they rely on the ability to robustly identify and match visual features between image pairs. While these methods can work robustly with dense camera views, capturing a large set of images can be time-consuming or impractical. We propose SparsePose for recovering accurate camera poses given a sparse set of wide-baseline images (fewer than 10). The method learns to regress initial camera poses and then iteratively refine them after training on a large-scale dataset of objects (Co3D: Common Objects in 3D). SparsePose significantly outperforms conventional and learning-based baselines in recovering accurate camera rotations and translations. We also demonstrate our pipeline for high-fidelity 3D reconstruction using only 5-9 images of an object.
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories
Nov 07, 2022



Obtaining photorealistic reconstructions of objects from sparse views is inherently ambiguous and can only be achieved by learning suitable reconstruction priors. Earlier works on sparse rigid object reconstruction successfully learned such priors from large datasets such as CO3D. In this paper, we extend this approach to dynamic objects. We use cats and dogs as a representative example and introduce Common Pets in 3D (CoP3D), a collection of crowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of the first large-scale datasets for benchmarking non-rigid 3D reconstruction "in the wild". We also propose Tracker-NeRF, a method for learning 4D reconstruction from our dataset. At test time, given a small number of video frames of an unseen object, Tracker-NeRF predicts the trajectories of its 3D points and generates new views, interpolating viewpoint and time. Results on CoP3D reveal significantly better non-rigid new-view synthesis performance than existing baselines.
TeST: Test-time Self-Training under Distribution Shift
Sep 23, 2022
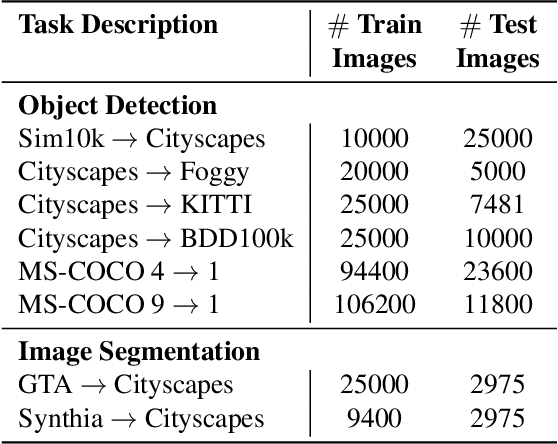
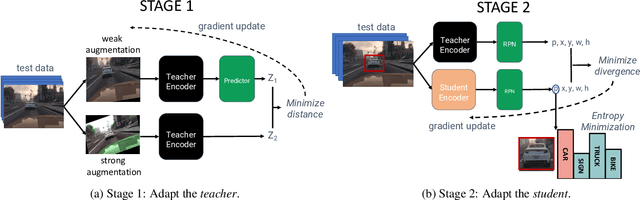
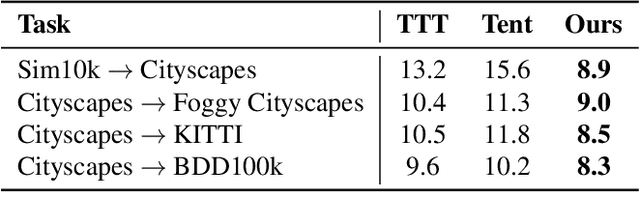
Despite their recent success, deep neural networks continue to perform poorly when they encounter distribution shifts at test time. Many recently proposed approaches try to counter this by aligning the model to the new distribution prior to inference. With no labels available this requires unsupervised objectives to adapt the model on the observed test data. In this paper, we propose Test-Time Self-Training (TeST): a technique that takes as input a model trained on some source data and a novel data distribution at test time, and learns invariant and robust representations using a student-teacher framework. We find that models adapted using TeST significantly improve over baseline test-time adaptation algorithms. TeST achieves competitive performance to modern domain adaptation algorithms, while having access to 5-10x less data at time of adaption. We thoroughly evaluate a variety of baselines on two tasks: object detection and image segmentation and find that models adapted with TeST. We find that TeST sets the new state-of-the art for test-time domain adaptation algorithms.
Koopman Q-learning: Offline Reinforcement Learning via Symmetries of Dynamics
Nov 02, 2021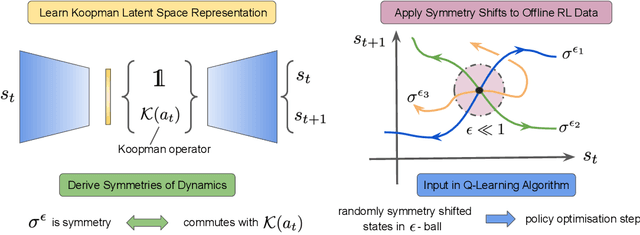
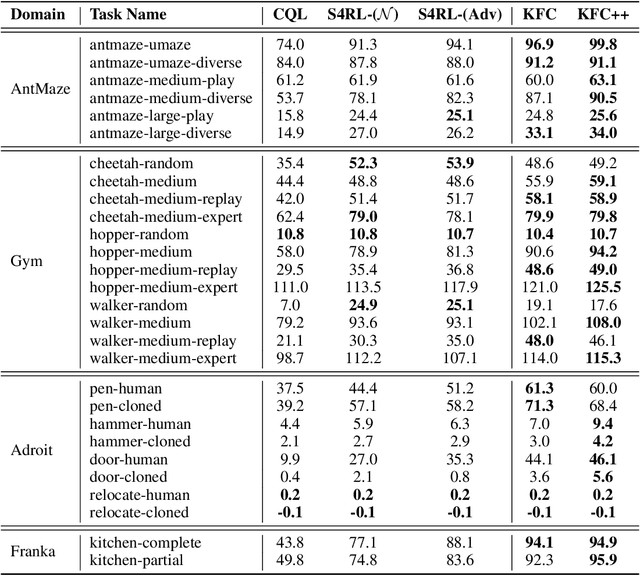
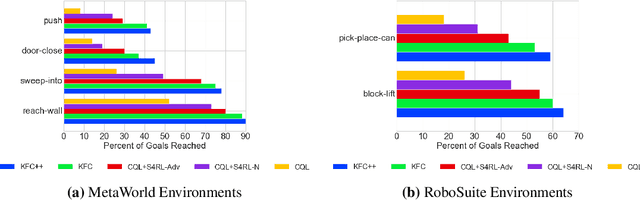
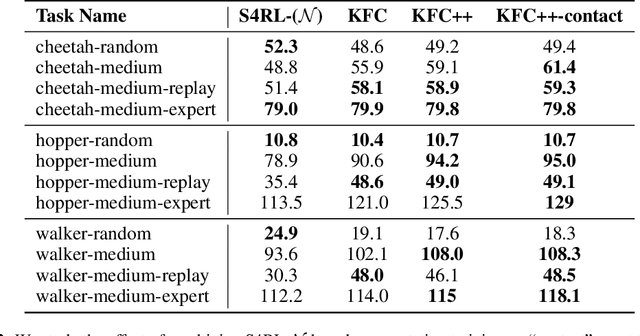
Offline reinforcement learning leverages large datasets to train policies without interactions with the environment. The learned policies may then be deployed in real-world settings where interactions are costly or dangerous. Current algorithms over-fit to the training dataset and as a consequence perform poorly when deployed to out-of-distribution generalizations of the environment. We aim to address these limitations by learning a Koopman latent representation which allows us to infer symmetries of the system's underlying dynamic. The latter is then utilized to extend the otherwise static offline dataset during training; this constitutes a novel data augmentation framework which reflects the system's dynamic and is thus to be interpreted as an exploration of the environments phase space. To obtain the symmetries we employ Koopman theory in which nonlinear dynamics are represented in terms of a linear operator acting on the space of measurement functions of the system and thus symmetries of the dynamics may be inferred directly. We provide novel theoretical results on the existence and nature of symmetries relevant for control systems such as reinforcement learning settings. Moreover, we empirically evaluate our method on several benchmark offline reinforcement learning tasks and datasets including D4RL, Metaworld and Robosuite and find that by using our framework we consistently improve the state-of-the-art for Q-learning methods.
Characterizing Generalization under Out-Of-Distribution Shifts in Deep Metric Learning
Jul 20, 2021
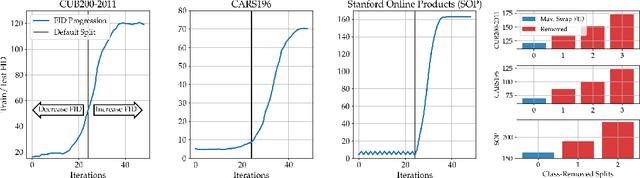
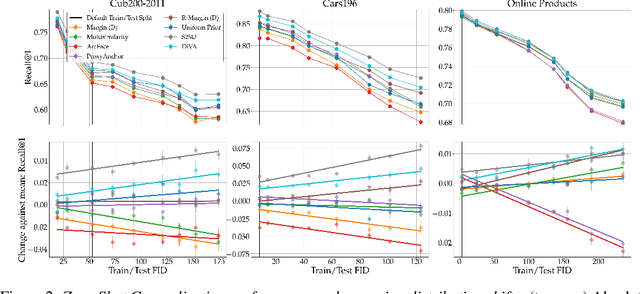
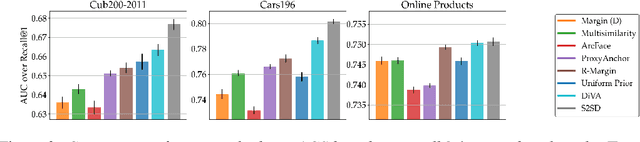
Deep Metric Learning (DML) aims to find representations suitable for zero-shot transfer to a priori unknown test distributions. However, common evaluation protocols only test a single, fixed data split in which train and test classes are assigned randomly. More realistic evaluations should consider a broad spectrum of distribution shifts with potentially varying degree and difficulty. In this work, we systematically construct train-test splits of increasing difficulty and present the ooDML benchmark to characterize generalization under out-of-distribution shifts in DML. ooDML is designed to probe the generalization performance on much more challenging, diverse train-to-test distribution shifts. Based on our new benchmark, we conduct a thorough empirical analysis of state-of-the-art DML methods. We find that while generalization tends to consistently degrade with difficulty, some methods are better at retaining performance as the distribution shift increases. Finally, we propose few-shot DML as an efficient way to consistently improve generalization in response to unknown test shifts presented in ooDML. Code available here: https://github.com/Confusezius/Characterizing_Generalization_in_DeepMetricLearning.
Consistency Regularization for Variational Auto-Encoders
May 31, 2021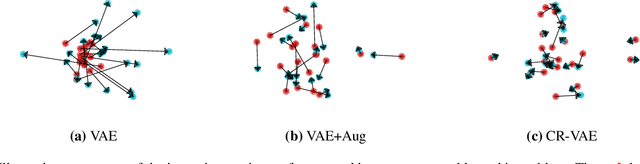
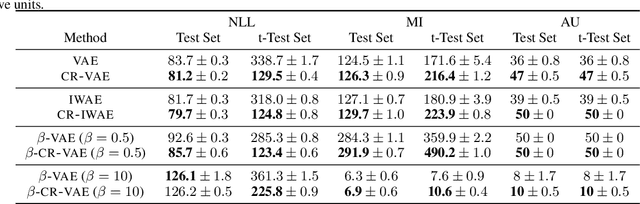
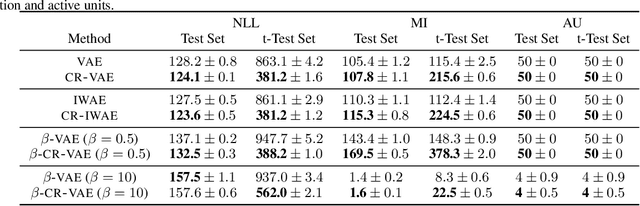
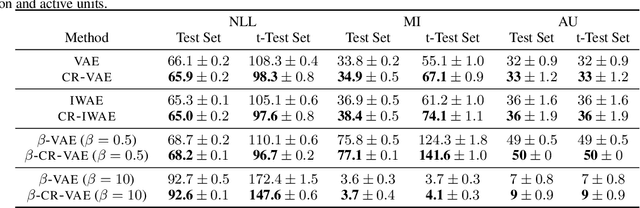
Variational auto-encoders (VAEs) are a powerful approach to unsupervised learning. They enable scalable approximate posterior inference in latent-variable models using variational inference (VI). A VAE posits a variational family parameterized by a deep neural network called an encoder that takes data as input. This encoder is shared across all the observations, which amortizes the cost of inference. However the encoder of a VAE has the undesirable property that it maps a given observation and a semantics-preserving transformation of it to different latent representations. This "inconsistency" of the encoder lowers the quality of the learned representations, especially for downstream tasks, and also negatively affects generalization. In this paper, we propose a regularization method to enforce consistency in VAEs. The idea is to minimize the Kullback-Leibler (KL) divergence between the variational distribution when conditioning on the observation and the variational distribution when conditioning on a random semantic-preserving transformation of this observation. This regularization is applicable to any VAE. In our experiments we apply it to four different VAE variants on several benchmark datasets and found it always improves the quality of the learned representations but also leads to better generalization. In particular, when applied to the Nouveau Variational Auto-Encoder (NVAE), our regularization method yields state-of-the-art performance on MNIST and CIFAR-10. We also applied our method to 3D data and found it learns representations of superior quality as measured by accuracy on a downstream classification task.
S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning
Mar 10, 2021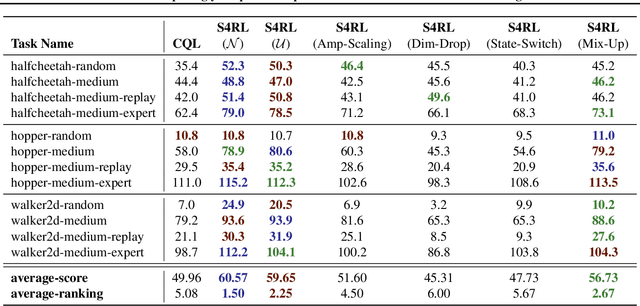
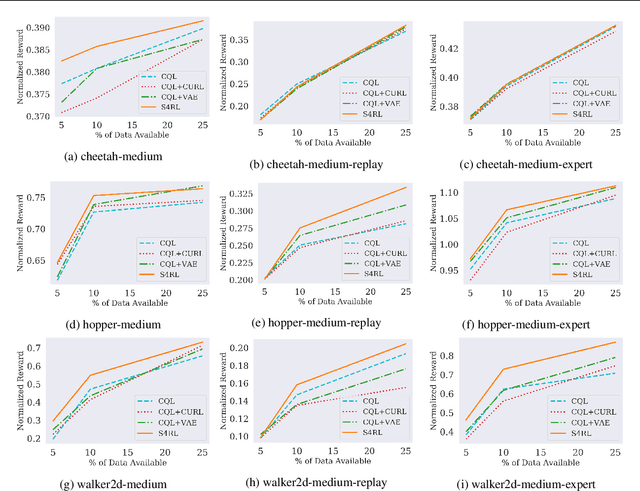
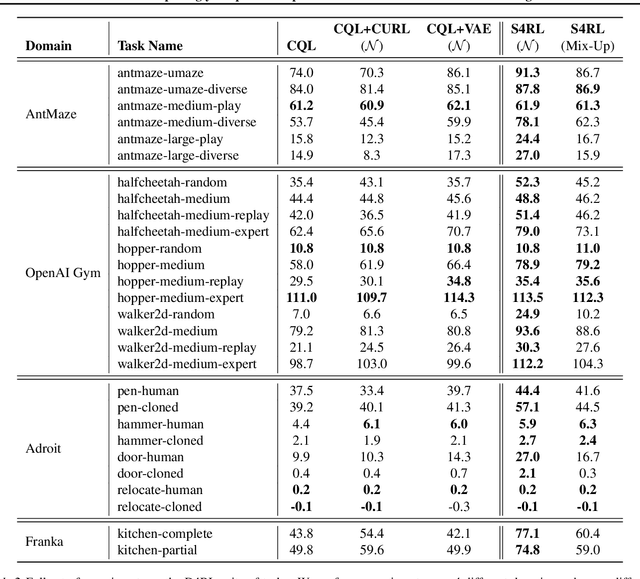
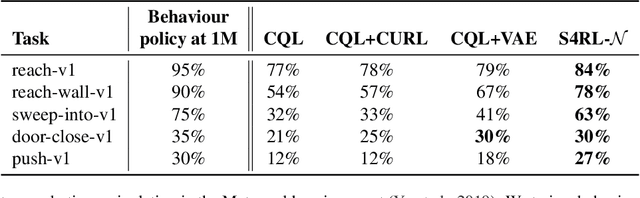
Offline reinforcement learning proposes to learn policies from large collected datasets without interaction. These algorithms have made it possible to learn useful skills from data that can then be transferred to the environment, making it feasible to deploy the trained policies in real-world settings where interactions may be costly or dangerous, such as self-driving. However, current algorithms overfit to the dataset they are trained on and perform poor out-of-distribution (OOD) generalization to the environment when deployed. We propose a Surprisingly Simple Self-Supervision algorithm (S4RL), which utilizes data augmentations from states to learn value functions that are better at generalizing and extrapolating when deployed in the environment. We investigate different data augmentation techniques that help learning a value function that can extrapolate to OOD data, and how to combine data augmentations and offline RL algorithms to learn a policy. We experimentally show that using S4RL significantly improves the state-of-the-art on most benchmark offline reinforcement learning tasks on popular benchmark datasets from D4RL, despite being simple and easy to implement.
Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Jan 18, 2021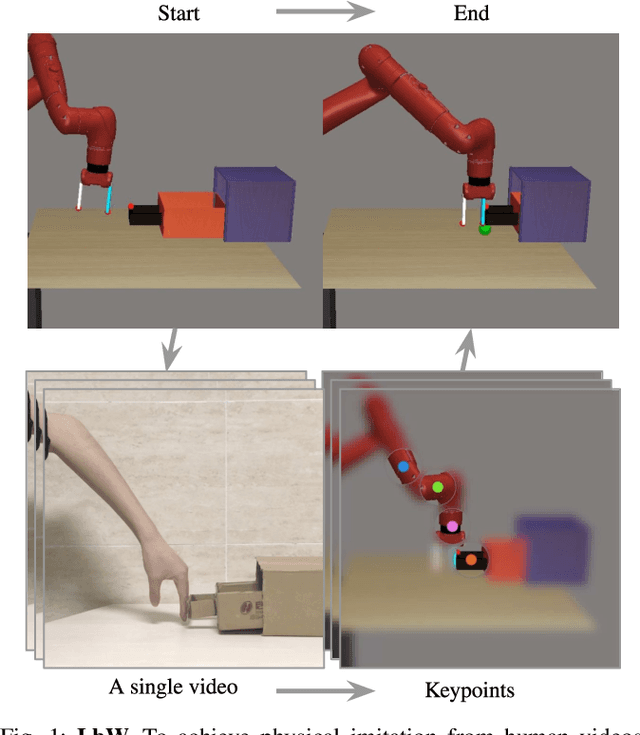
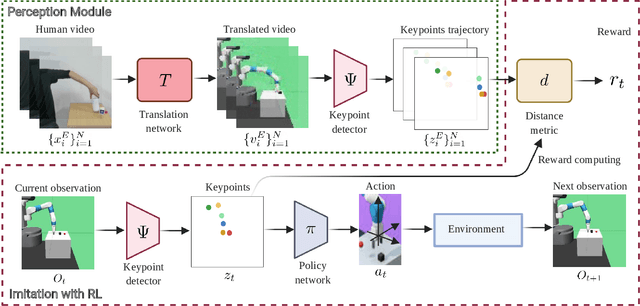
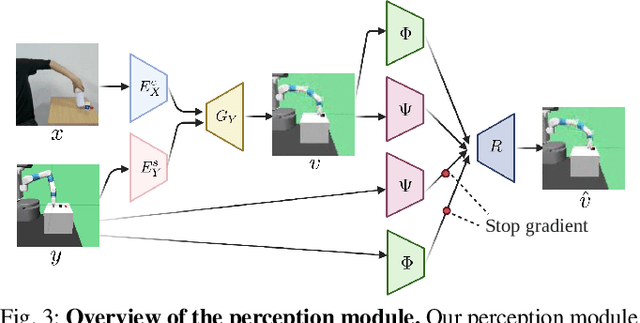

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.