 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Set Block Decoding is a Language Model Inference Accelerator
Sep 04, 2025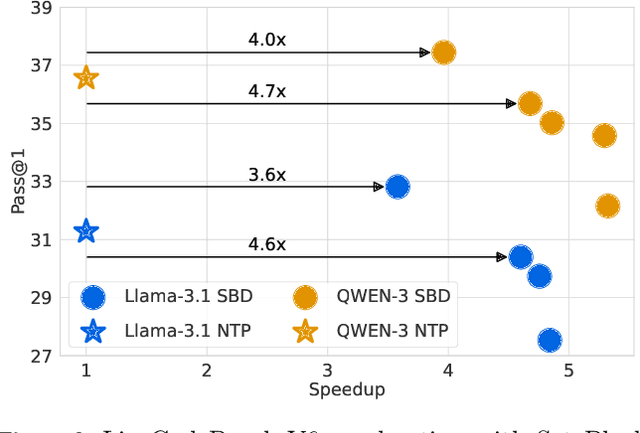
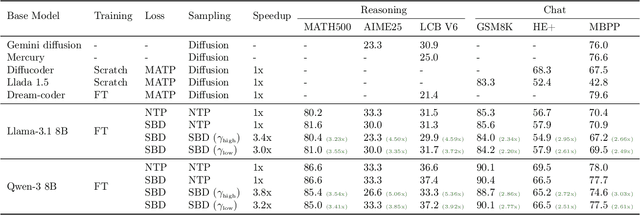
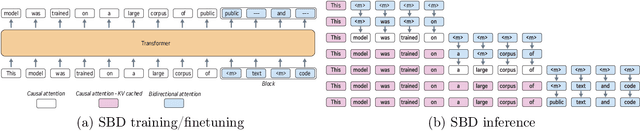

Autoregressive next token prediction language models offer powerful capabilities but face significant challenges in practical deployment due to the high computational and memory costs of inference, particularly during the decoding stage. We introduce Set Block Decoding (SBD), a simple and flexible paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture. SBD allows the model to sample multiple, not necessarily consecutive, future tokens in parallel, a key distinction from previous acceleration methods. This flexibility allows the use of advanced solvers from the discrete diffusion literature, offering significant speedups without sacrificing accuracy. SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models. By fine-tuning Llama-3.1 8B and Qwen-3 8B, we demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving same performance as equivalent NTP training.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories
Nov 07, 2022



Obtaining photorealistic reconstructions of objects from sparse views is inherently ambiguous and can only be achieved by learning suitable reconstruction priors. Earlier works on sparse rigid object reconstruction successfully learned such priors from large datasets such as CO3D. In this paper, we extend this approach to dynamic objects. We use cats and dogs as a representative example and introduce Common Pets in 3D (CoP3D), a collection of crowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of the first large-scale datasets for benchmarking non-rigid 3D reconstruction "in the wild". We also propose Tracker-NeRF, a method for learning 4D reconstruction from our dataset. At test time, given a small number of video frames of an unseen object, Tracker-NeRF predicts the trajectories of its 3D points and generates new views, interpolating viewpoint and time. Results on CoP3D reveal significantly better non-rigid new-view synthesis performance than existing baselines.
Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
Sep 01, 2021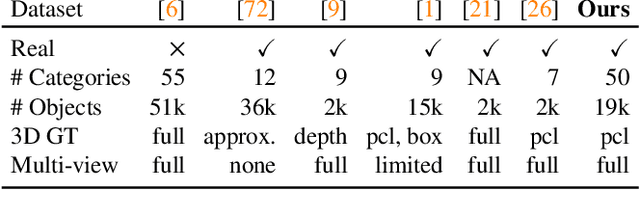
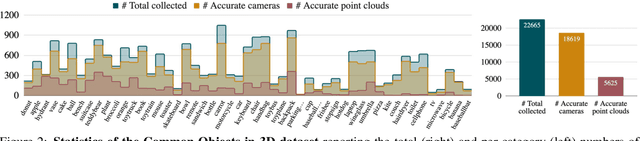
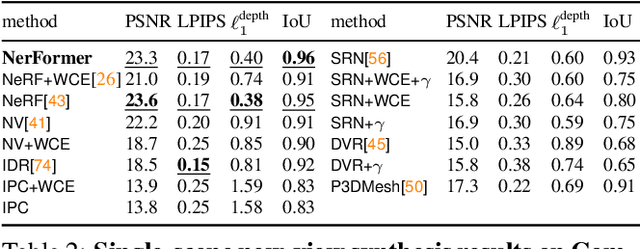
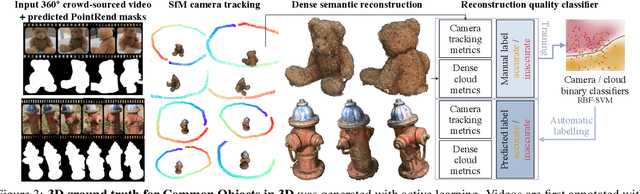
Traditional approaches for learning 3D object categories have been predominantly trained and evaluated on synthetic datasets due to the unavailability of real 3D-annotated category-centric data. Our main goal is to facilitate advances in this field by collecting real-world data in a magnitude similar to the existing synthetic counterparts. The principal contribution of this work is thus a large-scale dataset, called Common Objects in 3D, with real multi-view images of object categories annotated with camera poses and ground truth 3D point clouds. The dataset contains a total of 1.5 million frames from nearly 19,000 videos capturing objects from 50 MS-COCO categories and, as such, it is significantly larger than alternatives both in terms of the number of categories and objects. We exploit this new dataset to conduct one of the first large-scale "in-the-wild" evaluations of several new-view-synthesis and category-centric 3D reconstruction methods. Finally, we contribute NerFormer - a novel neural rendering method that leverages the powerful Transformer to reconstruct an object given a small number of its views. The CO3D dataset is available at https://github.com/facebookresearch/co3d .
Unsupervised Learning of 3D Object Categories from Videos in the Wild
Mar 30, 2021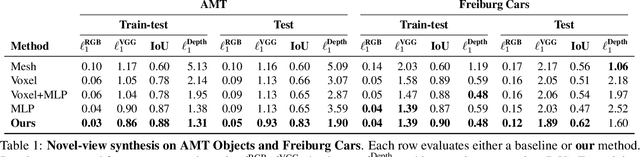
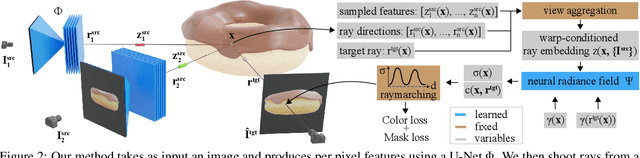
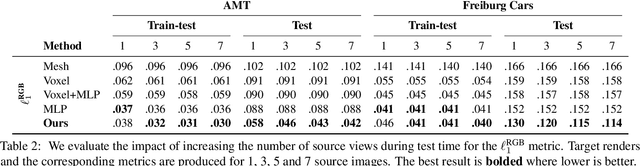

Our goal is to learn a deep network that, given a small number of images of an object of a given category, reconstructs it in 3D. While several recent works have obtained analogous results using synthetic data or assuming the availability of 2D primitives such as keypoints, we are interested in working with challenging real data and with no manual annotations. We thus focus on learning a model from multiple views of a large collection of object instances. We contribute with a new large dataset of object centric videos suitable for training and benchmarking this class of models. We show that existing techniques leveraging meshes, voxels, or implicit surfaces, which work well for reconstructing isolated objects, fail on this challenging data. Finally, we propose a new neural network design, called warp-conditioned ray embedding (WCR), which significantly improves reconstruction while obtaining a detailed implicit representation of the object surface and texture, also compensating for the noise in the initial SfM reconstruction that bootstrapped the learning process. Our evaluation demonstrates performance improvements over several deep monocular reconstruction baselines on existing benchmarks and on our novel dataset.
Accelerating 3D Deep Learning with PyTorch3D
Jul 16, 2020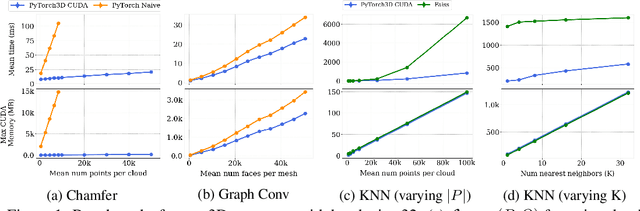
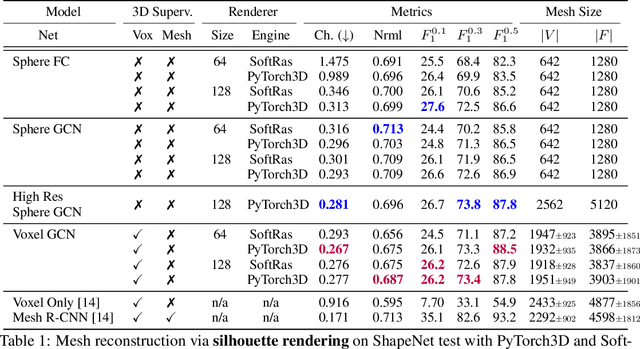
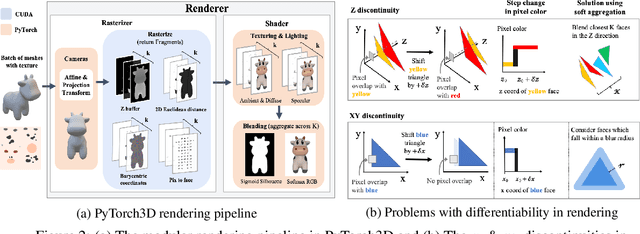
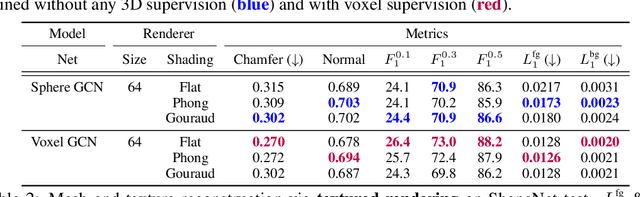
Deep learning has significantly improved 2D image recognition. Extending into 3D may advance many new applications including autonomous vehicles, virtual and augmented reality, authoring 3D content, and even improving 2D recognition. However despite growing interest, 3D deep learning remains relatively underexplored. We believe that some of this disparity is due to the engineering challenges involved in 3D deep learning, such as efficiently processing heterogeneous data and reframing graphics operations to be differentiable. We address these challenges by introducing PyTorch3D, a library of modular, efficient, and differentiable operators for 3D deep learning. It includes a fast, modular differentiable renderer for meshes and point clouds, enabling analysis-by-synthesis approaches. Compared with other differentiable renderers, PyTorch3D is more modular and efficient, allowing users to more easily extend it while also gracefully scaling to large meshes and images. We compare the PyTorch3D operators and renderer with other implementations and demonstrate significant speed and memory improvements. We also use PyTorch3D to improve the state-of-the-art for unsupervised 3D mesh and point cloud prediction from 2D images on ShapeNet. PyTorch3D is open-source and we hope it will help accelerate research in 3D deep learning.
Invariants of multidimensional time series based on their iterated-integral signature
May 09, 2018
We introduce a novel class of features for multidimensional time series, that are invariant with respect to transformations of the ambient space. The general linear group, the group of rotations and the group of permutations of the axes are considered. The starting point for their construction is Chen's iterated-integral signature.