 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
Paper and Code
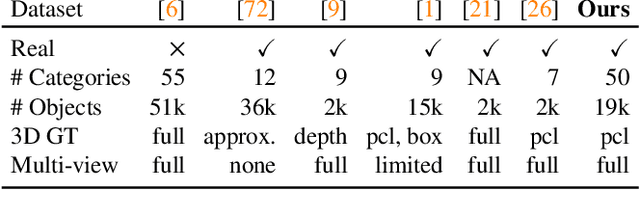
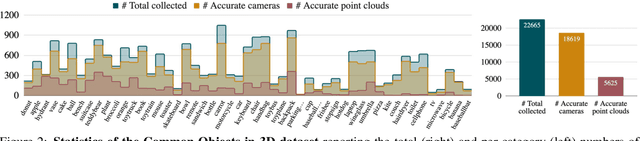
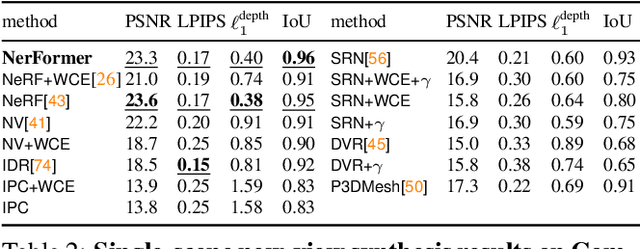
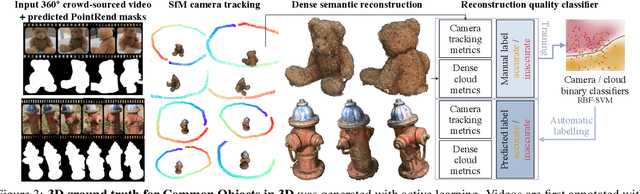
Traditional approaches for learning 3D object categories have been predominantly trained and evaluated on synthetic datasets due to the unavailability of real 3D-annotated category-centric data. Our main goal is to facilitate advances in this field by collecting real-world data in a magnitude similar to the existing synthetic counterparts. The principal contribution of this work is thus a large-scale dataset, called Common Objects in 3D, with real multi-view images of object categories annotated with camera poses and ground truth 3D point clouds. The dataset contains a total of 1.5 million frames from nearly 19,000 videos capturing objects from 50 MS-COCO categories and, as such, it is significantly larger than alternatives both in terms of the number of categories and objects. We exploit this new dataset to conduct one of the first large-scale "in-the-wild" evaluations of several new-view-synthesis and category-centric 3D reconstruction methods. Finally, we contribute NerFormer - a novel neural rendering method that leverages the powerful Transformer to reconstruct an object given a small number of its views. The CO3D dataset is available at https://github.com/facebookresearch/co3d .