 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay: Multi-modal Multi-view Acted Videos for Casual Holography
Jul 22, 2023We introduce Replay, a collection of multi-view, multi-modal videos of humans interacting socially. Each scene is filmed in high production quality, from different viewpoints with several static cameras, as well as wearable action cameras, and recorded with a large array of microphones at different positions in the room. Overall, the dataset contains over 4000 minutes of footage and over 7 million timestamped high-resolution frames annotated with camera poses and partially with foreground masks. The Replay dataset has many potential applications, such as novel-view synthesis, 3D reconstruction, novel-view acoustic synthesis, human body and face analysis, and training generative models. We provide a benchmark for training and evaluating novel-view synthesis, with two scenarios of different difficulty. Finally, we evaluate several baseline state-of-the-art methods on the new benchmark.
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
Apr 02, 2021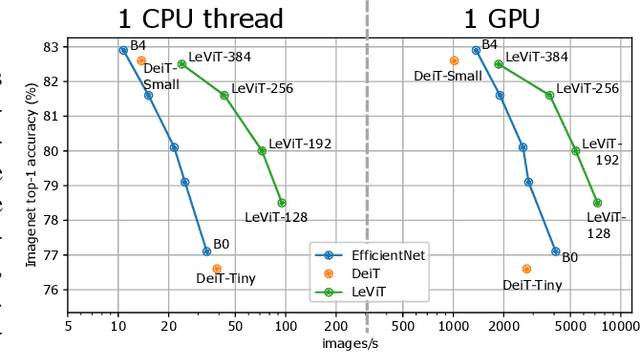
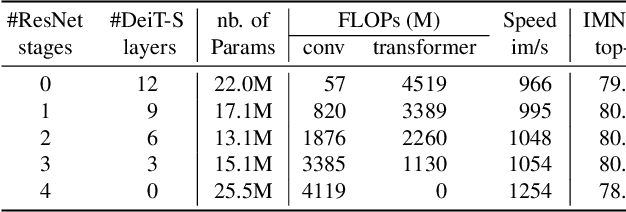

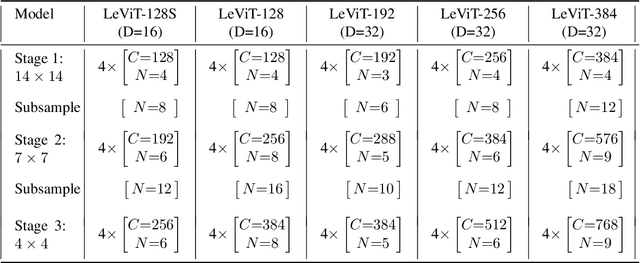
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We re-evaluated principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80\% ImageNet top-1 accuracy, LeViT is 3.3 times faster than EfficientNet on the CPU.
Sparse 3D convolutional neural networks
Aug 25, 2015
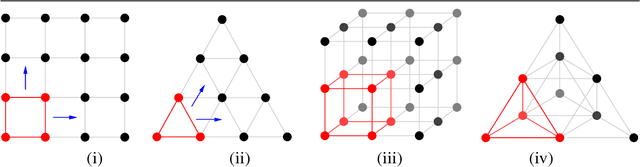
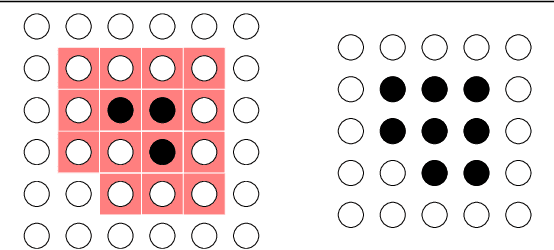

We have implemented a convolutional neural network designed for processing sparse three-dimensional input data. The world we live in is three dimensional so there are a large number of potential applications including 3D object recognition and analysis of space-time objects. In the quest for efficiency, we experiment with CNNs on the 2D triangular-lattice and 3D tetrahedral-lattice.
Efficient batchwise dropout training using submatrices
Feb 09, 2015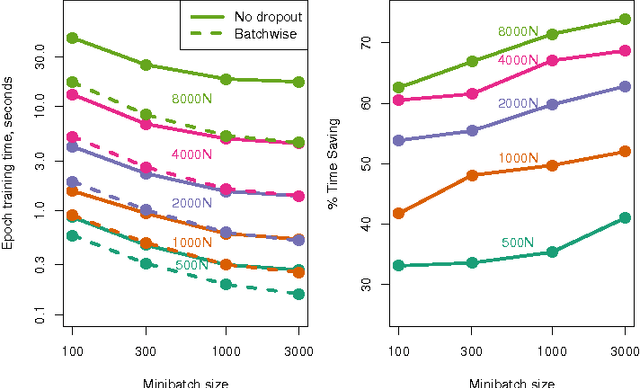
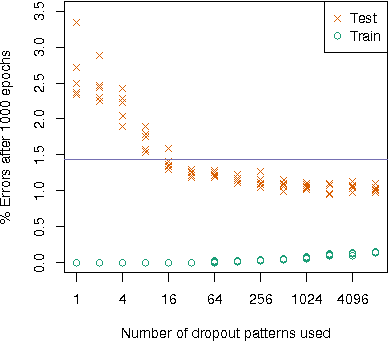
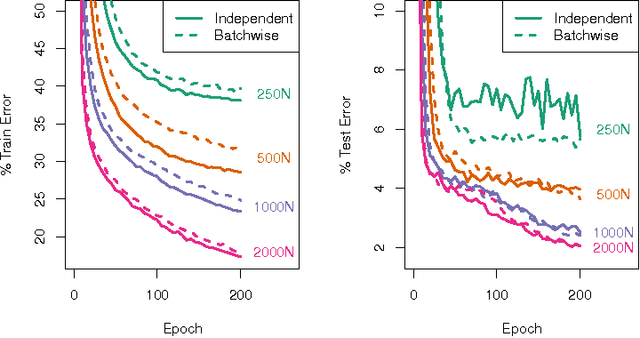
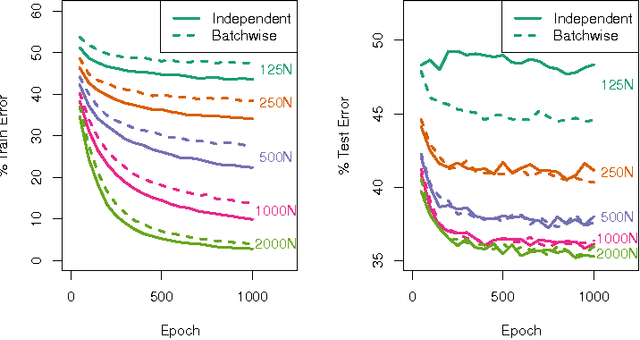
Dropout is a popular technique for regularizing artificial neural networks. Dropout networks are generally trained by minibatch gradient descent with a dropout mask turning off some of the units---a different pattern of dropout is applied to every sample in the minibatch. We explore a very simple alternative to the dropout mask. Instead of masking dropped out units by setting them to zero, we perform matrix multiplication using a submatrix of the weight matrix---unneeded hidden units are never calculated. Performing dropout batchwise, so that one pattern of dropout is used for each sample in a minibatch, we can substantially reduce training times. Batchwise dropout can be used with fully-connected and convolutional neural networks.